

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Verkabelung einer generativen KI-Plattform auf Microsoft Azure bedeutet, verschiedene Berechnungs-, Identitäts- und KI-Primitive zusammenzufügen. Sie stellen Rohkapazität über Azure Kubernetes Service (AKS) und Spot-VMs bereit, wickeln die Identität über die Entra-ID ab und leiten Anfragen an Azure OpenAI weiter. Reibungsverluste entstehen, wenn Ihre Infrastrukturteams diese Verbindungen für jede neue Modellbereitstellung manuell orchestrieren müssen.
TrueFoundry wird als Infrastruktur-Overlay in Ihrem Azure-Abonnement bereitgestellt. Wir kümmern uns um den Bereitstellungszyklus, den Identitätsverbund und die automatische Skalierung. In diesem Beitrag werden die genauen Integrationsmuster beschrieben, die wir verwenden, um TrueFoundry mit Azure zu verbinden. Dabei werden die Bereitstellung auf geteilter Ebene, Netzwerkgrenzen und die Mechanismen zur Workload-Identität behandelt.
Wir verwenden eine Split-Plane-Architektur, um die Workload-Ausführung vom Plattformmanagement zu isolieren. Wenn Sie Plattformen erstellen auf Amazon EKS, dieses Modell kommt mir bekannt vor: Sie trennen die Bedienoberfläche von der Datenebene.
Wir verbinden die beiden Flugzeuge über eine sichere, nur für ausgehende Flüge gRPC Stream oder WebSocket. Der clusterseitige Agent initiiert die Verbindung zur Control Plane, um Manifeste abzurufen und Protokolle zu übertragen. Sie öffnen keine eingehenden Ports in Ihren VNET-Netzwerksicherheitsgruppen. Ihr VNET verweigert standardmäßig externen Zugriff aus dem Internet.
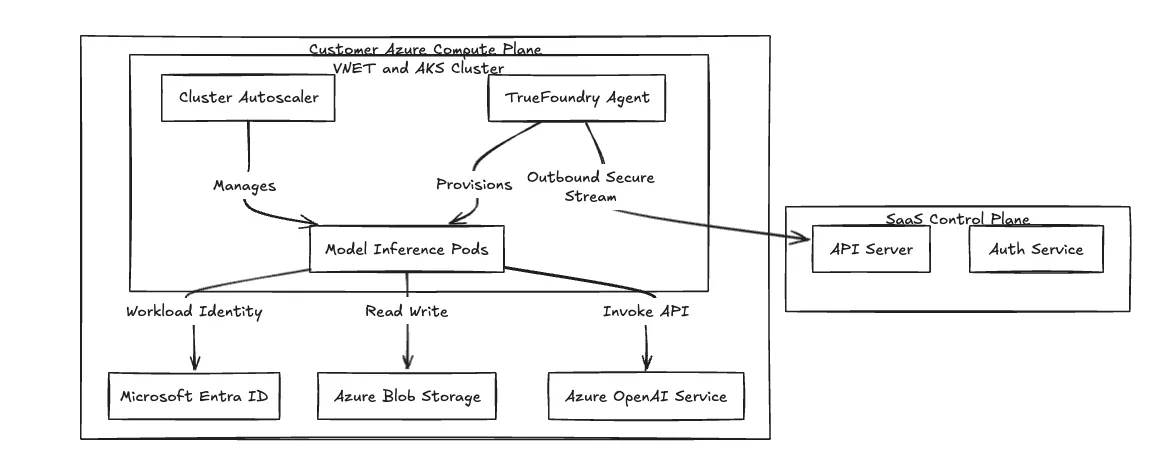
Abbildung 1: Die Split-Plane Architecture isoliert die Datenverarbeitung im Kunden-VNET.
Wir konfigurieren das Compute Plane Networking mithilfe von Azure CNI für die direkte IP-Zuweisung auf Pod-Ebene. Ihre Rechenressourcen bleiben in privaten Subnetzen.
Aus Gründen strenger Compliance-Grenzen leiten wir den Datenverkehr über Azure Private Link weiter. Verbindungen von Ihren Inferenz-Pods zu Azure OpenAI, Key Vault und Blob Storage werden vollständig über das Microsoft-Backbone geleitet.
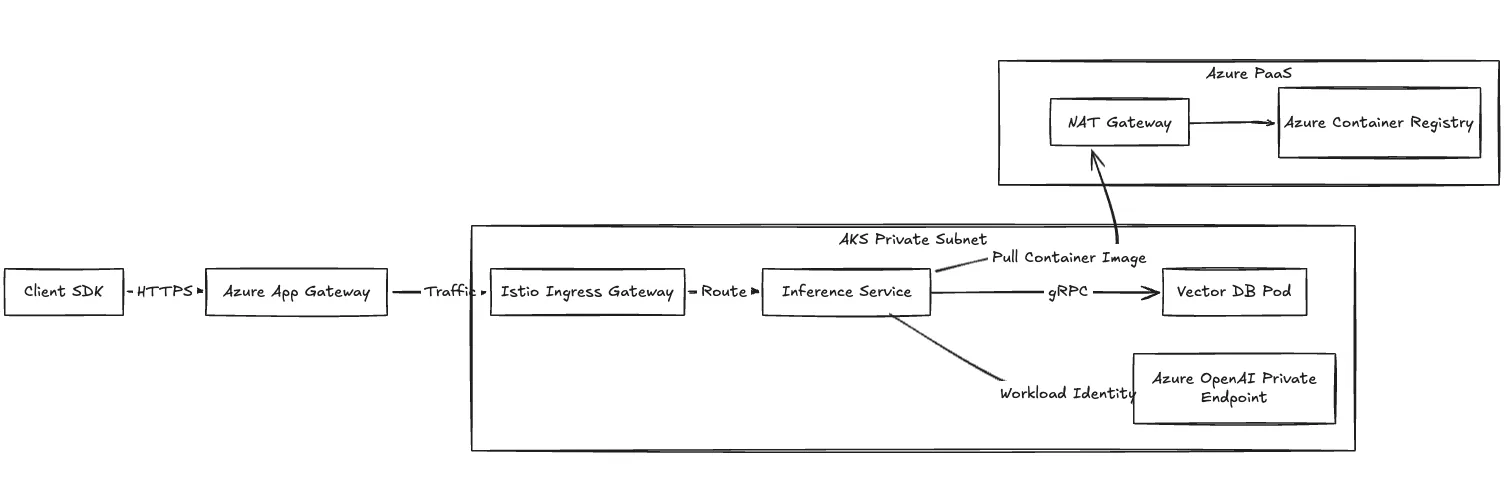
Abbildung 2: Netzwerkverkehrsfluss, der den eingehenden und privaten Anschluss an Azure PaaS detailliert beschreibt.
Fest codierte statische Geheimnisse und Service Principals führen zu einem erheblichen Rotationsoverhead. Wir authentifizieren Workloads dynamisch mithilfe der Microsoft Entra Workload ID. Wenn Sie AWS-Umgebungen verwalten, ist dies das Azure-Äquivalent von AWS IAM-Rollen für Servicekonten (IRSA).
Wenn Sie eine Pipeline bereitstellen, führen wir diese Sequenz aus:
Wir verwenden DefaultAzureCredential im Anwendungscode. Dadurch wird der Explosionsradius ausschließlich auf die RBAC-Berechtigungen beschränkt, die dieser bestimmten verwalteten Identität gewährt wurden.
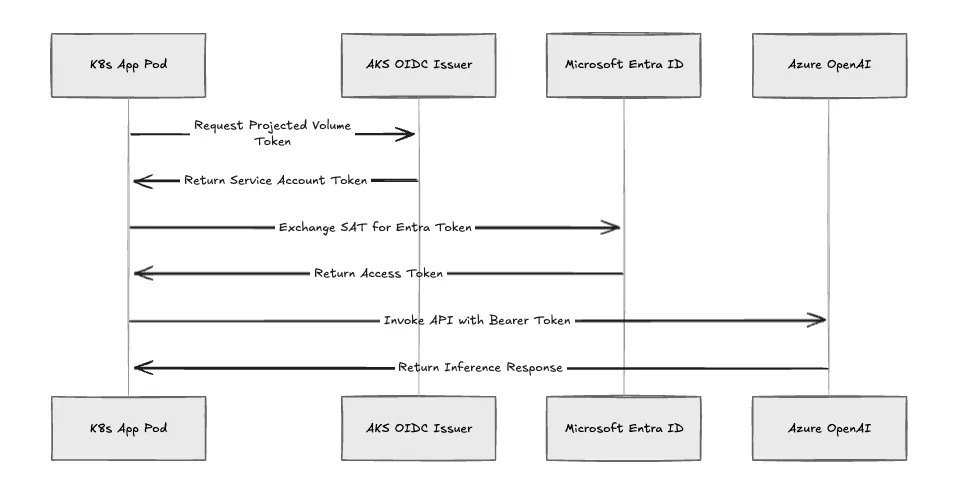
Abb. 3: Der Authentifizierungsablauf der Entra Workload ID.
Die Ausführung von Steady-State-Inferenzen auf On-Demand-VMs führt häufig zu höheren Basiskosten. Zur Orchestrierung integrieren wir direkt in AKS-Knotenpools Virtuelle Azure-Spot-Maschinen (ähnlich wie bei der Verwendung Amazon EC2-Spot-Instances).
Wir verwalten die Spot-Kapazität nach der folgenden Logik:
Für Teams, die Batch-Inferenz oder fehlertolerante API-Serving ausführen, ist dieses Setup — ähnlich wie beim Ausführen Karpenter auf AWS — kann die Kosten für Recheninstanzen je nach Workload-Flexibilität um bis zu 80% senken.
Die Verwaltung unterschiedlicher API-Schlüssel und Token-Per-Minute-Grenzwerte (TPM) in mehreren Azure-Regionen führt zu Betriebsbelastungen. Das TrueFoundry AI Gateway abstrahiert dies. Ähnlich wie beim Routing von Anfragen über Amazonas Bedrock, haben Entwickler einen einzigen internen API-Endpunkt erreicht.
Wir orientieren uns an den Standardpraktiken von GitOps und IaC. Sie stellen die zugrunde liegende Azure-Umgebung mithilfe unserer gepflegten Umgebung bereit Terraform Module.
Ihr Terraform-Status verwaltet die VNets, den AKS-Cluster, die OIDC-Aussteller und die zugrunde liegenden PostgreSQL-Datenbanken. Das TrueFoundry-Overlay wird einfach diesen nativen Ressourcen zugeordnet, sodass Ihre Infrastruktur überprüfbar und konform bleibt.
Die Bereitstellung von TrueFoundry auf Azure isoliert Ihre Rechenleistung und Datenausführung, während wir den Anwendungslebenszyklus verwalten. Sie behalten die direkte Autorität über Ihre VNets, NSGs und Datenresidenz-Perimeter. Wir kümmern uns um die Orchestrierung. Indem wir die komplexe Verkabelung zwischen AKS, Entra ID und Azure OpenAI abstrahieren, ermöglichen wir es Ihren Entwicklungsteams, sich auf die Versandmodelle zu konzentrieren, anstatt sich mit der Infrastruktur zu befassen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




