

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 26, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
KI-Codierungstools sind heute Teil der täglichen Entwicklung. Entwickler verwenden Produkte wie Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code und Goose, um Code zu generieren, zu refaktorieren, zu debuggen und große Codebasen direkt vom Editor oder Terminal aus zu erklären. Das Problem in den meisten Unternehmen ist nicht die Akzeptanz. Das Problem ist die Unternehmensführung. Jedes Tool kann mit einem oder mehreren Modellanbietern kommunizieren. Jedes Tool speichert Schlüssel häufig lokal. Teams haben schnell Dutzende von ungemanagten Einstiegspunkten zu externen Modellen. Dadurch entsteht ein echtes Risiko in Bezug darauf, welche Modelle genehmigt werden, wohin Code und Kontext gesendet werden, wie Ausgaben zugeordnet werden und wie Vorfälle untersucht werden. Dies erschwert auch die Zuverlässigkeit, da Routing und Fallbacks zwischen den Tools inkonsistent sind.
Wenn Sie versuchen, dies manuell zu lösen, erstellen Sie normalerweise einen internen Proxy, auf den jede IDE und CLI verweist. Dieser Proxy benötigt Authentifizierung, Autorisierung, Genehmigungslisten für genehmigte Modelle, Provider-Routing, Auditprotokolle, Ratenbegrenzung, Budgetkontrollen und Beobachtbarkeit. Er muss auch mit den APIs kompatibel sein, die diese Tools erwarten. Viele Tools sprechen eine OpenAI-kompatible API, aber sie haben auch Macken in Bezug auf die Modellbenennung und spezielle Verhaltensweisen, mit denen Sie umgehen müssen.
Hier ist ein kleines Dummy-Beispiel, das zeigt, warum das zu echter Ingenieurarbeit wird. Es ist noch nicht produktionsbereit. Es soll nur die Form des Problems zeigen.
aus Fastapi importieren FastAPI, Request, HttpException
Importzeit
httpx importieren
app = fastAPI ()
ZUGELASSEN_MODELLE = {
„gpt-4o“: {"anbieter“: „openai“, „target“: „gpt-4o"},
„claude-3-5-sonnet“: {"provider“: „anthropisch“, „target“: „claude-3-5-sonett"},
}
OPENAI_URL = "https://api.openai.com/v1/chat/completions“
ANTHROPISCHE_URL = "https://api.anthropic.com/v1/messages“
def verify_token (auth_header: str) -> dikt:
# In Wirklichkeit ist dies eine JWT-Validierung gegen Okta oder Ihren IdP.
wenn nicht auth_header oder nicht auth_header.startswith („Bearer „):
HttpException auslösen (status_code=401, detail="fehlendes Token“)
return {"user“: „alice“, „team“: „plattform"}
@app .post („/v1/chat/completions“)
async def chat_completions (erforderlich: Anfrage):
user_ctx = verify_token (req.headers.get („Autorisierung“))
body = warte auf req.json ()
modell = body.get („Modell“)
wenn das Modell nicht in APPROVED_MODELS enthalten ist:
HttpException auslösen (status_code=403, detail="Modell nicht genehmigt“)
route = APPROVED_MODELS [Modell]
gestartet = time.time ()
async mit httpx.asyncClient (timeout=60) als Client:
wenn route ["provider"] == „openai“:
upstream = warte auf client.post (
AI_URL ÖFFNEN,
headers= {"Authorization“: „Inhaber" + „UPSTREAM_OPENAI_KEY"},
json= {**body, „model“: Route ["Ziel"]},
)
sonst:
# Sie würden hier auch Anfrage- und Antworttransformationen benötigen.
upstream = warte auf client.post (
ANTHROPISCHE_URL,
headers= {"x-api-key“: „UPSTREAM_ANTHROPIC_KEY"},
json= {"model“: route ["target"], „messages“: body.get („nachrichten“, [])},
)
latency_ms = int ((time.time () - gestartet) * 1000)
# In Wirklichkeit würden Sie hier OpenTelemetry-Traces und strukturierte Logs ausgeben.
print („llm_request“, {"user“: user_ctx ["user"], „model“: model, „latency_ms“: latency_ms})
gib upstream.json () zurück
Auch in dieser vereinfachten Version sieht man fehlende Teile. Sie benötigen weiterhin robuste, anbieterübergreifende Transformationen, Streaming-Unterstützung, Wiederholungsversuche, Fallbacks, Safe-Pass-Through-Header, Mandanten- und Teamumfang sowie dauerhafte Auditprotokolle. Sie benötigen außerdem ein Konfigurationssystem, das teamübergreifend skaliert werden kann.
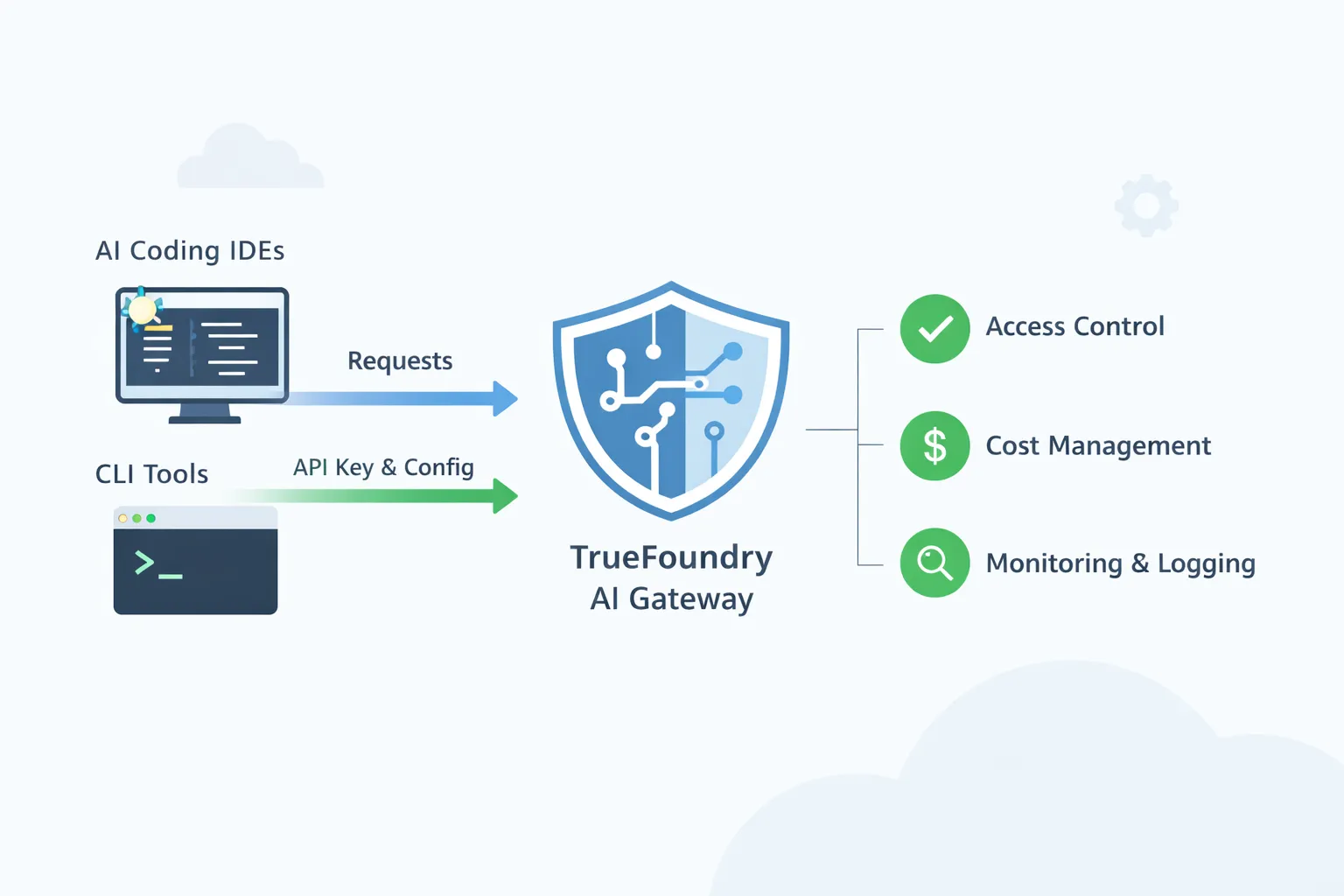
TrueFoundry AI Gateway wurde als gemeinsamer Kontrollpunkt konzipiert. IDEs und CLIs verwenden weiterhin die Workflows, die Entwicklern bereits gefallen, aber der Datenverkehr wird über ein einziges kontrolliertes Gateway geleitet. Das Gateway wird zum Ort, an dem Plattformteams den genehmigten Modellzugriff durchsetzen, Richtlinien anwenden und einen vollständigen Überblick über die Nutzung erhalten.
Ein Kernthema in den IDE-Handbüchern ist einfach. Sie rufen die Basis-URL und den Modellnamen vom TrueFoundry AI Gateway-Spielplatz ab. Dann konfigurieren Sie die IDE oder CLI so, dass sie diese Basis-URL und ein TrueFoundry-Token verwendet.
Die meisten KI-Codierungs-IDEs und Desktop-Tools können auf einen einzigen OpenAI-kompatiblen Endpunkt verweisen. Das TrueFoundry AI Gateway bietet Ihnen diesen Endpunkt. Sie beginnen im Gateway-Spielplatz und kopieren das vereinheitlichte Snippet. Dieses Snippet gibt Ihnen die Basis-URL und den Modellnamen, den Sie verwenden sollten. Anschließend öffnen Sie die IDE-Einstellungen und wählen eine Anbieteroption aus, die eine benutzerdefinierte Basis-URL unterstützt. Viele Tools bezeichnen dies als OpenAI-kompatibel. Sie fügen die Gateway-Basis-URL ein. Sie fügen ein TrueFoundry-Token als API-Schlüssel ein. Das Token kann ein persönliches Token für einen Entwickler oder ein virtuelles Kontotoken für die gemeinsame oder automatisierte Nutzung sein. TrueFoundry dokumentiert beide Optionen und empfiehlt das virtuelle Kontotoken für die Verwendung im Produktionsstil. Lesen Sie hier mehr
Einige IDEs funktionieren am besten, wenn sie kurze Standardmodellnamen wie gpt 4o sehen. TrueFoundry-Modellnamen sind oft vollständig qualifiziert. Die empfohlene Lösung besteht darin, eine Routing- oder Load-Balancing-Regel im Gateway zu definieren, sodass die IDE den Kurznamen weiterhin verwendet, während das Gateway ihn dem vollständig qualifizierten Zielmodell zuordnet. Cursor und Codex dokumentieren beide dieses Muster, da sie eine interne Logik haben, die an Standardmodellnamen gebunden ist. Cursor-Dokumente
Es kann auch Netzwerkeinschränkungen geben. Cursor dokumentiert, dass sein Anforderungsfluss Cursor-Server einbeziehen kann. Das bedeutet, dass die Gateway-URL von der Cursor-Infrastruktur aus erreichbar sein muss. In der Praxis muss der Gateway-Endpunkt öffentlich erreichbar sein, damit der Cursor wie in der Anleitung beschrieben funktioniert.
CLI-Tools lassen sich normalerweise über Umgebungsvariablen oder eine lokale Konfigurationsdatei integrieren. Für OpenAI-kompatible CLIs besteht das übliche Muster darin, OPENAI_BASE_URL auf den TrueFoundry Gateway-Endpunkt und OPENAI_API_KEY auf ein TrueFoundry-Token zu setzen. TrueFoundry dokumentiert dies als unterstützten Authentifizierungsansatz für das Gateway. Lesen Sie mehr: Authentifizierung
Einige CLIs verwenden anbieterspezifische Variablen. Gemini CLI verwendet eine Gemini-Basis-URL und einen Gemini-API-Schlüssel. Die TrueFoundry-Anleitung zeigt, wie Sie GOOGLE_GEMINI_BASE_URL auf eine TrueFoundry Gemini-Proxy-URL und GEMINI_API_KEY auf ein TrueFoundry-Token setzen, sodass jede Anfrage das Gateway durchläuft. Lesen Sie mehr: Gemini-CLI
Andere CLIs basieren auf einer JSON-Einstellungsdatei. Claude Code wird über eine settings.json-Datei konfiguriert, die Umgebungswerte für die Basis-URL und die Auth-Header festlegt. Die TrueFoundry-Anleitung zeigt, dass ANTHROPIC_BASE_URL auf das Gateway zeigt und ein Bearer-Token in benutzerdefinierten Headern verwendet, sodass der Claude Code-Verkehr über das Gateway geleitet wird. Lesen Sie mehr: Claude-Code
Einige Tools benötigen auch die zuvor erwähnte Standardnamenszuordnung. In der Codex-CLI-Anleitung wird erklärt, dass Codex Standardmodellnamen erwartet und sich bei vollständig qualifizierten Namen falsch verhalten kann. Es wird empfohlen, Gateway-Routing zu verwenden, sodass Sie gpt 5 in der CLI aufrufen, während das Gateway hinter den Kulissen zum richtigen, vollständig qualifizierten Modell weiterleitet. Lesen Sie mehr: Codex
Modellgenehmigung und Zugriffskontrolle sind die grundlegendsten Governance-Anforderungen, wenn KI-Codierungstools in einem Unternehmen eingesetzt werden. Ein Entwickler kann Cursor oder Cline innerhalb von Minuten installieren und es an einen beliebigen Modellanbieter weiterleiten. Ohne ein Gateway hat das Unternehmen am Ende viele unverwaltete Pfade, über die Codekontext und Eingabeaufforderungen das Netzwerk mithilfe persönlicher Schlüssel verlassen können. Mit TrueFoundry AI Gateway erstellen Sie einen kleinen, genehmigten Katalog von Modellen, die zum Programmieren verwendet werden dürfen, und ordnen diese Modelle Teams oder Benutzergruppen zu. Entwickler verwenden weiterhin dieselbe IDE, die sie bevorzugen, aber jede Anfrage durchläuft das Gateway, sodass eine Anfrage an ein nicht genehmigtes Modell blockiert wird. Dadurch ist es auch möglich, den Zugriff nach Risikostufen zu trennen. Ein Nachwuchsingenieur erhält möglicherweise Zugriff auf ein günstigeres Modell für schnelle Änderungen, während ein angestellter Ingenieur oder ein Produktionsteam auf ein leistungsfähigeres Modell für schwieriges Debugging zugreifen können. Der wichtige Teil ist, dass die Genehmigung zentral durchgesetzt wird und man sich nicht darauf verlassen muss, dass sich jeder Entwickler an ein Richtliniendokument hält.
Kostenverantwortung wird wichtig, da KI-Codierungstools große Mengen an Tokens generieren können, ohne dass es jemand bemerkt. Ein einzelner Entwickler, der einen Agenten verwendet, der auf einer Codebasis iteriert, kann in einem kurzen Fenster Hunderte oder Tausende von Aufrufen erstellen. Ohne ein Gateway verteilen sich die Ausgaben auf persönliche Schlüssel und Lieferantenkonten, sodass die Finanzabteilung zwar eine Rechnung sieht, aber nicht sehen kann, welches Team oder welche Anwendung sie veranlasst hat. Mit einem Gateway können Sie identitätsbasierte Token ausstellen und bei jeder IDE- oder CLI-Sitzung eine Authentifizierung mithilfe einer Benutzer- oder Dienstidentität vorschreiben. Auf diese Weise können Sie die Nutzung einer Person, einem Team oder einem internen Tool zuordnen. Sobald die Zuordnung erfolgt ist, werden Kontrollen praktisch. Sie können Budgets für ein Team für einen Monat festlegen und Sie können Ratenlimits festlegen, um versehentliche Ausreißerschleifen zu verhindern. Wenn ein Tool anfängt, Anfragen zu spammen, kann das Gateway dies drosseln, anstatt es unbemerkt das Budget durchbrennen zu lassen.
Bei der Reaktion auf Vorfälle und Audits spüren Plattformteams den Unterschied von Tag zu Tag. Wenn ein Entwickler sagt, dass der Assistent langsam ist oder ausfällt, ist das Debuggen schwierig, wenn der Datenverkehr direkt von einem Laptop zu einem Anbieter geleitet wird. Möglicherweise wissen Sie nicht, ob das Problem am Anbieter, am Netzwerk, an einem falsch konfigurierten Modellnamen oder an einer werkzeugspezifischen Einstellung liegt. Wenn Anfragen über das Gateway eingehen, kann das Plattformteam anhand der Gateway-Metriken und -Protokolle feststellen, welches Modell aufgerufen wurde, wie die Latenz aussah, welche Fehler aufgetreten sind und ob Ausfälle auf einen Anbieter oder eine Region beschränkt sind. Dies ist auch die Grundlage für die Prüfanforderungen. Sicherheits- und Compliance-Teams fragen häufig, wohin der Codekontext gesendet wurde und wer Zugriff darauf hatte. Ein Gateway kann aufzeichnen, welche Ziele verwendet wurden und wer sie aufgerufen hat. Es kann auch Richtlinien zur Risikominderung unterstützen, z. B. das Maskieren vertraulicher Zeichenketten, bevor Anfragen externe Anbieter erreichen, oder das Versenden von Aufforderungen an externe Endgeräte durch bestimmte Teams.
Zuverlässigkeit bei Problemen mit Anbietern ist wichtig, da es bei Modellanbietern zu regelmäßigen Verlangsamungen und Timeouts kommt. KI-Codierungstools sind besonders empfindlich, da sie interaktiv sind. Ein paar Timeouts können dazu führen, dass sich das Tool kaputt anfühlt und Entwickler zu dem wechseln, was funktioniert. Viele IDEs gehen auch von bestimmten Modellnamen aus. Cursor und ähnliche Tools funktionieren oft am besten, wenn der Modellname wie ein Standardname im OpenAI-Stil aussieht. Wenn Sie den Anbieter wechseln, müssten Sie normalerweise jede Entwicklerkonfiguration ändern. Beim Gateway-Routing können Sie den gleichen Modellnamen in den IDE-Einstellungen beibehalten und die Zuordnung im Hintergrund ändern. Wenn bei einem Anbieter ein Timeout auftritt, können Sie die Route zu einem anderen Anbieter oder zu einem anderen Konto oder einer anderen Region weiterleiten. Der Entwickler verwendet weiterhin dieselbe IDE-Konfiguration und sieht einfach, dass das Tool weiterhin funktioniert. Dies ist auch nützlich, wenn Sie ein neues Modell einführen möchten. Sie können den Traffic schrittweise auf das neue Modell umstellen und gleichzeitig die Benutzererfahrung stabil halten. Außerdem können Sie schnell ein Rollback durchführen, wenn Qualität oder Latenz nicht akzeptabel sind.
KI-Codierungs-IDEs machen Entwickler schneller. Unternehmen benötigen das gleiche Maß an Governance, das sie bereits für Quellcodeverwaltungs- und CI-Systeme anwenden. Der praktische Weg besteht darin, die Steuerung zu zentralisieren, ohne die Entwickler zu zwingen, die Tools zu wechseln. TrueFoundry AI Gateway ist so konzipiert, dass es sich an diesem Kontrollpunkt befindet. Die Integrationsleitfäden für Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code und Goose folgen alle demselben Prinzip. Behalten Sie den Entwickler-Workflow bei. Zentralisieren Sie Richtlinien, Transparenz und Kontrolle am Gateway.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




