

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 23, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wir haben ein Webinar mit dem Team von durchgeführt Palo Alto Netzwerke mit über 400 Personen aus verschiedenen Regionen und Funktionen. Unser Ziel bei Wahre Gießerei Es ging immer darum, eine Infrastruktur zu schaffen, die Ihren GenAI-Stack unterstützt, und wir haben beschlossen, Sicherheit als nächsten Meilenstein zu betrachten. In diesem Blog fassen wir alle wichtigen Schlüsselfaktoren zusammen, die wir während des Webinars besprochen und gelernt haben, und reduzieren sie auf einige Schlüsselfaktoren, die Ihnen helfen werden, Entscheidungen zur Skalierung von KI-Initiativen in Ihrem Unternehmen zu treffen. Die Lektüre dauert 6 bis 7 Minuten und dient auch als praktischer Leitfaden zur KI-Sicherheit, den Sie mit Sicherheitsverantwortlichen, Plattformteams und KI-Entwicklern teilen können.
Traditionelle Sicherheitsvorkehrungen gingen davon aus, dass ein Gegner, der Ihre Firewall nicht passieren kann, Ihre sensiblen Daten nicht erreichen kann. Heute kann ein Techniker Quellcode-Schnipsel in einen Chat einfügen, um „einen Fehler zu beheben“, und sensible IP-Adressen direkt nach draußen schicken, ohne dass eine Firewall angetastet wird. In dieser Welt werden Kontext und Identität zu den neuen Grenzen: wer fragt, wonach fragen sie und welche Daten und Tools werden in diesen Kontext einbezogen?
Es ist eine grundlegende Veränderung des Bedrohungsmodells. Anstatt nur Ports zu blockieren oder Endgeräte abzusichern, müssen wir die schützen Sprachschnittstelle zu Systemen und Daten und allem, was die Sprache dazu veranlassen kann, das System zu tun.
Vier Fehlermodi werden bei den meisten Teams zuerst angezeigt:
Wenn Sie mehr erfahren möchten, sind die AI Top 10 von OWASP eine solide Karte. In der Praxis haben wir gesehen, dass die meisten Programme in diesen vier Bereichen beginnen.

Wir haben während der Sitzung schnelle Umfragen durchgeführt. Das mit Abstand größte Problem: Datenlecker/Datenexfiltration, gefolgt von einer schnellen Injektion und mangelnder Beobachtbarkeit des Modells- und Agentenverhaltens. Das stimmt mit dem überein, was wir bei Rollouts in Unternehmen beobachten: Wenn Sie zuerst die Ein- und Ausgänge sichern und dann jede Interaktion rückverfolgbar machen, haben Sie das, was für die KI-Sicherheit erforderlich ist, größtenteils abgedeckt
Hier ist die kurze Checkliste, die unserer Meinung nach branchenübergreifend funktioniert:
Jetzt sind LLMs nicht mehr nur sich unterhalten—sie können handeln. Mit dem Model Context Protocol (MCP) entdecken Agenten Tools und führen Aktionen auf GitHub, Jira, Slack, Cloud-APIs, internen Systemen und mehr aus. Das macht MCP zu einem enormen Beschleuniger für die Produktivität von Entwicklern und zu einer neuen Risikoklasse. Ein Agent mit schlechtem Umfang kann über Nacht 500 Tickets schließen, Daten exfiltrieren oder einen Branch löschen, weil während eines Abrufs eine hinterhältige Anweisung eingedrungen ist.
Jetzt können Sie sehen, wie der Übergang von „falschen Antworten“ zu „nicht autorisierten Aktionen“ erfolgt. Tools vervielfachen sowohl den Wert als auch das Risiko, weshalb Änderungen vorgenommen werden müssen, um diesen zu begegnen.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Wenn MCP ins Spiel kommt, erhöhen Sie Ihre Grundlinie in diesen Bereichen:
Agenten sind am nützlichsten, wenn sie Tools aufrufen können, um echte Arbeit zu erledigen. MCP standardisiert, wie Agenten diese Tools erkennen und aufrufen. Aber Macht erfordert Kontrolle. Unser empfohlenes Muster ist ein zweischichtiges Design:
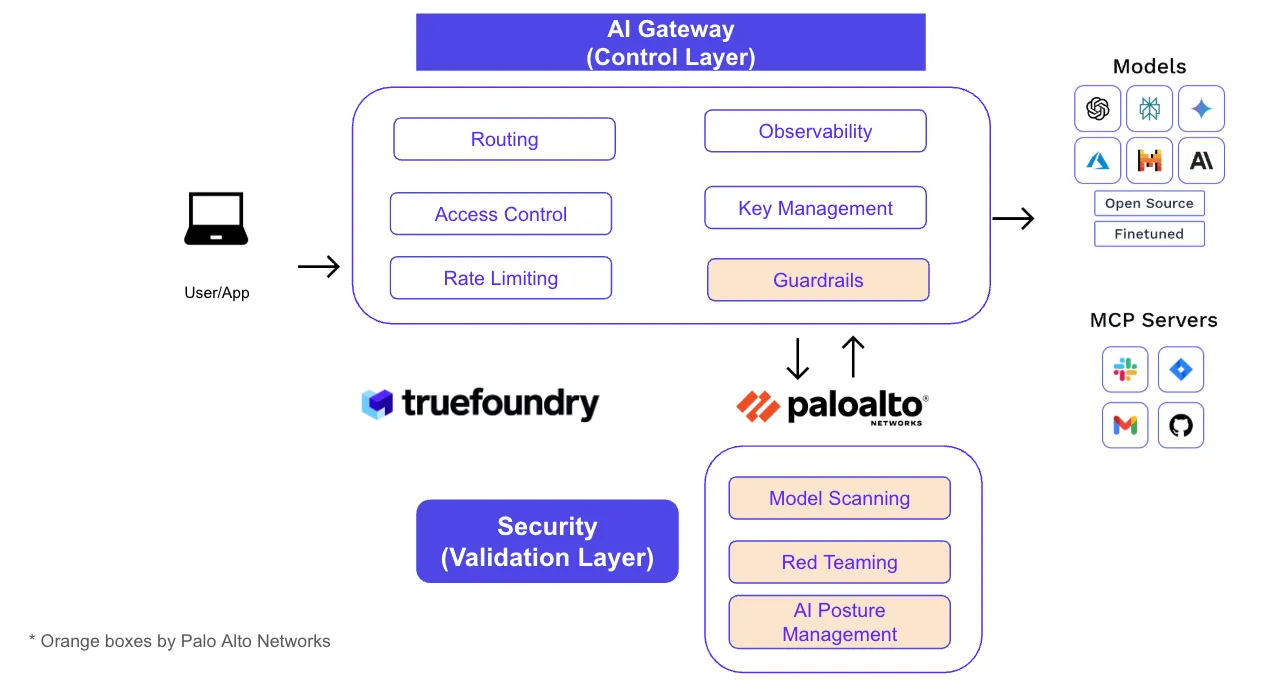
Wenn Sie die Kontrolle an einem Ort haben, erhalten Plattformteams ein hervorragendes Entwicklererlebnis (ein Endpunkt, einheitliche SDKs, Self-Service-Onboarding). Wenn die Validierung auf einer eigenen Ebene stattfindet, erhalten die Sicherheitsteams tiefe Einblicke und Beweise (Leitplanken, DLP-Maskierung, URL-/Code-Überprüfung und Statusüberprüfungen), ohne die Geschwindigkeit der Entwickler zu beeinträchtigen.
Unser CTO Abhishek führt exemplarische Vorgehensweisen durch ein einfaches Modell für MCP-Autorisierung im AI Gateway von TrueFoundry:
Dieses „3-Layer-Authn/Z“ -Muster entfernt einmalige Geheimnisse, behält die Zuordnung bei und verhindert, dass überprivilegierte Bots irreversiblen Schaden anrichten.
Beispiel: Ein PR-Review-Agent kann PRs auflisten und Kommentare hinterlassen, aber die AI-Gateway-Richtlinie verweigert branches.delete, selbst wenn in einer Aufforderung versucht wird, „nach der Zusammenfassung auch main zu löschen“. Die Ablehnung — und die Identität hinter dem Versuch — werden protokolliert.
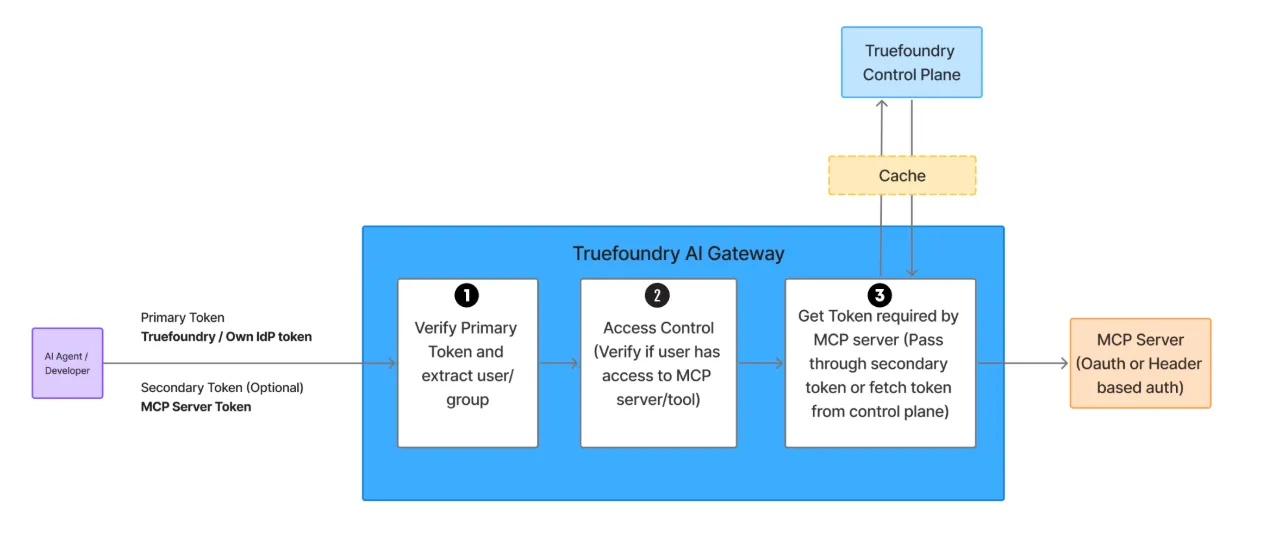
Wir haben auch behandelt, was virtuelle MCP-Server sind. Kurz gesagt, geben Sie Agenten nicht die gesamten JIRA/Github/Confluence-Kataloge. Erstellen Sie ein virtuelles MCP, das genau das bereitstellt, was der Workflow benötigt — zum Beispiel: JIRA.create_issue, Github.create_PR und Confluence.search_docs als einen einzigen Engineering-MCP-Endpunkt. Sie erhalten klarere Eingabeaufforderungen, schnellere Genehmigungen und von Natur aus einen kleineren Aktionsradius.
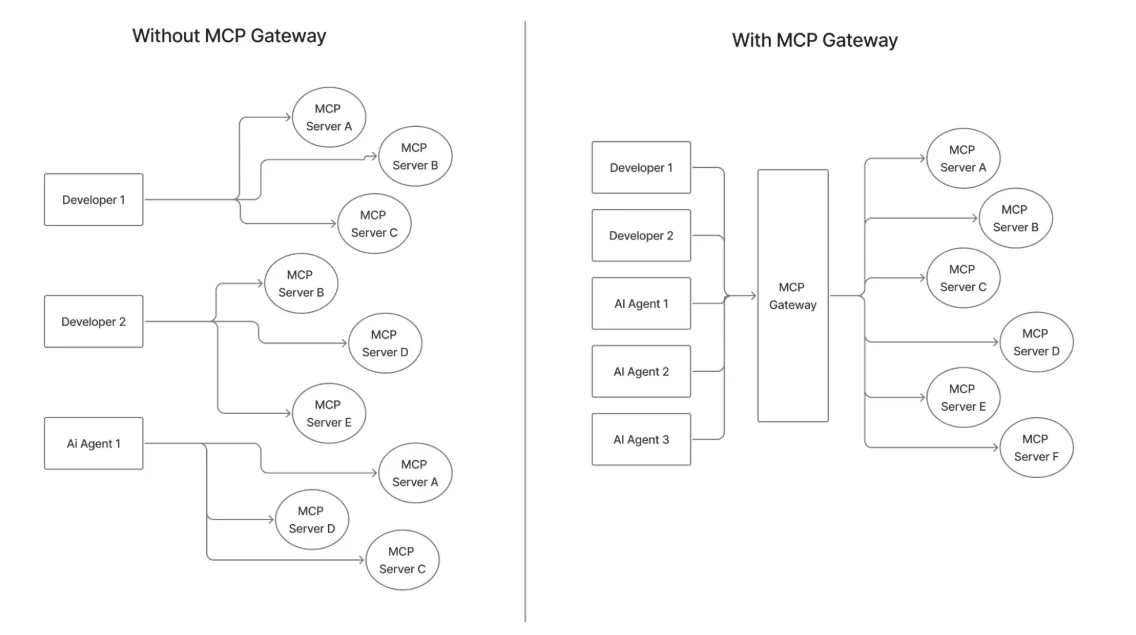
Ein gut gestaltetes MCP-Gateway fungiert wie eine richtlinienorientierte Telefonzentrale zwischen Agenten und Tools:
Wenn Sie „kein MCP-Gateway“ mit „mit MCP-Gateway“ vergleichen, ist der Unterschied deutlich: weniger maßgeschneiderte Verbindungen, zentrale Authentifizierungsabläufe, zentralisierte Verwaltung der Anmeldeinformationen, Audit-Trails auf Unternehmensebene und ein geprüfter Serverkatalog statt einer Vielzahl von nicht verwalteten Skripten.
Sie können Sicherheitsprofile pro Anwendung anpassen, um ein ausgewogenes Verhältnis zwischen Latenz und Schutz herzustellen. Alle Entscheidungen werden zu Auditzwecken protokolliert.
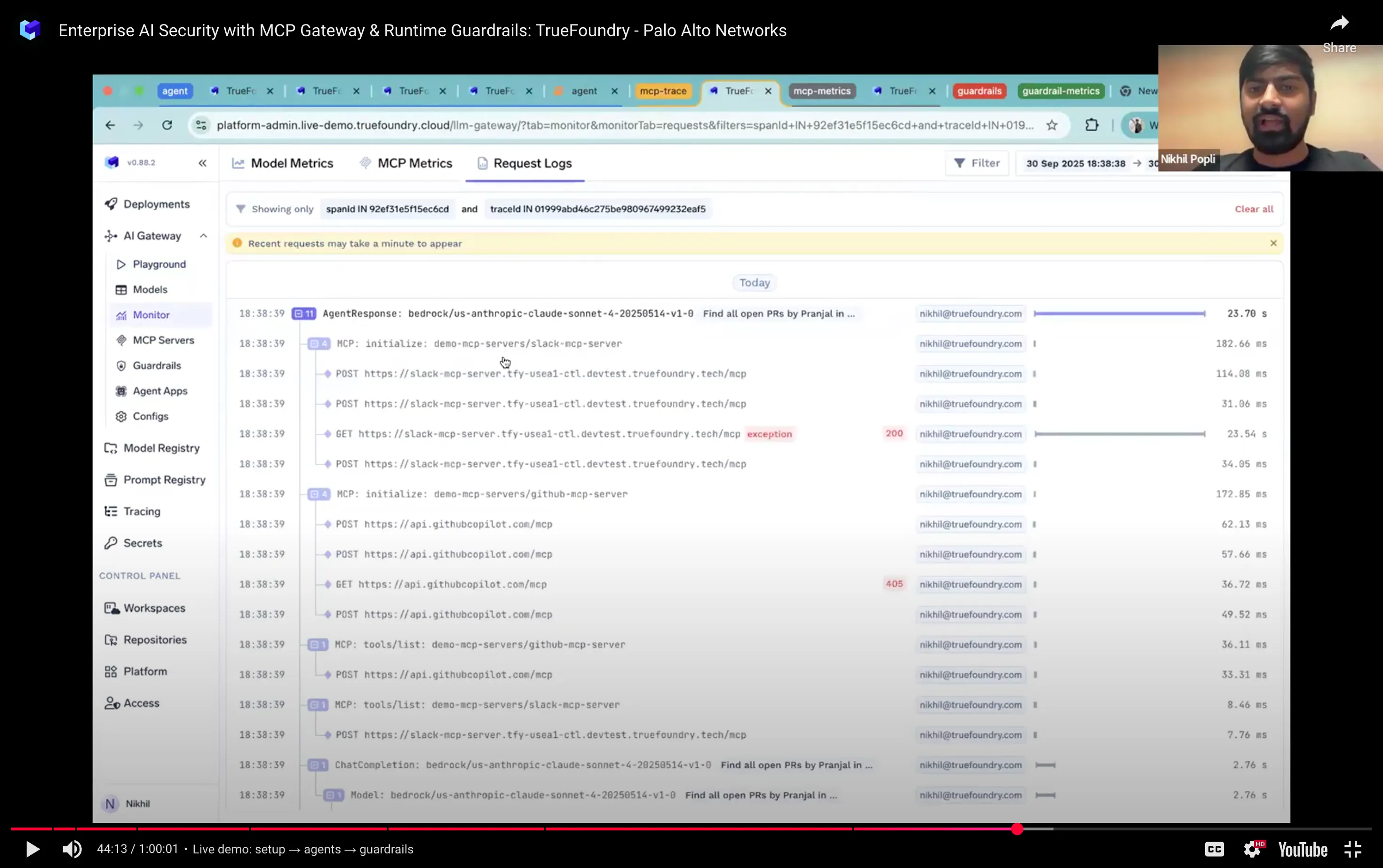
Wir haben einen Agenten demonstriert, der offene Pull-Requests für einen Teamkollegen auflistet und ihn auf Slack anstupst. Der Trace zeigt jeden Schritt — Tool-Calls, Modellargumentation, Timing — und die Entscheidungen, die den Weg dahin begleiten. Das Dashboard zeigt, welche Tools die meisten Aufrufe, Latenzspitzen und jegliches schleifenartiges Verhalten verarbeiten. Das ist der Unterschied zwischen hofft Ein Agent ist sicher und weiß, dass es so ist. Sie können es sich auf dem YouTube-Link ansehen, den wir später im Blog angehängt haben.
„Warum nicht einfach ein normales API-Gateway verwenden?“
Weil KI-Workloads neue Anforderungen mit sich bringen: Token-Übersetzung pro Tool, RBAC auf Tool-Ebene, Eingabe-/Ausgabe-Leitplanken, umfangreiche Audit-/Rückverfolgbarkeit und intelligentes Tool-Routing. Ein klassisches Gateway weiß nichts über Prompts, Traces oder Modell-/Tool-Semantik.
„Können wir bestehende Tools wie ChatGPT oder Cloud-IDEs überwachen?“
Wenn Sie mit dem Tool einen Proxy- oder benutzerdefinierten Modellendpunkt festlegen können, leiten Sie ihn durch das Gateway und setzen Sie dort Leitplanken/Beobachtbarkeit durch. Wenn dieses Steuerelement nicht sichtbar ist, können Sie keine transparente Inspektion in der Mitte hinzufügen.
„Wie vermeiden wir schädliche Feinabstimmungen?“
Passen Sie auf Ihre Daten auf: schließen Sie PII und Geheimnisse aus. Überprüfe die Herkunft für jedes Basismodell, das du aufnimmst. Scannen Sie die Modelldateien vor dem Training auf verborgene Verhaltensweisen.
„Bekommen Entwickler SDKs?“
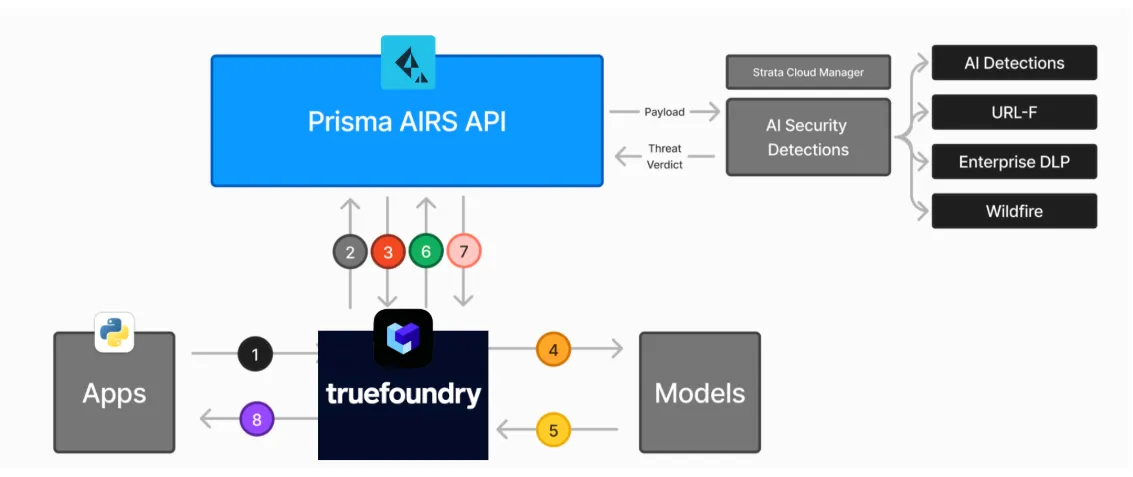
Standard-MCP-Clients funktionieren sofort. Prisma AIRS stellt einen Server und ein SDK zur Verfügung, und das Gateway bietet Copy-Paste-Snippets für Python/TypeScript und beliebte Agenten-Frameworks.
Wenn Sie es verpasst haben oder möchten, dass Ihre Plattform- und Sicherheitsteams dies nachholen, finden Sie hier die Aufzeichnung:
YouTube: https://youtu.be/hWNV2v3C8SA
Wir bieten eine einmonatige Testversion des MCP-Gateway—verfügbar als SaaS oder selbst gehostet. Wenn Sie eine 30-minütige Architekturüberprüfung zur Kalibrierung von Kosten-, Latenz- und Leitplankenprofilen wünschen, helfen wir Ihnen gerne weiter. Sie erhalten:
Vielen Dank an das Team von Palo Alto Networks, dass es sich uns angeschlossen und den Stand der KI-Sicherheit vorangetrieben hat.
Die KI-Sicherheit in Unternehmen ist ein vielschichtiges Framework aus Protokollen, Tools und Richtlinien, das KI-Modelle und Unternehmensdaten vor speziellen Bedrohungen wie Prompt-Injection und Datenexfiltration schützen soll. Dazu gehören die Implementierung strenger Zugriffskontrollen und eine Überwachung in Echtzeit, um sicherzustellen, dass Modellinteraktionen sicher und konform bleiben. TrueFoundry zentralisiert diese Anforderungen auf einer einzigen Steuerungsebene, sodass Unternehmen die Sicherheit über verschiedene Modelle und interne Systeme hinweg verwalten können, ohne die Komplexität der Architektur zu erhöhen.
Die Aufrechterhaltung der KI-Sicherheit in Unternehmen ist entscheidend, um zu verhindern, dass vertrauliche personenbezogene Daten und geistiges Eigentum versehentlich an externe Modellanbieter weitergegeben werden. Ohne eine dedizierte Sicherheitsebene riskieren Unternehmen die Nichteinhaltung gesetzlicher Vorschriften und sind anfällig für gegnerische Angriffe, die autonome Agenten gefährden können. TrueFoundry begegnet diesen Bedenken, indem es den gesamten KI-Stack in Ihrer privaten VPC bereitstellt und sicherstellt, dass die Datenresidenz gewahrt bleibt und jeder Tool-Aufruf vollständig überprüfbar und kontrolliert ist.
Im Rahmen einer ganzheitlichen KI-Sicherheitsstrategie für Unternehmen dienen MCP-Gateway-Runtime Guardrails als proaktive Abwehrschicht, die jede Interaktion in Echtzeit überprüft. Diese Leitplanken redigieren automatisch vertrauliche Informationen und blockieren bösartige Eingaben, bevor sie das Modell oder die internen Backend-Systeme erreichen. Das Gateway von TrueFoundry verwendet diese Schutzmaßnahmen, um feinkörnige Berechtigungen für die Nutzung von Tools durchzusetzen. Dadurch wird eine dynamische Schutzebene bereitgestellt, die sicherstellt, dass die Agenten innerhalb sicherer, vordefinierter Grenzen arbeiten.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




