



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
Blazingly fast way to build, track and deploy your models!
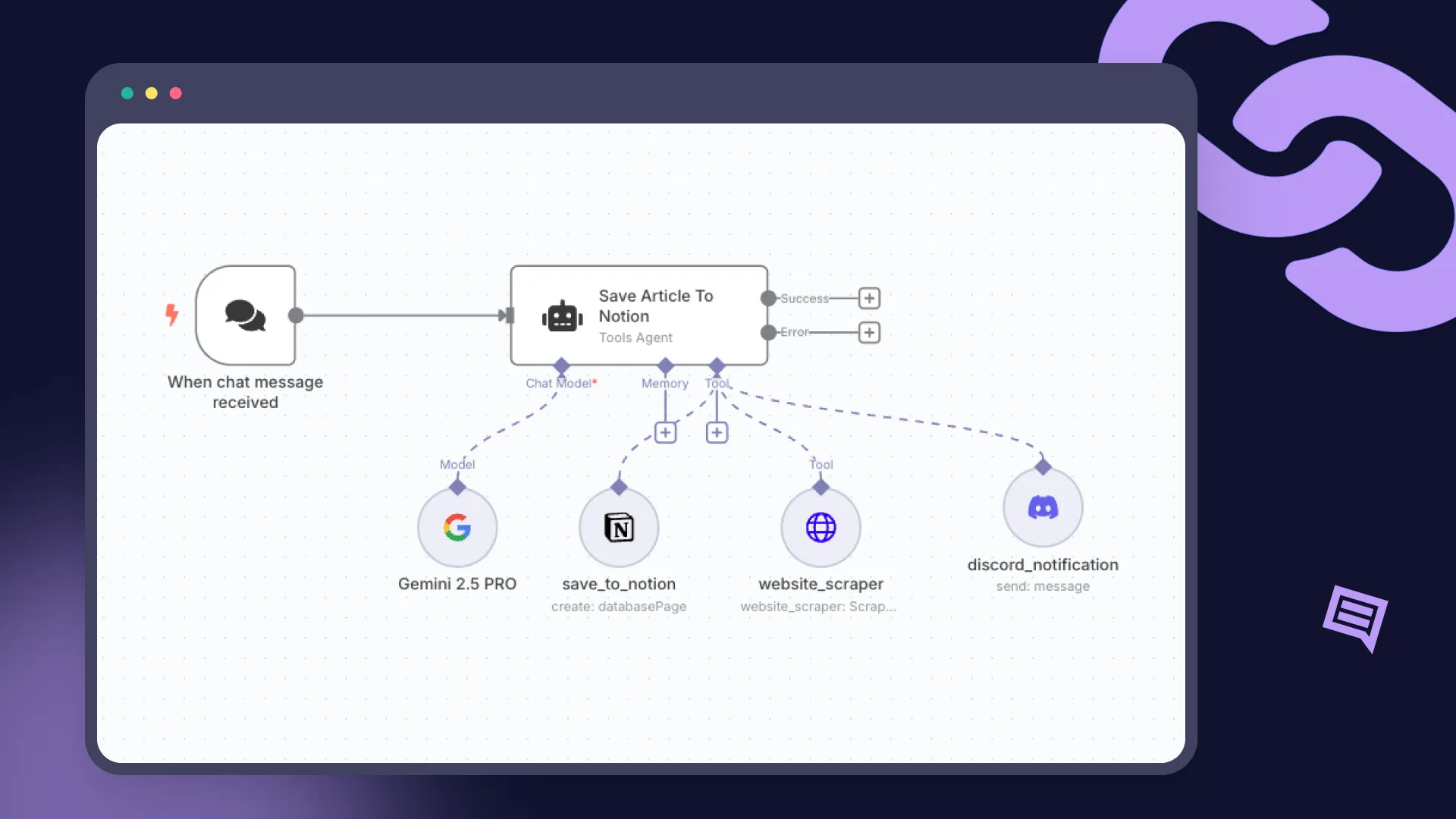
O n8n é popular por ser fácil de usar. Você arrasta nós para uma tela e cria automações rapidamente. Muitas equipes agora adicionam etapas de IA a esses fluxos, como redigir respostas ou resumir texto.
À medida que esses fluxos de trabalho são incorporados às operações diárias, surgem novos problemas. As chaves de API acabam em muitos lugares. Cada fluxo de trabalho pode chamar um fornecedor de modelo diferente. O financeiro recebe várias faturas. A segurança perde um único rastro de auditoria. A engenharia tem dificuldade em trocar modelos em dezenas de fluxos.
O TrueFoundry AI Gateway resolve isso. Ele se torna o único local que gerencia políticas, limites de custo, roteamento e logs para cada chamada de LLM. Os desenvolvedores continuam usando o n8n da mesma forma. A plataforma, a segurança e o financeiro obtêm o controle de que precisam.
Imagine um caso de uso comum: automação do suporte ao cliente. Em um fluxo de trabalho n8n, isso pode parecer simples. Um e-mail recebido é passado para um LLM para redigir uma resposta. O texto gerado é então enviado para um segundo modelo de análise de sentimento para sinalizar casos urgentes para revisão humana.
Mas quando essas chamadas de modelo são roteadas diretamente para os fornecedores, o caos se instala para as equipes de plataforma:
Ao rotear todo o tráfego do n8n através do TrueFoundry AI Gateway, todo o cenário muda. O Gateway atua como um plano de controle único e inteligente. Os agentes de suporte mantêm a velocidade de arrastar e soltar que tanto gostam, enquanto a organização obtém governança completa e controle de custos — eliminando os pontos cegos para cada chamada de LLM.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Conectar o n8n ao Gateway é uma configuração única que leva minutos.
Pré-requisitos:
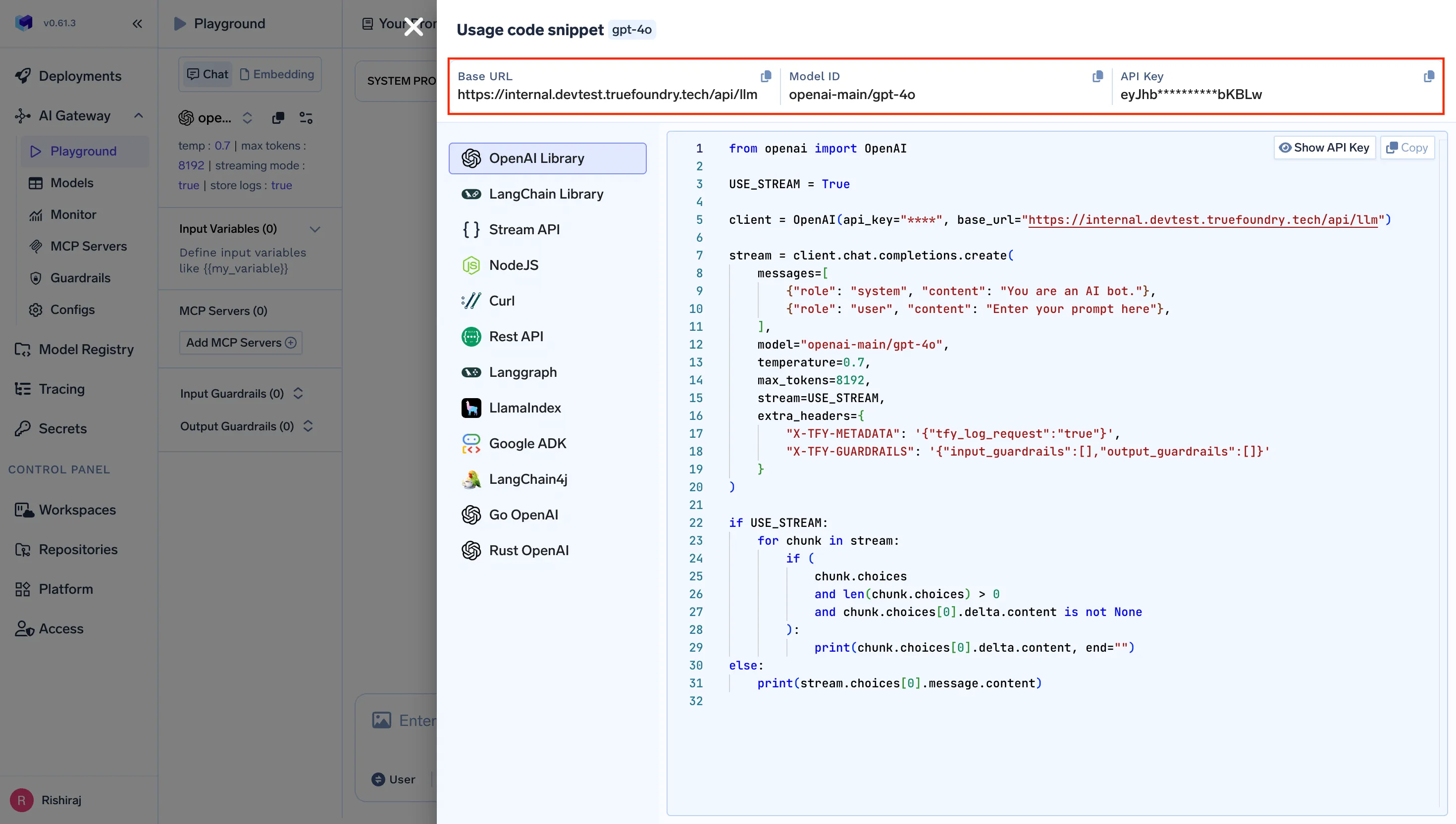
Passos:
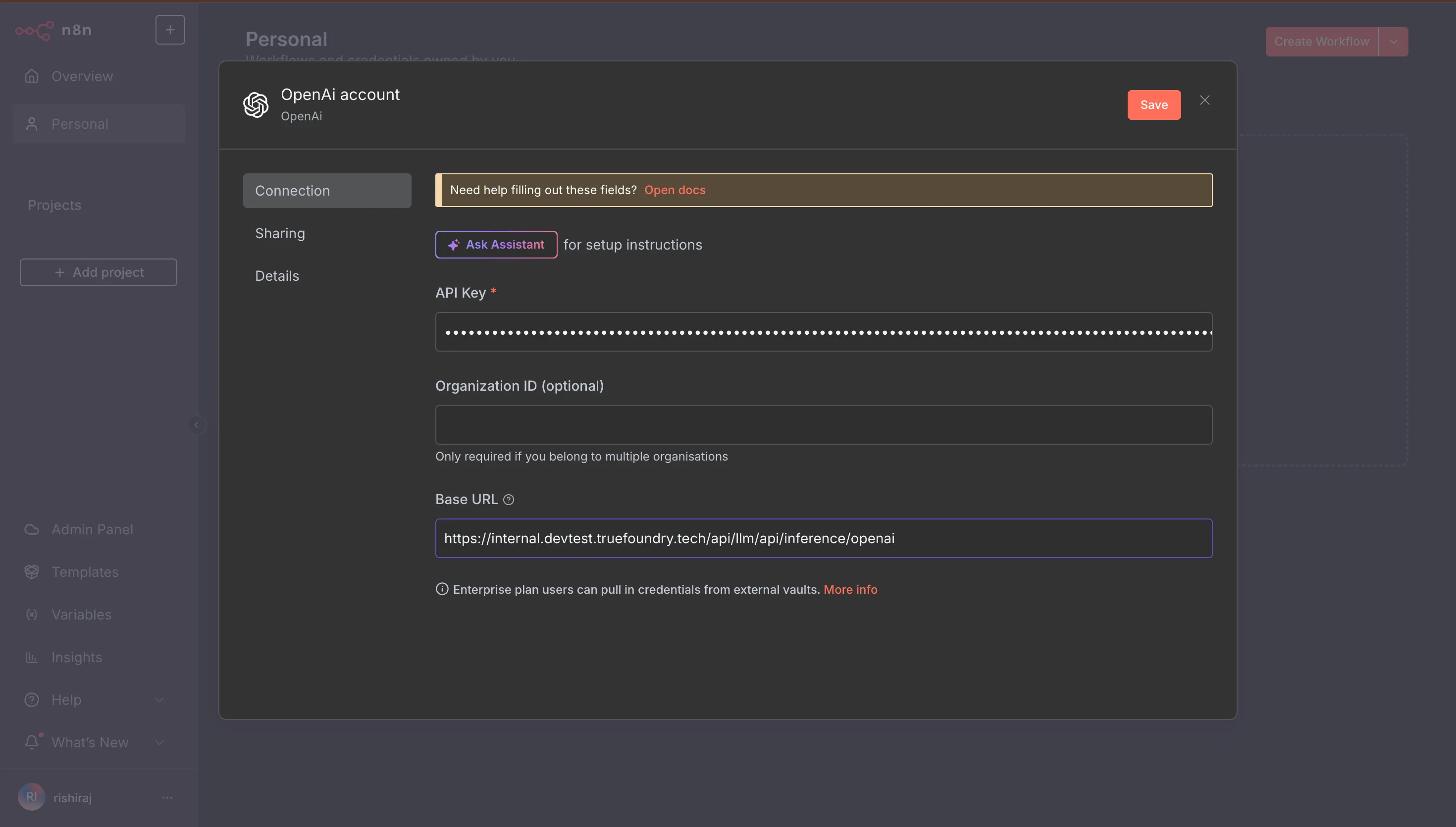
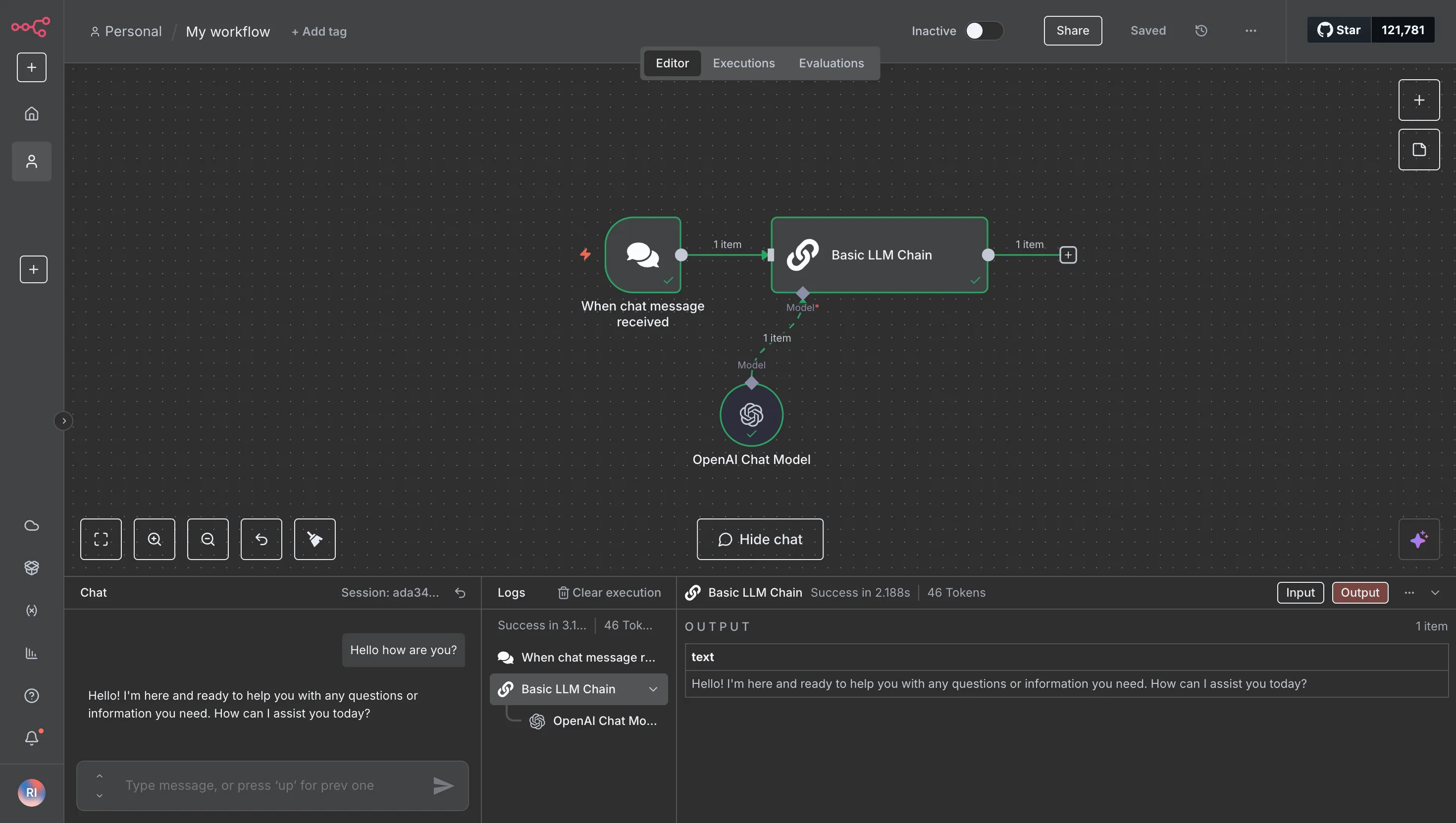
Execute seu fluxo de trabalho. Cada solicitação de LLM a partir desse momento será roteada através do TrueFoundry Gateway, proporcionando observabilidade imediata e aplicação de políticas.
Quando o n8n é executado através do TrueFoundry AI Gateway, sua organização obtém novas e poderosas capacidades sem alterar os fluxos de trabalho existentes. Ao centralizar o controle, o gateway oferece benefícios imediatos e tangíveis para observabilidade, segurança e governança financeira. Veja como isso se manifesta.
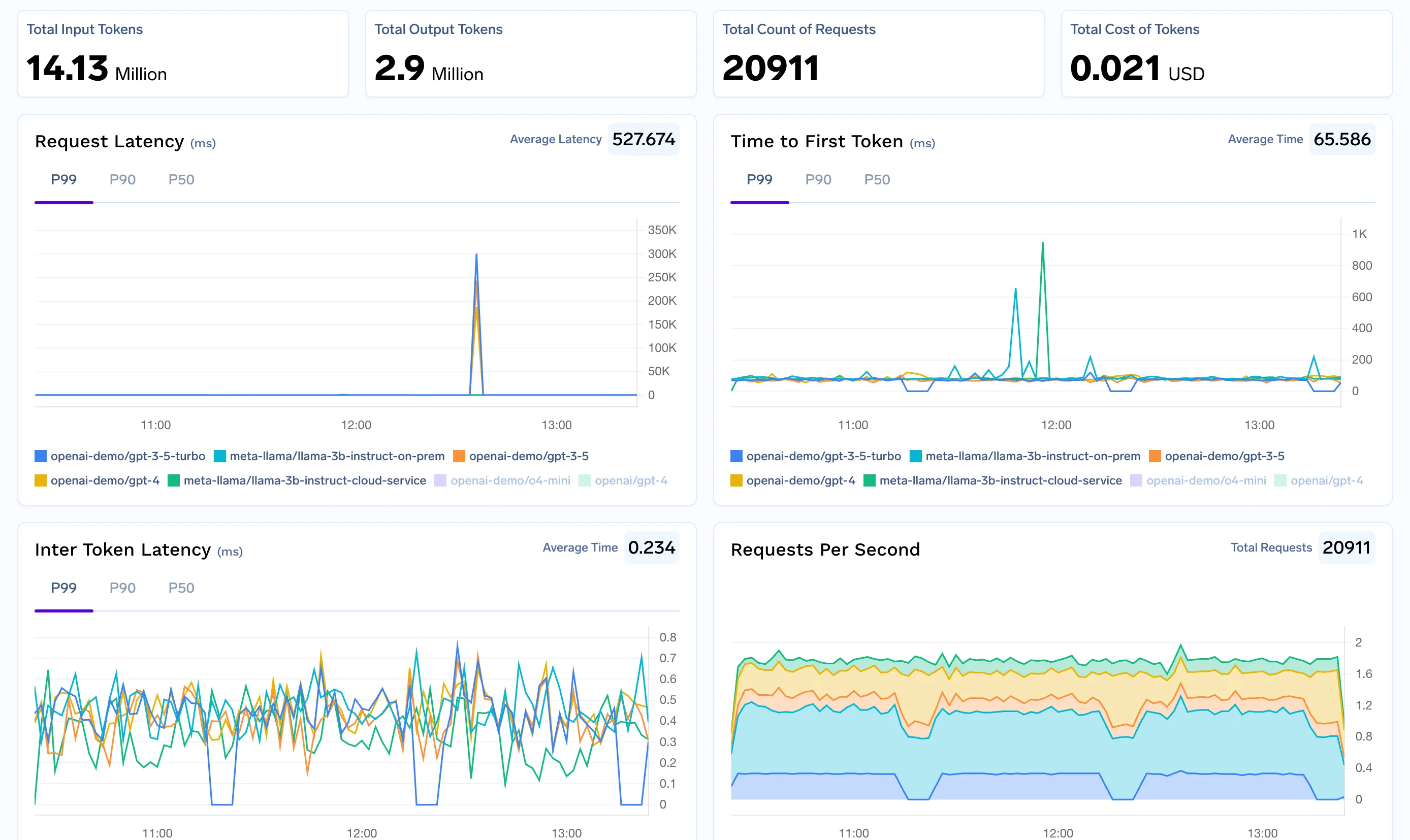
Para equipes de finanças e operações, obter visibilidade em tempo real dos gastos com IA é fundamental. O AI Gateway oferece uma solução abrangente para rastreamento de custos do n8n desde o primeiro dia.
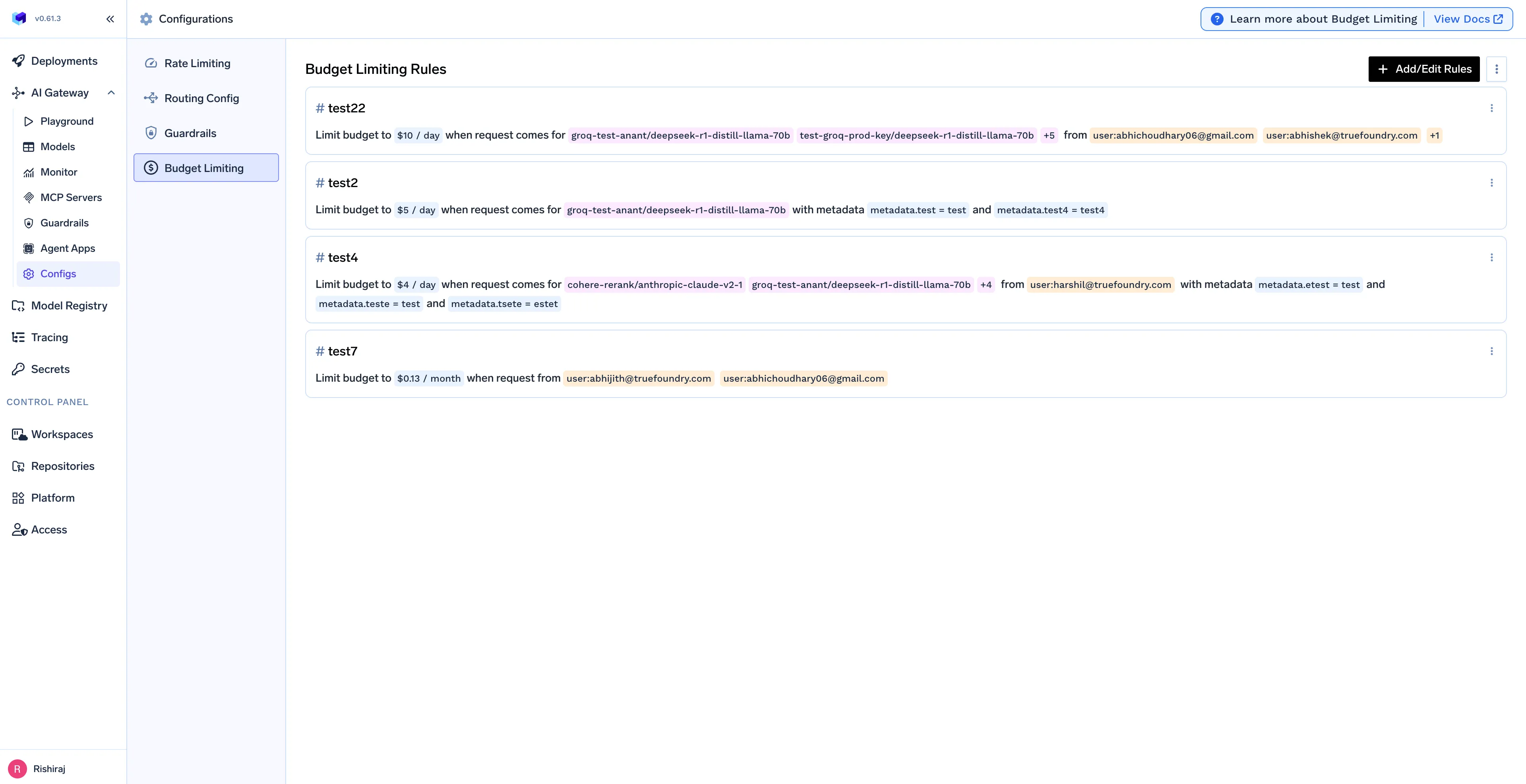
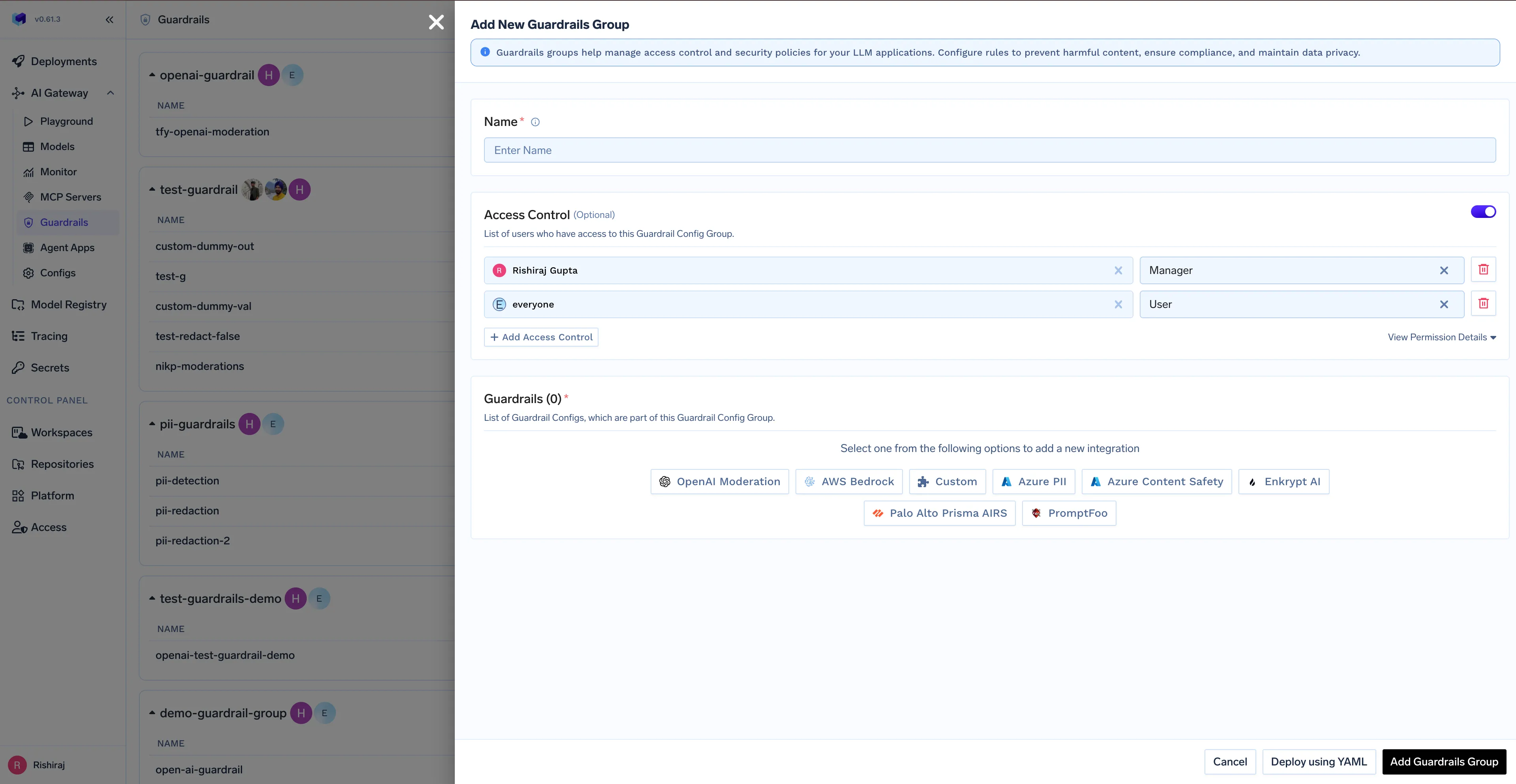
A segurança não pode ser deixada para depois. O AI Gateway atua como um ponto de controlo central, aplicando poderosas salvaguardas n8n a cada solicitação de LLM automaticamente, garantindo que seus dados e operações permaneçam seguros.
Equipes de engenharia de plataforma podem garantir a estabilidade do sistema e alto desempenho sem editar fluxos de trabalho individuais. O gateway oferece um plano de controle central para confiabilidade.
claude-3-haiku, enquanto a equipe de plataforma pode trocar a versão subjacente do modelo nos bastidores do gateway para implementar mudanças com segurança e sem tempo de inatividade.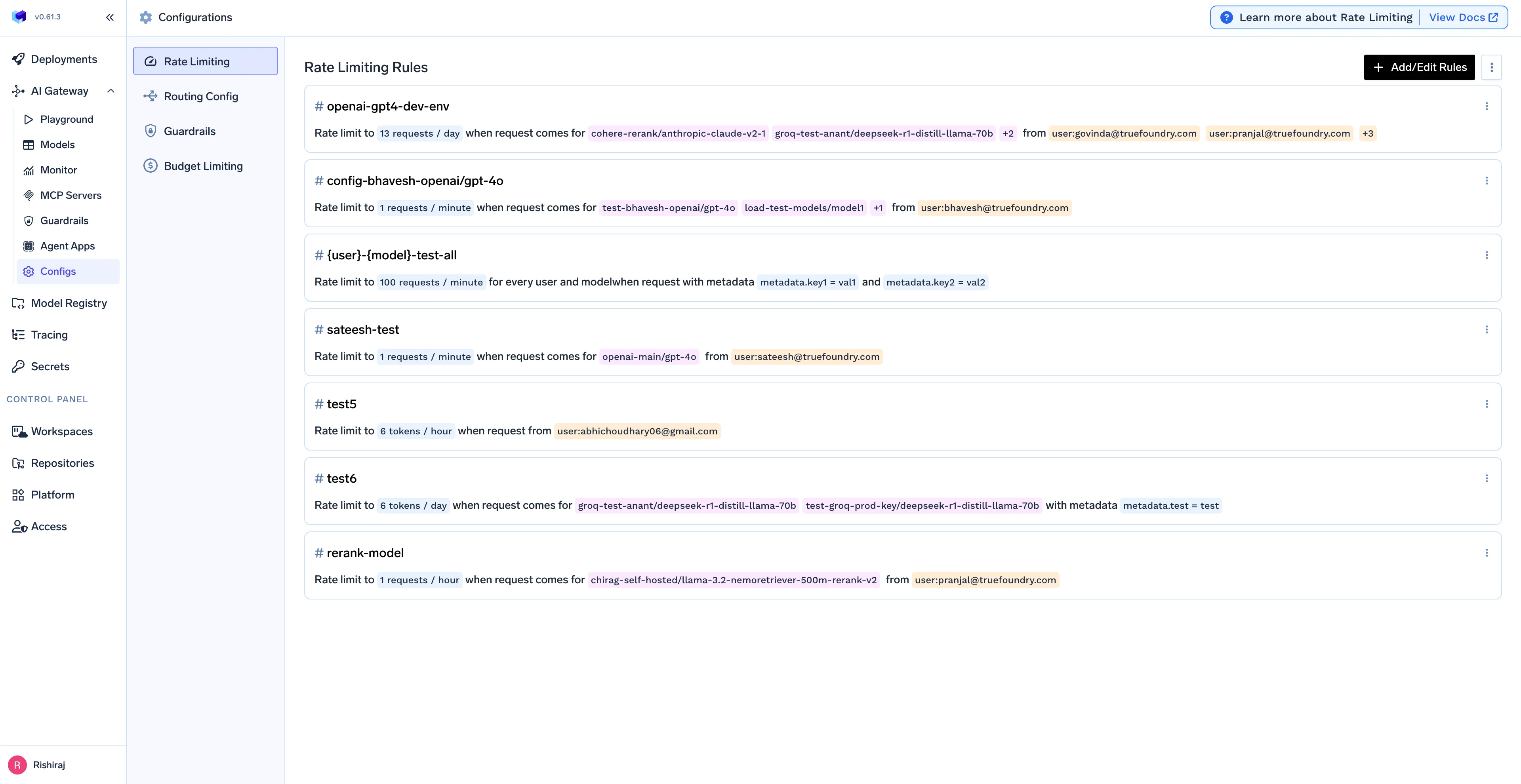
Para equipes de dados, análise e operações, depurar fluxos de trabalho de IA complexos pode ser um desafio. O gateway integra rastreamento n8n com rastreamento profundo do modelo para fornecer uma visão única e unificada da saúde do sistema.
Com esses elementos implementados, o setor financeiro obtém custos previsíveis, a segurança obtém trilhas de auditoria claras, as equipes de plataforma obtêm operações confiáveis e os desenvolvedores mantêm sua agilidade. É o caminho mais rápido para escalar o n8n com segurança, com rastreamento n8n em tempo real, logs n8n robustos e monitoramento de custos n8n simples e centralizado que funciona desde a primeira execução.
Este é apenas o começo. No próximo trimestre, a equipe TrueFoundry planeja aprofundar a integração para otimizar ainda mais a experiência do desenvolvedor. Seu feedback é crucial para guiar nosso roteiro. Sinta-se à vontade para entrar em contato conosco com suas solicitações de recursos.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




