














November 5, 2025
|
5 min read

Published: June 26, 2026

Blazingly fast way to build, track and deploy your models!
As organizations scale their AI applications, knowing what your models are doing in production is as important as getting them running in the first place. Engineers need visibility into every inference request latency, token usage, model behavior, finish reason but connecting observability tooling to every model and provider means complex, repetitive instrumentation work for each integration.
The big question: how do you get full-stack visibility across all the models your teams are using without custom engineering for each one?
At Middleware, the goal is to make observability as easy as it is powerful. That's why we're thrilled to announce the integration of Middleware with the TrueFoundry AI Gateway. This integration gives your organization complete visibility into every AI inference request correlated with infrastructure metrics, application traces, and logs all from a single, centralized platform, helping ensure your AI operations are transparent and under control.
The TrueFoundry AI Gateway is a powerful way for developers and platform teams to manage, monitor, and scale their AI applications. It brings together unified access to hundreds of large language models, smart routing, and centralized policy enforcement all in one place. A single gateway pod handles 250+ requests per second while adding approximately 3 ms of latency, making it production-grade from day one.
As AI adoption accelerates, the real challenge isn't accessing models it's managing the complexity that follows. Multiple providers, evolving APIs, and strict compliance requirements can quickly slow teams down. The TrueFoundry AI Gateway brings order to this complexity, serving as the control plane for enterprise AI. It unifies access, enforces policy, and delivers OpenTelemetry-compliant observability across every model and environment without requiring any changes to the applications calling the gateway.
Middleware is a full-stack observability platform built on OpenTelemetry as its core instrumentation standard. It accepts traces, logs, infrastructure metrics, and real user monitoring data through OTEL Collector, storing them in a single correlated data layer that gives engineering teams a complete picture of their systems in one place.
What sets Middleware apart is what it does after a trace arrives. Rather than storing spans in isolation, Middleware correlates them with infrastructure signals from the host or cluster where the service runs. An engineer investigating a latency spike in a gateway span can navigate directly from the trace view to CPU and memory metrics for that pod without switching dashboards. Middleware also builds a live service topology map from incoming span data, making every instrumented service visible as a node in the service map with latency and error rate computed automatically from its spans.
The integration of Middleware and the TrueFoundry AI Gateway simplifies and strengthens your AI observability. This combination makes it easy to bake production-grade visibility right into your AI workflow, ensuring your systems are observable from the moment of deployment.
With this integrated solution, every inference request that passes through the TrueFoundry AI Gateway automatically generates a structured set of OpenTelemetry spans. Those spans carry prompt content, completion content, token counts, model name, latency, and finish reason as queryable attributes then flow asynchronously to Middleware over OTLP/HTTP. Middleware ingests them alongside the rest of your infrastructure telemetry, making gateway traffic immediately visible as a first-class service in the topology map and APM views alongside the application services that call it.
For full control over sensitive data, the TrueFoundry gateway's Exclude Request Data toggle strips prompt and completion content from span attributes before export. Token counts, latency, and model metadata are retained regardless, so you keep complete operational visibility without exposing user inputs to external systems. For organizations with strict network egress requirements, the gateway exporter can also be pointed at a self-managed OpenTelemetry Collector that forwards to Middleware requiring no changes other than the endpoint URL.
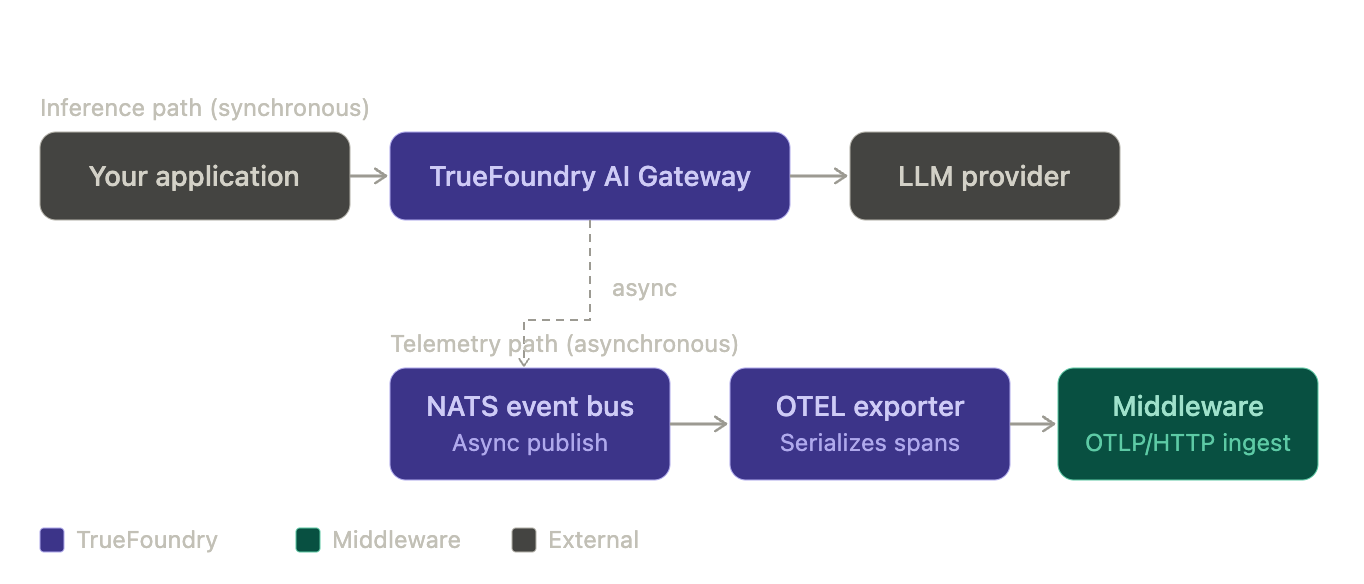
Middleware and TrueFoundry AI Gateway Integration
Middleware and the TrueFoundry AI Gateway work together to deliver observability without adding complexity to your inference path.
Configuration is just as easy. Navigate to AI Engineering → Settings → OTEL Config in the TrueFoundry dashboard, enter your Middleware tenant endpoint and API key, set the protocol to HTTP with protobuf encoding, and you're ready to go.
AI observability does not have to mean complex instrumentation work. With Middleware integrated into the TrueFoundry AI Gateway, your entire inference traffic becomes visible correlated with infrastructure signals, filterable by model name or token count, and mapped into a live service topology from the moment the configuration is saved. It's complete, production-grade observability that is easy to set up, more like flipping a switch than a custom engineering project.
To learn more, visit the Middleware documentation and the TrueFoundry integration reference to see how straightforward it is to get full-stack visibility into your AI applications.
Ready to get started? Connect your TrueFoundry gateway to Middleware today and turn every inference request into a structured, queryable observability event.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.







.png)
.webp)
.png)


.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)