

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wir alle hatten diesen Moment mit dem Code Interpreter von ChatGPT (jetzt „Advanced Data Analysis“). Du lädst eine chaotische CSV-Datei hoch, bittest sie, „die Daten zu korrigieren und den Trend zu zeichnen“, und beobachtest voller Ehrfurcht, wie Python-Code in Echtzeit geschrieben und ausgeführt wird.
Es ist eine Produktivitäts-Superwaffe. Es ist auch eine massive Sicherheitslücke, wenn Sie mit sensiblen Daten arbeiten.
In dem Moment, in dem du die CSV-Datei hochlädst, verlässt sie deinen Umkreis. Für unser Team bestand das Ziel darin, diese „OpenCode“ -Funktion zu replizieren und unseren LLM-Agenten die Möglichkeit zu geben, Code zu schreiben und auszuführen — ohne das Risiko einer Datenexfiltration. Wir wollten keine „Blackbox“ -API; wir brauchten eine Privater Code-Interpreter wo die Berechnung neben den Daten stattfindet.
So haben wir die sichere Toolnutzung und Codeausführung mithilfe der Infrastrukturkomponenten von TrueFoundry implementiert.
Bei „OpenCode“ geht es nicht nur darum, ein Modell zu haben, das Python schreiben kann. Es erfordert drei verschiedene Komponenten, die zusammenarbeiten:
Die meisten Leute bleiben bei „The Hands“ hängen. Sie können nicht einfach ein LLM os.system ('rm -rf /') auf Ihrem Produktionscluster ausführen lassen. Sie benötigen eine Sandbox.
TrueFoundry löst dieses Problem, indem es uns die Bereitstellung ermöglicht kurzlebige Ausführungsumgebungen (Dienste oder Jobs), die als Sandbox dienen. Das LLM Gateway verarbeitet die Definitionen der Toolnutzung, und die eigentliche Ausführung erfolgt in einem gesperrten Container innerhalb unserer VPC.
Hier ist der Arbeitsablauf, wie aus einer Benutzeranfrage eine sichere Codeausführung wird.
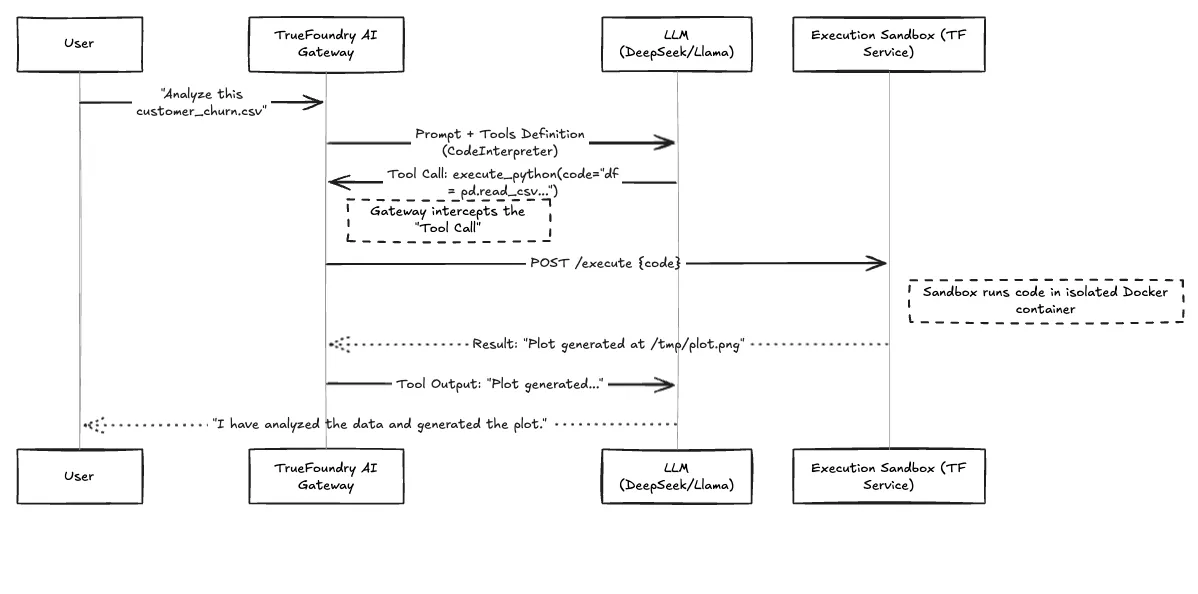
Bild 1: Arbeitsablauf der OpenCode-Ausführungsschleife
Als wir zum ersten Mal versuchten, dies zu erstellen, haben wir die Komplexität der Ausführungsumgebung unterschätzt. Wenn Sie eine standardmäßige SaaS-Code-Interpreter-API verwenden, senden Sie Ihre Daten an sie. Wenn Sie es lokal ausführen, riskieren Sie, den Host zu gefährden.
Wir verwenden TrueFoundry Dienstleistungen um einen benutzerdefinierten „Code Execution Agent“ zu hosten. Dies ist im Wesentlichen ein Python-FastAPI-Dienst, der in einen Docker-Container eingebettet ist und Folgendes enthält:
Da TrueFoundry das zugrunde liegende Kubernetes-Manifest verwaltet, können wir diese Sicherheitseinschränkungen (SecurityContext, NetworkPolicies) direkt über die Bereitstellungsoberfläche oder Terraform einfügen, um sicherzustellen, dass die Sandbox wirklich eine Sandbox ist.
Der Kompromiss war schon immer Bequemlichkeit und Kontrolle. Indem wir TrueFoundry nutzen, um das „OpenCode“ -Muster zu orchestrieren, verschieben wir das Gleichgewicht. Wir genießen den Komfort einer verwalteten Bereitstellung ohne das Datenrisiko.
Tabelle 1: Dies ist das Beispiel für einen Vergleich zwischen Gateway und Sandbox
Die wahre Kraft entfaltet sich, wenn du kombinierst Verwendung des Tools mit Ihren internen APIs.
Wir haben das TrueFoundry LLM Gateway so konfiguriert, dass nicht nur das Tool „Python Interpreter“ verfügbar ist, sondern auch Tools für unseren internen Data Lake (z. B. get_user_churn_metrics (user_id)).
Da das LLM durch das Gateway leitet und das Gateway mit unseren privaten Diensten verbunden ist, kann das Modell jetzt:
All dies geschieht, ohne dass ein einziges Byte an Kundendaten unser privates Subnetz verlässt.
Die Implementierung von „OpenCode“ ist nicht mehr nur ein lustiges Hackathon-Projekt, sondern eine Voraussetzung für moderne KI-Agenten. Aber du kannst es nicht einfach zusammen mit LangChain hacken und auf das Beste hoffen.
Wir behandeln unseren Code-Interpreter als kritische Infrastruktur. Wir überwachen es mithilfe des Observability-Stacks von TrueFoundry und verfolgen nicht nur die LLM-Token, sondern auch die CPU-Spitzen in der Sandbox und die Ausführungslatenz. Wenn ein Benutzer ein Skript schreibt, das versucht, 50 GB RAM zuzuweisen, beendet TrueFoundry den Pod, bevor er sich auf den Cluster auswirkt, und der Benutzer erhält eine höfliche Fehlermeldung.
Das ist der Unterschied zwischen einer Demo und einer Plattform.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




