

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wenn Sie jemals an einem Meeting mit Ihrem InfoSec- oder Rechtsteam über eine globale ML-Implementierung teilgenommen haben, kennen Sie den genauen Moment, in dem sich die Stimmung ändert. Es ist, wenn jemand fragt: „Moment, wo befinden sich eigentlich die Inferenzprotokolle für die deutschen Kunden?“
Die Datenresidenz war früher ein Datenbankproblem. Jetzt, mit ML-Pipelines, die Schulung, Bereitstellung, Überwachung und Feature-Stores umfassen, ist das ein riesiges Durcheinander in Ihrem gesamten Infrastruktur-Stack. DSGVO, CCPA, Gesetze zur Datensouveränität in ganz Asien — das sind keine Vorschläge. Wenn Sie etwas falsch machen, bedeutet das hohe Bußgelder oder, schlimmer noch, die Notwendigkeit, eine aktive Bereitstellung abzubrechen.
Wir haben TrueFoundry verwendet, um unsere ML-Infrastruktur zu verwalten, und ehrlich gesagt ist ihr Ansatz zur Datenresidenz einer der Hauptgründe, warum wir bei ihnen geblieben sind. Es verändert grundlegend die Art und Weise, wie wir darüber nachdenken, wo Daten gespeichert sind und wo sie verwaltet werden.
Hier erfahren Sie, wie es in der Praxis funktioniert und warum es sich anders anfühlt als typische SaaS-MLOps-Plattformen.
Das größte Problem bei vielen verwalteten MLOps-Plattformen besteht darin, dass Sie Ihre Daten (Modellartefakte, Trainingsschnipsel, Protokolle) häufig in ihre Cloud senden müssen, um den Komfort ihrer Tools nutzen zu können. Das ist für stark regulierte Branchen ein Kinderspiel.
TrueFoundry funktioniert anders. Sie verwenden eine strikte Trennung zwischen Kontrollebene (ihre SaaS-Verwaltungsschnittstelle) und die Datenebene (Ihre Cloud-Konten).
Stellen Sie sich das so vor: TrueFoundry ist der Fluglotse. Sie sagen den Flugzeugen, wohin sie fliegen und wann sie landen sollen. Aber Ihnen gehören der Flughafen, die Hangars und die Flugzeuge selbst. TrueFoundry besitzt nie wirklich die Fracht im Flugzeug.
Wenn Sie einen Kubernetes-Cluster (EKS, GKE, AKS) mit TrueFoundry verbinden, installieren Sie im Wesentlichen einen Agenten. Dieser Agent bittet die TrueFoundry Control Plane um Anweisungen, aber die gesamte eigentliche Datenverarbeitung und -speicherung findet innerhalb Ihres vordefinierten Netzwerkperimeters statt.
Hier ist ein allgemeiner Überblick über diese Beziehung.
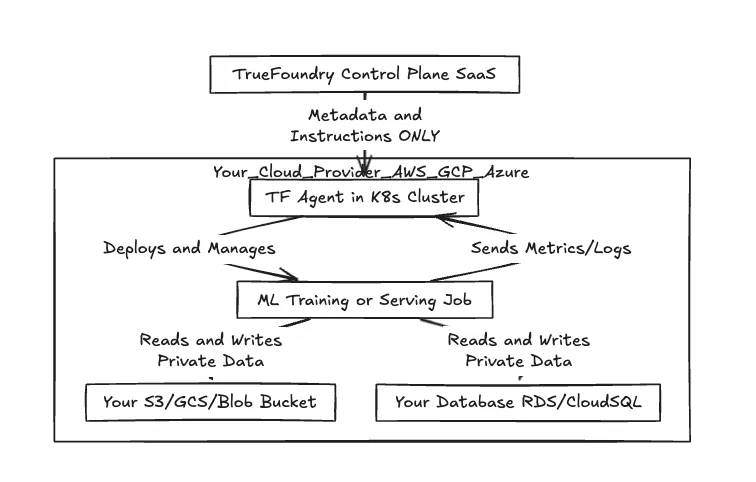
Abb. 1: Arbeitsablauf zwischen der Steuerungsebene und der Datenebene
Wie oben gezeigt, bleiben die „schwere Arbeit“ und die eigentliche Daten-I/O vollständig innerhalb der Grenzen Ihrer Cloud-Umgebung. Das einzige, was die Leitung zurück zu TrueFoundry führt, sind Metadaten — Auftragsstatus, Kennzahlen zur Ressourcenauslastung und Konfigurationsspezifikationen.
Wie lässt sich das auf eine reale Situation übertragen, in der Sie ein Team in der EU haben, das rechtlich nicht zulassen kann, dass seine Kundendaten US-Boden berühren?
TrueFoundry verwendet ein Konzept namens „Workspaces“. Ein Workspace ist eine logische Gruppierung von Ressourcen, die an einen bestimmten zugrunde liegenden Rechencluster und eine Artefaktspeicherintegration gebunden ist.
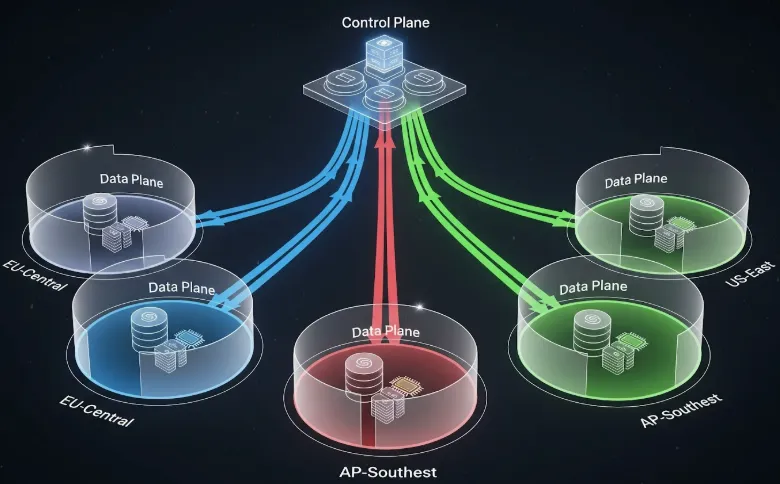
Um den Wohnsitz durchzusetzen, richten wir unterschiedliche Cluster in unseren erforderlichen geografischen Regionen ein.
Wir wiederholen den Vorgang für us-east-1 mit einem „US-Prod“ -Workspace.
Wenn ein EU-Datenwissenschaftler ein Modell bereitstellen möchte, erhält er nur Zugriff auf den Arbeitsbereich „EU-Prod“. Wenn sie einen Trainingsjob auslösen oder einen Dienst bereitstellen, stellt die Steuerungsebene von TrueFoundry sicher, dass die Berechnung auf dem Frankfurter Cluster erfolgt und die resultierenden Modellgewichte im Frankfurter S3-Bucket gespeichert werden. Die Plattform kann die Daten physisch nicht irgendwo anders platzieren, da dieser Workspace nicht weiß, dass eine andere Infrastruktur existiert.
Im Folgenden wird verglichen, wie Daten in einem typischen verwalteten ML-SaaS mit dieser Architektur behandelt werden.
Tabelle 1: Dies ist der Vergleich der Datenverarbeitungsmodelle
In einer ausgereiften Organisation haben Sie am Ende ein Hub-and-Spoke-Modell. Sie verfügen über eine zentrale TrueFoundry-Steuerungsebene, die Ihrem Plattform-Engineering-Team eine zentrale Glasscheibe für eine einfache Verwaltung bietet, aber die eigentliche Ausführung ist geografisch aufgeteilt.
Diese Isolierung ist entscheidend. Das bedeutet, dass selbst wenn ein Entwickler versehentlich versucht, einen Job falsch zu konfigurieren, die Infrastrukturbeschränkungen Datenlecks zwischen Regionen verhindern.
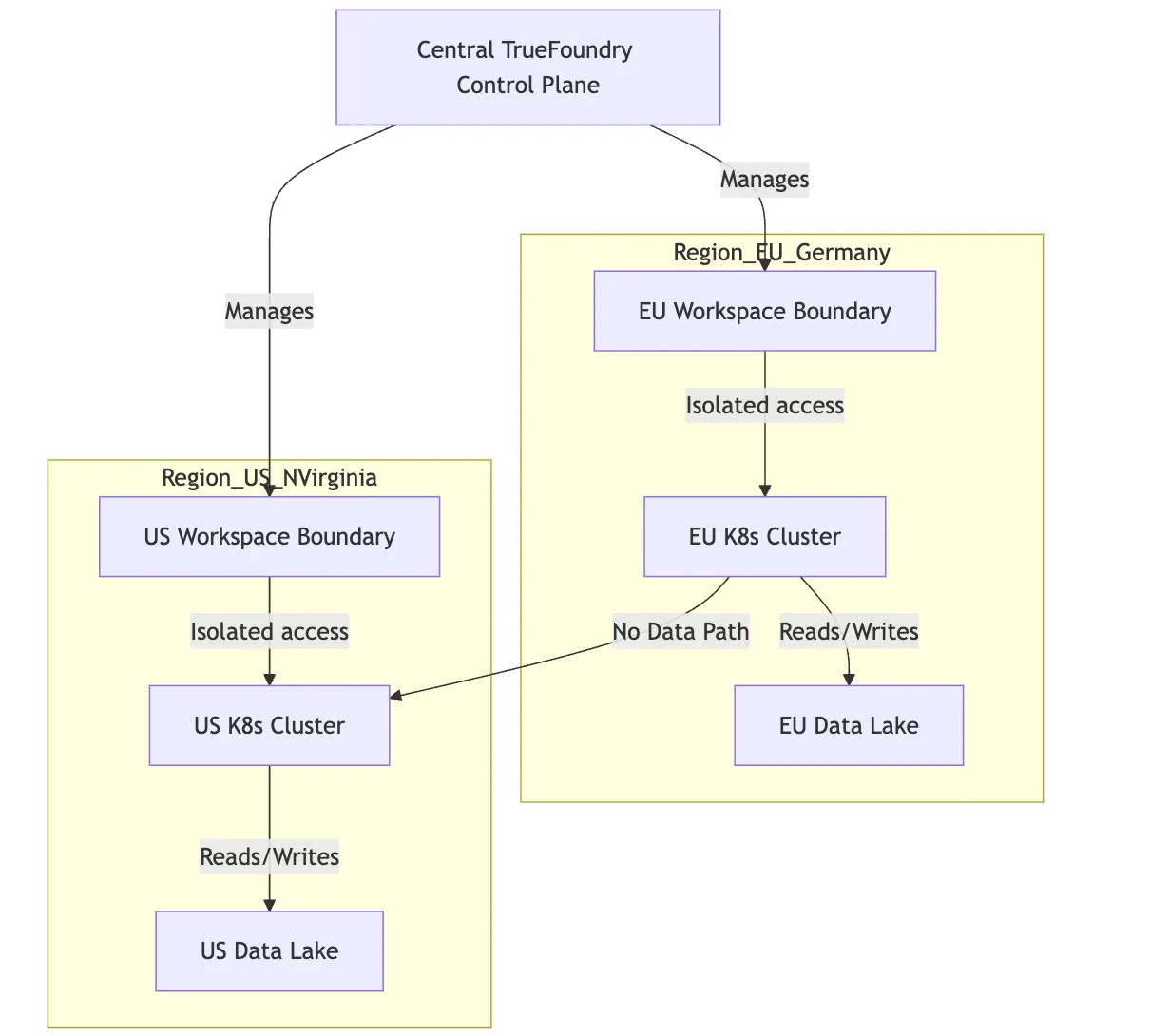
Abbildung 2: Diagramm der Isolierung mehrerer Regionen mithilfe von Arbeitsbereichen
Data Residency ist selten eine spannende Arbeit, aber sie ist grundlegend. Wenn Sie es falsch verstehen, ist nichts anderes wichtig.
Das Schöne an der Architektur von TrueFoundry ist, dass es nicht versucht, selbst ein „sicherer Datenbunker“ zu sein. Stattdessen respektiert es die Bunker, die Sie bereits in AWS, Azure oder GCP gebaut haben. Es ermöglicht uns, unseren Datenwissenschaftlern eine moderne, Heroku-ähnliche Bereitstellungserfahrung zu bieten, ohne ständig mit unserem InfoSec-Team um Ausnahmen kämpfen zu müssen. Wir definieren den Perimeter einmal, fügen TrueFoundry hinzu und müssen uns keine Gedanken mehr über versehentlichen Datenaustritt machen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




