

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Das Vertriebsteam gerät in Panik — nächste Woche findet eine große Gesundheitskonferenz statt. Auf der Veranstaltungswebsite sind 200 Redner — Ärzte, Führungskräfte und Forscher — aufgeführt, die sich auf ein Dutzend paginierter Unterseiten verteilen. Um eine Lead-Liste zu erstellen, muss jemand die Website öffnen, auf einen Namen klicken, die Details in eine Tabelle kopieren, einen neuen Tab öffnen, auf LinkedIn nach dieser Person suchen, die Profil-URL kopieren und wieder einfügen.
Sie müssen das 200 Mal machen.

Für Ingenieure führt diese Anfrage normalerweise zu einem schnellen Python-Skript mit Selenium oder BeautifulSoup. Sie überprüfen den Seitenquelltext, finden das Div mit dem Namen des Klassensprechers und extrahieren den Text. Es funktioniert perfekt für ungefähr eine Woche. Dann aktualisiert die Website ihr Frontend-Framework, die CSS-Klassen ändern sich und das Skript stürzt ab.
Wir haben das gebaut Profil Crawler Beschleuniger, um diesen Zyklus zu stoppen. Es ist ein autonomer Agent, der auf Websites navigiert und Daten auf der Grundlage dessen extrahiert, was auf der Seite steht, und nicht darauf, wie der HTML-Code strukturiert ist.
So haben wir die Lösung konzipiert und dabei LangGraph für die Orchestrierung, Playwright für die Interaktion und TrueFoundry für die Verwaltung der Infrastruktur verwendet.
Der Hauptgrund, warum Scraping-Skripte fehlschlagen, ist ihre Abhängigkeit vom Document Object Model (DOM). Wenn Sie einem Skript sagen, dass es nach div.content-wrapper > h2.title suchen soll, wird es in dem Moment kaputt gehen, in dem ein Entwickler einen Klassennamen ändert.
Wir sind zu einem agentischen Ansatz übergegangen. Wir sagen es dem Bot nicht woher Die Daten sind pixelweise angeordnet. Stattdessen geben wir das gerenderte HTML (in Markdown konvertiert) an ein LLM weiter. Das Modell liest den Text so, wie es ein Mensch tun würde. Es versteht, dass ein Abschnitt mit der Bezeichnung „Keynote Speakers“ die von uns gewünschten Daten enthält, unabhängig von den zugrunde liegenden Tags.
Wir brauchten ein System, das Entscheidungen treffen kann, nicht nur ein lineares Skript. Die Anwendung muss entscheiden: Ist diese Eingabe eine URL oder nur ein Firmenname? Haben wir ein Captcha gedrückt? Ist diese Seite eine Liste von Personen oder eine einzelne Biografie?
Wir haben uns für LangGraph entschieden, um diesen Workflow als Zustandsmaschine zu modellieren, insbesondere wenn Langflow gegen LangGraph Entscheidungen begünstigen eine staatliche Orchestrierung.
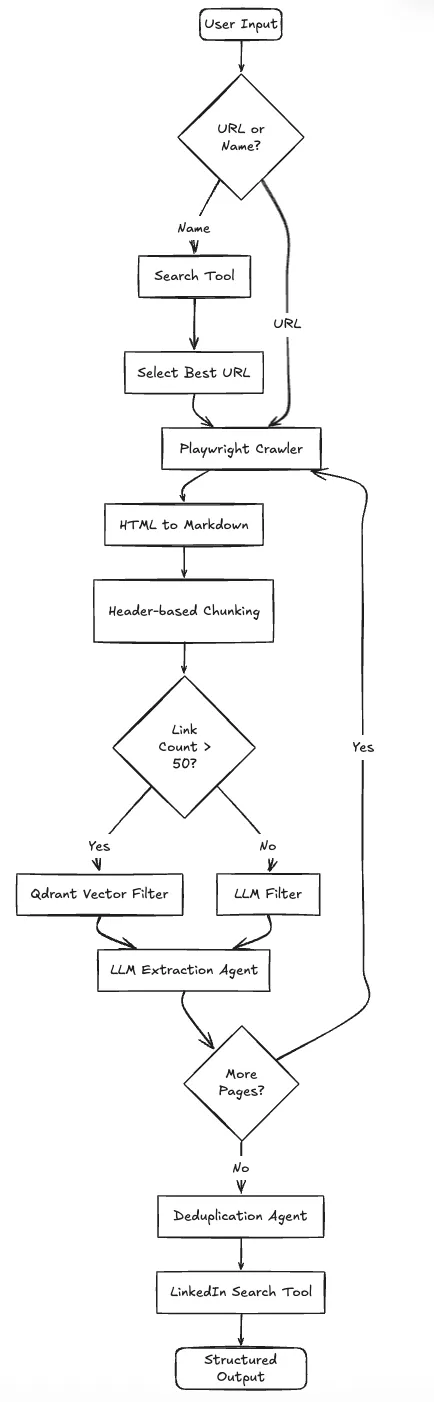
Das System arbeitet in einer Schleife und nicht in einer geraden Linie:
Hier ist die Systemarchitektur:
Der Betrieb von Headless-Browsern und LLM-Agenten in der Produktion verursacht betriebliche Probleme: Speicherlecks durch Chromium, Ratenbeschränkungen für LLM-APIs und die Notwendigkeit einer Prozessisolierung.
Wir haben das bereitgestellt auf Wahre Gießerei um mit diesen spezifischen Einschränkungen umzugehen.
Diese Anwendung nutzt LLMs häufig für Navigationsentscheidungen. Ohne Verwaltung steigen die Kosten schnell in die Höhe. Wir leiten alle Model-Calls über den TrueFoundry KI-Gateway.
Wir haben die Anwendung strukturiert mit dem Modellkontextprotokoll (MCP). Der „Crawler“ ist nicht nur eine Python-Funktion; er ist ein MCP-Server. Dies ermöglicht es uns, die Browserumgebung in einer Sandbox zu installieren. Wenn der Browser abstürzt (was bei Websites mit vielen JavaScript-Inhalten häufig der Fall ist), wird die Hauptanwendungslogik nicht unterbrochen.
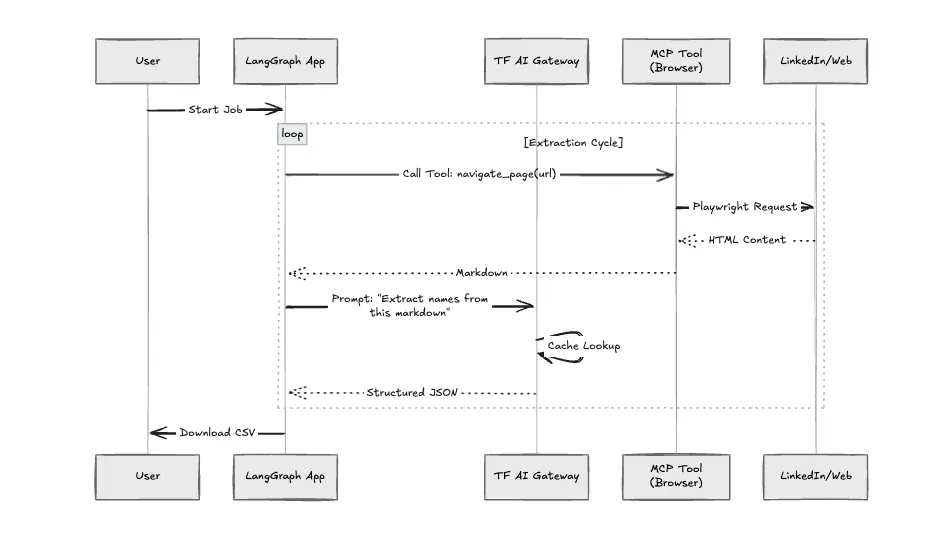
Wir haben den standardmäßigen Python-Skriptansatz mit dieser Architektur verglichen.
Den Weg des Glücks zu beschreiten ist einfach. Um es zuverlässig zu machen, mussten drei spezifische technische Probleme gelöst werden:
Diese Architektur löst die „letzte Meile“ der Datenerfassung, indem spröde Skripte durch adaptive Agenten ersetzt werden. Indem wir es auf TrueFoundry ausführen, stellen wir sicher, dass das System beobachtbar, kosteneffizient und skalierbar ist.
Sie können genau diese Architektur — einschließlich der Gateway-Konfiguration und der Dockerized Agents — noch heute aus der TrueFoundry-Anwendungsbibliothek bereitstellen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




