

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
AWS Bedrock dient als verwaltete Ebene für den Zugriff auf Foundation-Modelle innerhalb der AWS-VPC-Grenze. Für Entwicklungsteams entfällt damit der betriebliche Aufwand für die Bereitstellung von GPU-Instances oder die Verwaltung von Kubernetes-Clustern für Inferenzen. Der Service bietet über eine einheitliche API sofortigen Zugriff auf Modelle wie Claude 3.5 Sonnet, Llama 3 und Amazon Titan.
Jedoch Preise für AWS Bedrock ist keine Flatrate. Es handelt sich um ein komplexes Menü, in dem die endgültigen Kosten von der Modellvarianz, der Token-Verteilung, den regionalen Datenverkehrskapazitäten und dem Betriebsaufwand unterstützender Dienste wie CloudWatch und OpenSearch abhängen. Dieser Bericht analysiert die Wirtschaftlichkeit von AWS Bedrock pro Einheit, identifiziert, wo die Kosten in großem Umfang ansteigen, und analysiert die architektonischen Kompromisse zwischen verwalteten Inferenzen und selbst gehosteten Alternativen mithilfe von Plattformen wie TrueFoundry.
Bevor Sie die Kosten detailliert untersuchen, ist es wichtig, das allgemeine Preismodell von AWS Bedrock zu verstehen. AWS Bedrock folgt einem reinen nutzungsabhängiger Preisansatz ohne Plattform- oder Abonnementgebühren im Voraus.
Sie zahlen nicht, um den Dienst einzuschalten. Stattdessen wird Ihnen in erster Linie die Modellinferenz in Rechnung gestellt, die anhand von Tokens oder generierten Ausgaben gemessen wird. Der Preis pro Einheit variiert jedoch je nach Anbieter des Foundation-Modells erheblich. Ein anthropisches Modell kostet deutlich mehr als ein Meta- oder Mistral-Modell, selbst wenn die Anzahl der Token identisch ist.
Die Preisgestaltung von AWS Bedrock hängt davon ab, wie Modelle bei der Inferenz Ressourcen verbrauchen. Während die meisten Textmodelle pro Token abrechnen, unterscheiden sich multimodale Modelle.
Sie müssen unterscheiden zwischen Eingabe-Token und Ausgabetokens. Die Eingabe-Token bestehen aus der Prompt-Nutzlast, einschließlich Systemanweisungen, Benutzerabfragen und — was entscheidend ist — abgerufenem Kontext aus RAG-Pipelines. Ausgabe-Token sind die generierte Antwort.
Aufgrund der betrieblichen Realität sind Ausgabe-Tokens erheblich teurer, da die Rechenkosten für die Generierung (Vorhersage des nächsten Tokens) höher sind als die der Verarbeitung des Eingabekontexts. Zum Beispiel mit Claude Sonett 4.5 in us-east-1 zahlst du 3,00$ pro Million Eingabe-Token aber 15,00$ pro Million Ausgangstoken—ein 5-facher Multiplikator. Bei multimodalen Modellen wie Amazon Titan Image Generator wird die Abrechnung auf eine Bildbasis verschoben, die anhand der Auflösung und der Anzahl der Schritte berechnet wird.
Abbildung 1: Der Kostenmultiplikatoreffekt
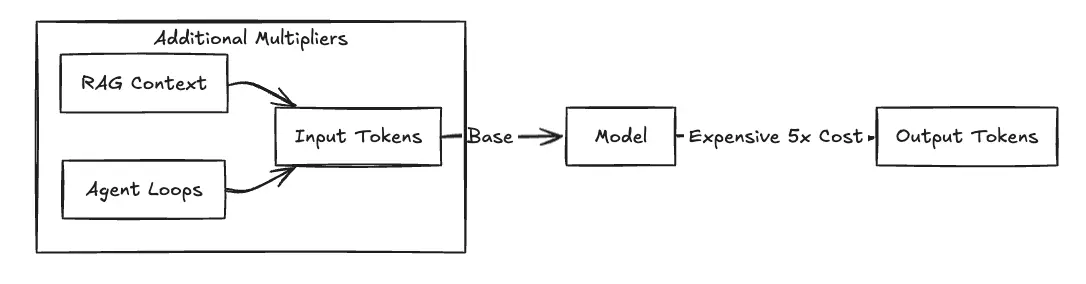
Bei der Preisgestaltung von AWS Bedrock geht es nicht nur um „Bezahlung pro Token“. Teams müssen zwischen zwei Preismodellen wählen, bei denen Flexibilität gegen garantierte Kapazität eingetauscht wird.
Abbildung 2: Aufschlüsselung der Gesamtrechnung
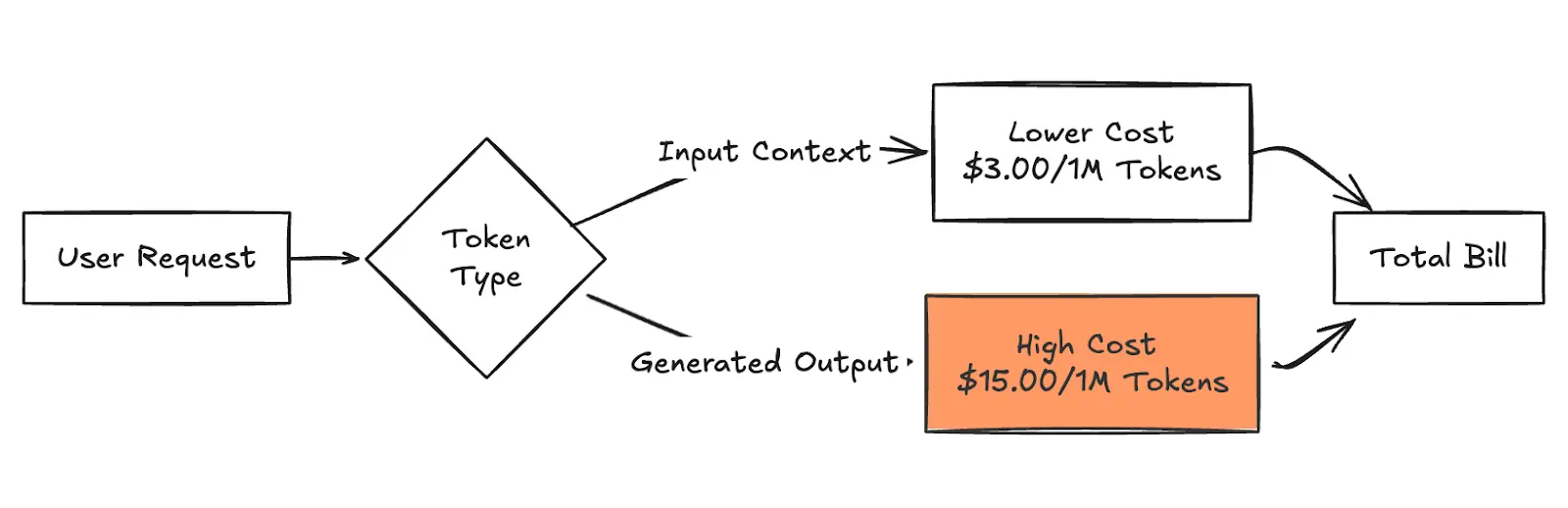
Die Preisgestaltung entspricht den AWS Bedrock On-Demand-Preisen für Anthropisches Claude 3.5 Sonett in der US-Ost-1 Region, Stand Januar 2026. Die Preise können je nach Region oder Modellversion variieren.
On-Demand-Preise sind die Standardoption für die meisten AWS Bedrock-Benutzer. Es bietet Flexibilität, ist aber mit betrieblichen Risiken verbunden. Die Abrechnung erfolgt ausschließlich pro 1.000 verarbeiteten Token. Dies ist ideal für variable Verkehrsmuster oder frühe Experimente, bei denen die Nutzungsmuster „überlastet“ sind. Der Nachteil ist jedoch die Zuverlässigkeit. AWS setzt Drosselungsgrenzwerte durch, was bedeutet, dass Ihre Anfragen bei Spitzenauslastung möglicherweise gedrosselt werden.
Die Preise für Provisioned Throughput richten sich an Teams, die eine garantierte Modellverfügbarkeit in großem Maßstab benötigen. Sie sorgt für Berechenbarkeit, erfordert jedoch ein finanzielles Engagement. Anstatt pro Token zu zahlen, erwerben Sie eine dedizierte Modelleinheit, um die Inferenzkapazität zu reservieren und eine bestimmte Preisstufe für den Durchsatz zu garantieren.
Der Haken ist, dass Ihnen eine feste Stundengebühr berechnet wird, unabhängig davon, ob Sie keine Anfragen senden oder die Einheit maximal ausschöpfen. Dieses Modell funktioniert wie eine Reserved Instance. In der Regel ist eine Laufzeit von 1 bis 6 Monaten erforderlich, sodass Sie nicht schnell zwischen Modellen wechseln können, falls nächste Woche ein besseres Modell veröffentlicht wird.
Im Gegensatz zu OpenAI, wo Sie einen Anbieter bezahlen, ist Bedrock ein Marktplatz. Die Preisstrategien unterscheiden sich je nach Anbieter.
Amazon Titan-Modelle sind AWS-native Basismodelle, die für allgemeine KI-Workloads entwickelt wurden. Da es sich um Modelle von Erstanbietern handelt, sind sie in der Regel günstiger als Alternativen von Drittanbietern. Dadurch eignen sie sich für kostensensible Produktionsanwendungen wie das Einbetten der Generierung oder die einfache Klassifizierung, bei denen eine „ausreichend gute“ Leistung zu einem niedrigen Preis das Ziel ist.
AWS Bedrock bietet auch Zugriff auf Modelle von externen Anbietern wie Anthropic, Cohere und AI21 Labs. Die Preise hier sind aufgrund der erweiterten Funktionen und der damit verbundenen externen Lizenzierung in der Regel höher. Beachten Sie den Kostenaufschlag bei Modellen mit hoher Argumentation wie Claude 4.5 Sonnet, bei denen Output-Token deutlich teurer sind. Bei chatlastigen Anwendungen, bei denen das Modell „mitdenkt“ oder lange, ausführliche Antworten generiert, können die Kosten hier schnell steigen.
Ihr Anwendungsdesign wirkt sich genauso auf Ihre Rechnung aus wie der Modellpreis.
Der Basis-Token-Preis ist oft nur die Spitze des Eisbergs. Reale KI-Anwendungen verwenden „Wissensdatenbanken“ und „Agenten“, die jeweils über eigene Zähler verfügen.
Abbildung 3: Der zusätzliche Kostenstapel
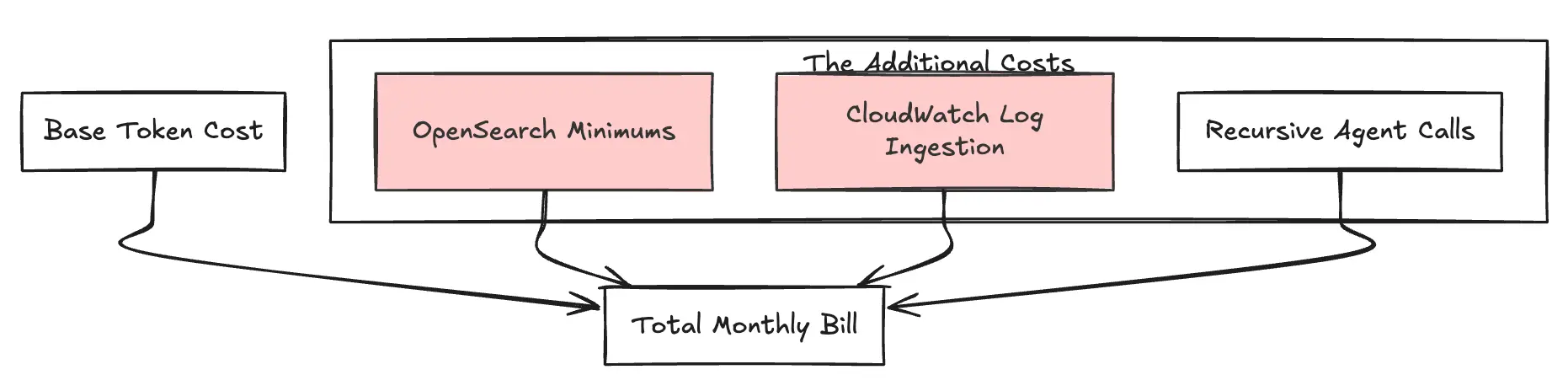
Bedrock Knowledge Bases abstrahieren die RAG-Pipeline, stellen aber im Hintergrund die Infrastruktur bereit. In der Regel wird dadurch ein OpenSearch Serverlos Vektor-Shop. Entwicklungsteams übersehen oft die Mindestkosten: OpenSearch Serverless benötigt aus Redundanzgründen in der Produktion mindestens 2 OCUs (OpenSearch Compute Units). Bei ~0,24 $ pro OCU/Stunde (in US-East-1), dies führt zu Basiskosten von ca. 350 $/Monat (für ein redundantes Standard-Setup), damit der Index auch ohne Abfrageverkehr existiert.
„Agenten“ führen mehrere Schritte durch, um eine Benutzeranfrage zu beantworten (Denken → Suchen → Zusammenfassen). Dies hat zur Folge, dass eine einzelne Benutzerfrage möglicherweise ausgelöst wird 10x die Tokens was Sie aufgrund dieser internen Schleife- und Argumentationsspur erwartet hatten. Sie zahlen für die Eingabe und Ausgabe jedes Zwischengedankens, was einen Multiplikatoreffekt auf Ihre Rechnung hat.
Überprüfbarkeit ist für KI in Unternehmen unerlässlich, aber die Integration von Bedrock in CloudWatch Logs ist umfangreich. Es protokolliert vollständige Payloads für Eingabeaufforderungen und Antworten. Die Aufnahme von CloudWatch in Regionen wie US-East-1 kostet 0,50$ pro GB, und der Speicher fügt einen weiteren hinzu 0,03$ pro GB. Anwendungen zur Textgenerierung mit hohem Volumen können problemlos Hunderte von Gigabyte an Protokolldaten generieren, wodurch die monatliche Rechnung im Hintergrund erheblich belastet wird.
Viele Teams unterschätzen die Preise für AWS Bedrock in frühen Experimenten, da die Variablen schwer zu isolieren sind. Die Verwendung von Token ist je nach Benutzerverhalten sehr unterschiedlich. Ein Benutzer stellt möglicherweise eine einfache Frage, während ein anderer ein 50-seitiges PDF zur Zusammenfassung einfügt. Darüber hinaus experimentieren Entwickler gerne, und wenn Sie von Claude Haiku zu Claude Sonnet wechseln, ändert sich Ihre Preisstufe sofort, oft ohne dass die Finanzabteilung es erst am Ende des Monats bemerkt. Schließlich werden die AWS-Budgets auf Kontoebene verwaltet, was es sehr schwierig macht, zu erkennen, „Wie viel hat der Marketing-Bot im Vergleich zum Engineering-Bot ausgegeben?“ ohne komplexe Tagging-Strategien.
Trotz der Komplexität funktioniert die Preisgestaltung von AWS Bedrock für bestimmte Szenarien gut. Wenn Sie bereits standardmäßig auf AWS setzen, lohnt sich die „native Integration“ -Tax aufgrund der Sicherheits- und Compliance-Vorteile wie IAM und PrivateLink. Für Anwendungen mit hohem Traffic, die selten oder unvorhersehbar genutzt werden, ist das On-Demand-Modell perfekt, da Sie nichts zahlen, wenn die App inaktiv ist. Es ermöglicht den schnellen Start von Projekten in der Frühphase, ohne dass GPUs oder Kubernetes-Cluster verwaltet werden müssen. Vor der Kostenoptimierung wird die Eignung des Produkts für den Markt überprüft.
Mit zunehmender Reife der KI-Workloads stoßen Teams häufig auf strukturelle Einschränkungen. Bei hohen Volumina (Millionen von Anfragen) wird der Aufschlag pro Token teurer als der eigene Rechenaufwand. Für die Feinabstimmung auf Bedrock ist oft ein Kauf erforderlich Bereitgestellter Durchsatz, was die Einstiegshürde im Vergleich zur Feinabstimmung von Llama 3 auf Ihrer eigenen GPU dramatisch erhöht. Darüber hinaus fehlt es in Umgebungen mit mehreren Teams an einer detaillierten Budgetdurchsetzung auf Anwendungsebene, was zu einer „Tragödie der Gemeingüter“ führt, bei der ein Team das gemeinsame Budget verbraucht.
TrueFoundry bietet ein alternatives Architekturmuster für Teams, die an die Obergrenze der Einheitsökonomie von Bedrock stoßen. Anstatt die Modell-API mit einem Markup zu mieten, orchestriert TrueFoundry die Bereitstellung von Open-Source-Modellen (Llama 3, Mistral, Qwen) direkt auf Ihren eigenen AWS EC2- oder EKS-Clustern.
Dadurch wird die Fähigkeit zur Nutzung freigeschaltet AWS-Spot-Instanzen. Durch Inferenz auf Spot-Kapazität — freie AWS-Rechenleistung, die zu hohen Rabatten erhältlich ist — können Sie die reinen Inferenzkosten wie folgt reduzieren 60-70% im Vergleich zu Bedrock-Tarifen auf Abruf. TrueFoundry managt das Betriebsrisiko von Spot-Unterbrechungen, indem das Fallback auf On-Demand-Instances automatisiert wird, wenn Spot-Kapazität zurückgewonnen wird. So wird die Zuverlässigkeit gewährleistet, ohne dass der bereitgestellte Durchsatz sechs Monate lang festgelegt werden muss.
Dies ist ein sachlicher Vergleich, der sich auf die Wirtschaftlichkeit der Bereitstellung von Modellen konzentriert.
Mit der zunehmenden Verbreitung von KI wird eine klare Preisgestaltung für eine nachhaltige Skalierung von entscheidender Bedeutung. Bei der Preisgestaltung von AWS Bedrock sollte man sich nicht zwischen Innovation und Konkurs entscheiden müssen.
TrueFoundry gibt Ihnen die Möglichkeit, Ihre KI-Ausgaben zu kontrollieren. Es bietet detaillierte Einblicke in jedes Modell und die Flexibilität, Workloads auf der kostengünstigsten verfügbaren Infrastruktur auszuführen — egal, ob es sich um die Bedrock-API oder eine Spot-Instance in Ihrer VPC handelt.
Buche eine kostenlose Demo erfahren Sie jetzt mehr darüber, wie TrueFoundry Ihren Betrieb unterstützen kann.
Die Preise für AWS Bedrock variieren je nach Foundation-Modell und Token-Nutzung. Modellinferenzen für kleine Mengen sind zwar verfügbar, aber umfangreiche Modellinferenzen werden aufgrund von Markups für verwaltete Dienste kostspielig. TrueFoundry ermöglicht eine bessere Kostenoptimierung, indem Modelle auf AWS-Spot-Instances ausgeführt werden, wodurch Ihre monatlichen Gesamtkosten im Vergleich zu den Tarifen von Bedrock erheblich gesenkt werden.
Ja, die Kosten für AWS Bedrock folgen einem Pay-as-you-go-Preismodell. Ihnen wird jede Anzahl von Token in Rechnung gestellt, die für Eingabe-Token und Output-Token verarbeitet wurden. Bei umfangreichen generativen KI-Anwendungen häufen sich diese Gebühren schnell an. TrueFoundry bietet einen wirtschaftlicheren Ansatz, indem die reinen Rechenraten auf Ihrer eigenen Infrastruktur verwendet werden.
Die Amazon Bedrock-Preise beinhalten keinen dauerhaften kostenlosen Modus. Ein neues AWS-Konto bietet zwar allgemeine Gutschriften, Bedrock berechnet jedoch sofort Gebühren für Modellinferenz. TrueFoundry hilft, die Grundkosten zu minimieren, indem es Ihnen ermöglicht, günstigere Spot-Instances für Ihre speziellen Anwendungsfälle und Batch-Jobs zu verwenden.
Für AWS Bedrock gibt es kein dediziertes kostenloses Kontingent. Benutzer zahlen für die gesamte Nutzung der Text- und Bildgenerierung. Um unvorhersehbare Kosten für AWS Bedrock zu vermeiden, wechseln Teams zu TrueFoundry. TrueFoundry nutzt Autoscaling und Batch-Inferenz, um die Ausgaben für generative KI effektiver zu verwalten als der verwaltete Service.
TrueFoundry ist ein überlegenes Äquivalent zu diesem vollständig verwalteten Dienst. Es ermöglicht Ihnen, jedes benutzerdefinierte Modell (wie Mistral AI) oder ein Amazon Titan-Modell in Ihrer eigenen Cloud bereitzustellen. Im Gegensatz zu Bedrock vereinfacht es das Kostenmanagement durch den Einsatz von Spot-Instances und Datenautomatisierung und vermeidet so eine Anbieterbindung für benutzerdefinierte Modellimporte.
Es gibt keine kostenlose Version von Amazon Bedrock; Sie zahlen für den Zugriff auf jedes Foundation-Modell. Für einen besseren langfristigen Nutzen können Sie mit TrueFoundry Open-Source-Modelle mit Prompt-Caching und Modelldestillation auf Ihrer eigenen Hardware ausführen, wodurch die Einstiegshürde für die Einführung generativer KI drastisch gesenkt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




