

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wir haben die Phase „Schau dir diese coole Demo an“ von Voice AI hinter uns gelassen. Unternehmen entwickeln nicht mehr nur niedliche Alexa-Skills. Sie setzen komplexe, multimodale Systeme ein, die darauf ausgelegt sind, Millionen von sensiblen Kundeninteraktionen abzuwickeln — von Banküberweisungen bis hin zur Triage im Gesundheitswesen.
Aber hier ist die unbequeme Wahrheit, wenn es darum geht, Sprach-KI vom Prototyp zur Produktion zu bewegen: Sie ist unglaublich fragil.
Im Gegensatz zu textbasierten Chatbots, bei denen ein Fehler nur eine schlechte Textantwort ist, ist ein Ausfall bei Voice AI gravierend. Es ist tote Luft. Es ist eine Roboterstimme, die stottert. Es ist ein Kunde, der „Agent“ schreit! wiederholt, weil die Latenz bei der RAG-Suche 400 ms zu lang war und der ASR sie abschaltete.
Wenn Sie einen riesigen Stack orchestrieren, der automatische Spracherkennung (ASR), komplexe Absichtsklassifizierung, agentische Retrieval-Augmented Generation (RAG) und realistische Text-to-Speech (TTS) umfasst, sind Standard-Tools zur Anwendungsüberwachung (APMs) völlig unzureichend. Sie sagen es dir Das etwas ist kaputt gegangen, aber selten warum.
In diesem Beitrag wird ein realistischer Anwendungsfall für große Unternehmen vorgestellt, um zu demonstrieren, warum spezialisierte Observability nicht verhandelbar ist und wie Plattformen wie TrueFoundry zur Steuerungsebene für diese komplexen Systeme werden.
Um die Herausforderung der Beobachtbarkeit zu verstehen, müssen wir uns zunächst das „Biest“ ansehen, das wir zu zähmen versuchen. Ein moderner, dialogorientierter Sprachagent ist kein einzelnes Modell, sondern ein Staffellauf aus hochspezialisierten Komponenten, die oft über verschiedene Infrastrukturen verteilt sind.
Wenn eine einzelne Übergabe in diesem Staffellauf scheitert, stürzt die gesamte Benutzererfahrung ab.
Stellen wir uns Apex Financial vor, eine große Bank, die einen Sprachassistenten einsetzt, um mittelgroße Transaktionen wie die Überprüfung von Salden verschiedener Anlageklassen und die Initiierung internationaler Überweisungen abzuwickeln.
Die Skala: 50.000 gleichzeitige Anrufe zu Spitzenzeiten.
Es steht viel auf dem Spiel. Bei einer Übertragung „fünfzig“ falsch als „sechzig“ zu interpretieren, ist katastrophal.
Der Stapel:
Eine Kundin, „Sarah“, ruft an. Sie hat ein leichtes Hintergrundgeräusch und sagt: „Ich muss meinem Bruder in London 5.000 von meinen Ersparnissen schicken.“
So sieht dieser Arbeitsablauf aus und wo die Dinge normalerweise schief gehen.
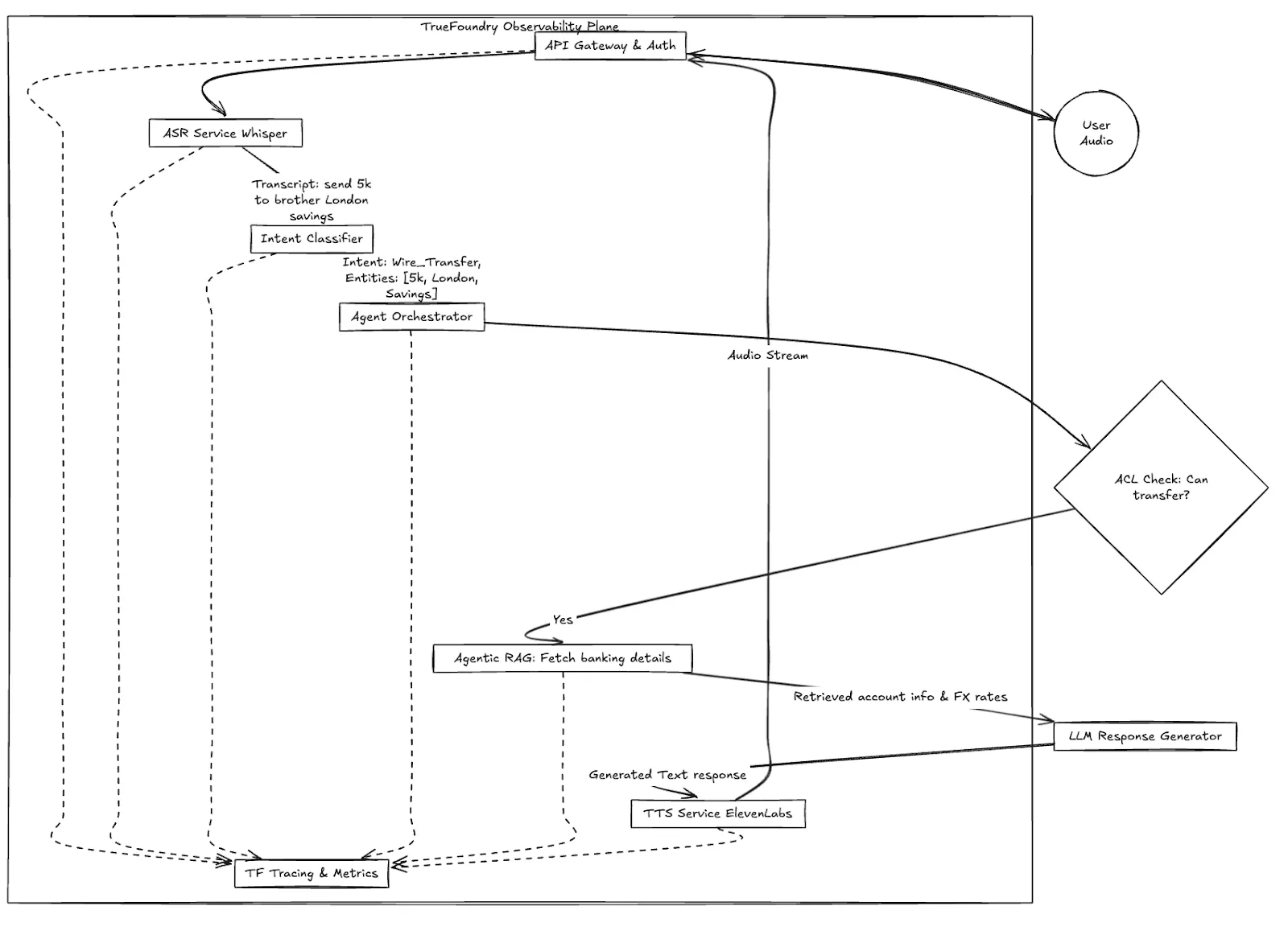
Abbildung 1: Allgemeiner Arbeitsablauf der Sprachtransaktion von Apex Financial, der die entscheidende Rolle der Observability Plane zeigt.
In einer Standardkonfiguration erhält das Engineering-Team ein Ticket mit der Aufschrift „Voice Bot hat aufgelegt“, wenn Sarahs Anruf fehlschlägt.
Sie überprüfen Datadog oder Prometheus. Die CPU ist in Ordnung. Der Speicher ist in Ordnung. Die Kubernetes-Pods sind aktiv. Was ist passiert?
Ohne spezielle Sprach-KI-Beobachtbarkeit ist das Debuggen so, als würde man ein Labyrinth-Rätsel ohne forensische Tools lösen.
In einem verteilten Sprach-KI-System ist die Latenz kumulativ. Eine Verzögerung von 200 ms bei ASR plus eine Verzögerung von 400 ms bei RAG entsprechen einem misslungenen Kundenerlebnis. Sie benötigen ein Tracing, das Audioframes versteht, nicht nur HTTP-Anfragen.
Hier werden Plattformen wie TrueFoundry unverzichtbar. TrueFoundry ist nicht nur ein weiteres Monitoring-Dashboard, sondern eine KI/ML-Infrastruktur- und Beobachtbarkeitsplattform, die speziell für die Komplexität von GenAI-Stacks, einschließlich Sprache, entwickelt wurde.
TrueFoundry behandelt die gesamte Kette — vom ersten Audiopaket bis zum letzten TTS-Stream — als beobachtbaren Fluss.
So werden die kritischen Unternehmensanforderungen erfüllt, die bei generischen Tools nicht berücksichtigt werden:
Die Standardverfolgung zeigt Ihnen die Hop-Zeiten von Service zu Service. Das spezielle Tracing von TrueFoundry ermöglicht es Ihnen, das Latenzbudget einer Konversation in Echtzeit zu visualisieren.
Sie können sehen, dass ASR für Sarahs Anruf 350 ms dauerte (akzeptabel), aber der Agentic RAG-Schritt dauerte 2,1 Sekunden (inakzeptabel). Sie können den RAG-Schritt sofort genauer untersuchen: War es der Vektor-DB-Abruf? War es das Reranking-Modell?
Sie hören auf zu raten und fangen an, den Engpass zu beheben.
Wenn Ihre Voice AI einen Agenten verwendet, um Entscheidungen zu treffen (z. B. um zu überprüfen, ob Sarah über ausreichend Geld verfügt) vor wenn Sie nach dem Ziel fragen), müssen Sie den „Denkprozess“ des Agenten überprüfen.
TrueFoundry bietet Beobachtbarkeit der Zwischenschritte des Agenten. Sie sehen nicht nur die Eingabe und Ausgabe, sondern auch die Tools, die der Agent ausgewählt hat, die Abfragen, die er für die Vektordatenbank ausgeführt hat, und den Rohkontext, den er abgerufen hat. Wenn der Bot eine falsche Antwort gibt, können Sie genau sehen, welche veralteten Daten er aus dem RAG-System abgerufen hat, die die Halluzination verursacht haben.
Im Bankwesen ist es von größter Bedeutung, „wer kann was tun“. Sie können nicht zulassen, dass Ihr Marketing-Voice-Bot versehentlich auf den Transaktionsagenten zugreift.
TrueFoundry bietet robuste Zugriffskontrolllisten (ACL), die festlegen, welche Modelle und Agenten interagieren können. Darüber hinaus verwendet TrueFoundry angesichts des Wachstums von Systemen mit mehreren Agenten Standards wie das Model Context Protocol (MCP), um eine authentifizierte, sichere Kommunikation zwischen verschiedenen KI-Agenten innerhalb Ihres Ökosystems zu gewährleisten.
Beobachtbarkeit ist hier nicht nur Leistung, sondern auch Sicherheitsüberprüfung. Sie benötigen ein Protokoll, das nachweist warum Agent A wurde während eines Live-Anrufs der Zugriff auf Datenquelle B verweigert.
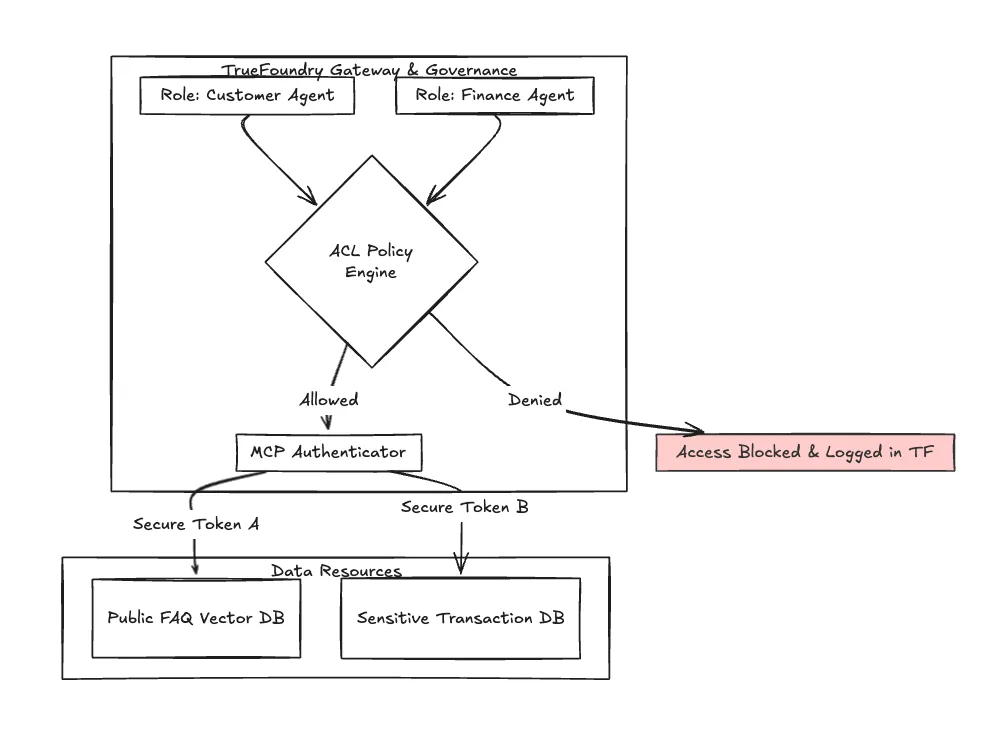
Abbildung 2: Vereinfachte Ansicht des ACL- und MCP-Authentifizierungsflusses, der innerhalb des TrueFoundry-Ökosystems verwaltet wird und die Isolierung sensibler Sprachagenten gewährleistet.
Um den Unterschied zwischen Standardüberwachung und dem, was für Sprach-KI in Unternehmen erforderlich ist, zusammenzufassen:
Tabelle 1: Vergleich der Observability-Tiefen von Standard-APM und TrueFoundry Voice AI.
Für Apex Financial bedeutete der Einsatz von TrueFoundry den Unterschied zwischen einem Rollback des Sprachassistentenprogramms und dessen Skalierung. Sie wechselten von einer MTTD (Mean Time To Detection) von Stunden auf Minuten. Sie konnten proaktiv erkennen, dass ein bestimmtes RAG-Einbettungsmodell in Zeiten mit hohem Datenvolumen zu Latenzspitzen führte vor Kunden fingen an aufzulegen.
Bei der Entwicklung von Voice AI für Unternehmen sind die von Ihnen ausgewählten Modelle — Whisper, ElevenLabs, GPT-4O — nur der Motor. Beobachtbarkeit ist das Avioniksystem. Sie sollten nicht versuchen, einen Jet nur mit einem Geschwindigkeitsmesser zu fliegen. Versuchen Sie auch nicht, ein Enterprise-Voice-Stack ohne tiefgreifende, spezialisierte Beobachtbarkeit zu betreiben.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




