




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026
Blazingly fast way to build, track and deploy your models!
In the world of microservices, we have perfected the art of CI/CD. Unit tests are deterministic: assert(2 + 2 == 4). If the tests pass, the code is safe to deploy.
In the world of Agentic AI, "Unit Tests" don't exist in the same way.
You cannot simply deploy an agent because the code compiles. The prompt is a Hyperparameter of Behavior. A minor tweak to the system prompt ("Be more concise") can cause a massive regression in reasoning capability ("The agent stopped checking for errors because it wanted to be concise").
To solve this, the TrueFoundry Agent Gateway supports Agent DevOps—a specialized lifecycle management layer that brings "Shadow Mode," "Online Evals," and "Canary Rollouts" to the cognitive stack.
Let’s look at a concrete example of why standard CI/CD fails for agents.
The Scenario: You have a Customer Support Agent in production. It’s polite and helpful. The Product Manager wants it to be more efficient. The Change: You update the System Prompt from "You are a helpful assistant" to "You are a concise, direct assistant. Do not waste words."
The Standard Deployment:
The Catastrophe: The agent interprets "direct" as "rude."
The Customer Satisfaction (CSAT) score crashes. You have tainted your brand because you treated a cognitive change like a code change.
The TrueFoundry Gateway supports Traffic Mirroring (Shadow Mode). Instead of replacing v1 with v2, we deploy v2 alongside v1.
The Gateway then compares the outputs asynchronously. You can run an "Auto-Eval" (using a Judge Model) to score the difference.
The dashboard alerts you: "v2 Empathy Regression Detected." You revert the deployment before a single customer sees the rude message.

Before an agent even reaches Shadow Mode, it must pass the Evaluation Pipeline. Just as you run pytest for code, you must run deepeval or ragas for cognition.
The TrueFoundry Registry treats "Evaluation Datasets" as first-class citizens.
When you push a Pull Request, the CI system spins up the agent and runs the 500 queries. Pass Criteria:
If the "Concise Prompt" causes the "Faithfulness" score to drop by 10%, the build fails. "Merge Blocked: Agent creates hallucinations."

Once the agent passes CI and Shadow Mode, you are ready for the real world. But you don't flip the switch to 100%. You use Canary Routing.
The Gateway creates a "Virtual Service" that splits traffic based on weights.
The Gateway automates this. If the "Error Rate" spikes at the 10% stage, the Gateway can help automatically roll back to v1 and pages the on-call engineer.
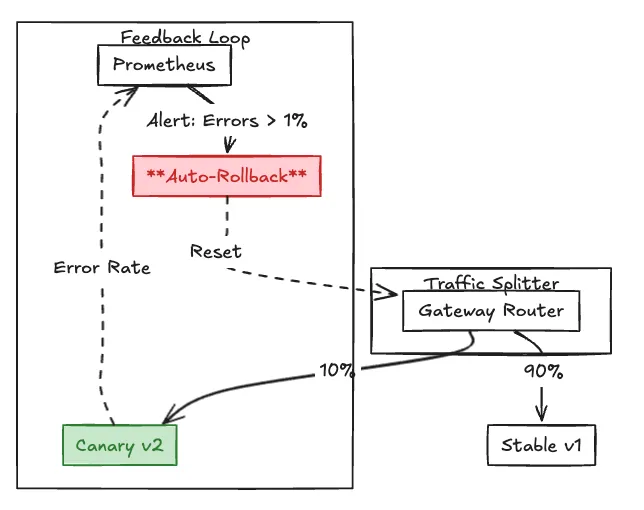
Fig 1: A Canary Rollout Example
أحد التحديات الرئيسية في DevOps للوكيل هو أن الموجه والتعليمات البرمجية غالبًا ما يتواجدان في أماكن مختلفة.
تفرض TrueFoundry سجل الوكلاءالمصنوعات غير القابلة للتغيير. عند النشر، نقوم بتجميع: معرف المصنوع = Hash(التعليمات البرمجية + الموجه + تهيئة النموذج + التبعيات)
لا يمكنك تغيير موجه الإصدار 1 في بيئة الإنتاج. يجب عليك إنشاء الإصدار 1.1. يضمن هذا التحديد الصارم للإصدارات قابلية الاستنساخ. إذا وقع حادث، فإنك تعرف بالضبط أي مزيج من التعليمات البرمجية والموجه تسبب فيه.
DevOps للوكيل هو الانضباط الذي يطبق الدقة الهندسية على البرمجيات الاحتمالية. من خلال الانتقال من "النشر القائم على الإحساس" (يبدو أسرع) إلى "النشر القائم على المقاييس" (الوضع الخفي أكد دقة أعلى بنسبة 5%)، تتيح TrueFoundry للمؤسسات الابتكار في موجهاتها بسرعة دون المساس بثقة مستخدميها.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
