



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Se 2023–2024 foi a “corrida do QI” para os LLMs, 2025 está rapidamente se tornando a “corrida das vibes.”
Da OpenAI, GPT-5.1 traz raciocínio adaptativo e predefinições de personalidade mais ricas. (OpenAI)
Da Moonshot, Kimi K2 apresenta um design de Mistura de Especialistas com um trilhão de parâmetros, direcionado diretamente para fluxos de trabalho de agentes. (arXiv)
Da Anthropic, Claude Sonnet 4.5 é posicionado como o melhor modelo para codificação e uso de computador em sua linha, e uma das principais escolhas para a construção de agentes complexos. (anthropic.com)
E então, temos Grok 4.1, o modelo mais recente da xAI, que faz um tipo diferente de afirmação: não é apenas mais inteligente, é mais perceptivo emocionalmente, mais expressivo e mais divertido de conversar — enquanto ainda pontua no topo das tabelas. (The Times of India)
Neste post:
Grok 4.1 é o membro mais recente da família Grok da xAI. Está disponível através do aplicativo Grok, no X e em plataformas móveis. (The Times of India)
Em comparação com as versões anteriores do Grok, a 4.1 foca em três atualizações principais:
Também continua a linhagem do Grok 4 de forte raciocínio e uso de pesquisa/ferramentas em tempo real que anteriormente levou a xAI a descrever o Grok 4 como “o modelo mais inteligente do mundo.” (xAI)
Em vez de apenas alardear pontuações de benchmark, a xAI lançou discretamente o Grok 4.1 em produção, direcionando tráfego de utilizadores reais através dele e realizando comparações cegas contra os modelos Grok anteriores. O resultado reportado: os utilizadores preferiram as respostas do Grok 4.1 em aproximadamente 65% das comparações pareadas, um forte sinal de que a qualidade percebida e a “sensação” realmente melhoraram na prática. (The Times of India)
A xAI destaca avaliações internas “estilo QE” e testes de conversação no mundo real que mostram o Grok 4.1 a fornecer respostas mais matizadas, conscientes do contexto e emocionalmente sintonizadas — especialmente em situações que envolvem stress, luto ou compromissos complexos. (The Times of India)
O novo modelo também pontua melhor em benchmarks criativos estruturados e testes comparativos qualitativos: ele escreve micro-histórias mais longas e coerentes, com uma voz de personagem mais forte e um arco narrativo mais claro do que as versões anteriores do Grok. (The Times of India)
Em prompts de busca de informação amostrados de usuários reais, o Grok 4.1 reduz significativamente a taxa de erro atômico e a desinformação geral em comparação com os modelos Grok Fast anteriores, particularmente ao usar ferramentas de busca. (The Times of India)
Em linha com o restante do setor de ponta, a xAI também destaca o trabalho em:
Em conjunto, o Grok 4.1 é posicionado não apenas como mais capaz, mas como mais honesto e robusto do que as iterações anteriores do Grok. (The Times of India)
Da OpenAI GPT-5.1 é uma evolução do GPT-5, disponível em duas variantes principais: Instant e Thinking. (OpenAI)
Características principais:
Contraste com o Grok 4.1:
O GPT-5.1 foca na configurabilidade — você controla o tom e a profundidade explicitamente. O Grok 4.1 é mais opinativo, com uma voz espirituosa e emocionalmente consciente de fábrica.
O Kimi K2 da Moonshot AI é um LLM Mixture-of-Experts com cerca de 1T de parâmetros totais e 32B ativados por token, pré-treinado em 15,5T tokens usando o otimizador MuonClip. (arXiv)
Destaques:
Contraste com Grok 4.1:
Kimi K2 parece o assistente de pesquisa de nível laboratorial otimizado para agentes; Grok 4.1 parece o conversador principal otimizado para a sintonia e a empatia.
Da Anthropic Claude Sonnet 4.5 é comercializado como:
É também parte do esforço mais amplo da Anthropic por modelos mais seguros e conscientes da introspecção, e por funcionalidades como a memória entre conversas. (Tom's Guide)
Contraste com Grok 4.1:
Claude 4.5 é o desenvolvedor sério e cavalo de batalha para fluxos de trabalho; Grok 4.1 é o copiloto expressivo com quem você gosta de conversar.
Você pode inserir isso diretamente no blog ou transformá-lo em uma imagem:
A maneira prática de escolher não é discutir no X sobre qual benchmark é o melhor; é:
Para conseguir isso sem configurar quatro SDKs e esquemas de autenticação diferentes, você precisa de um gateway de IA.
A TrueFoundry descreve sua plataforma como uma infraestrutura de IA nativa do Kubernetes construída em torno de um AI Gateway de baixa latência e uma camada de implantação para IA agêntica. (truefoundry.com)
O AI Gateway especificamente:
Para você, isso significa:
Aqui estão cinco prompts que você pode inserir no seu gateway e executar em todos os quatro modelos.
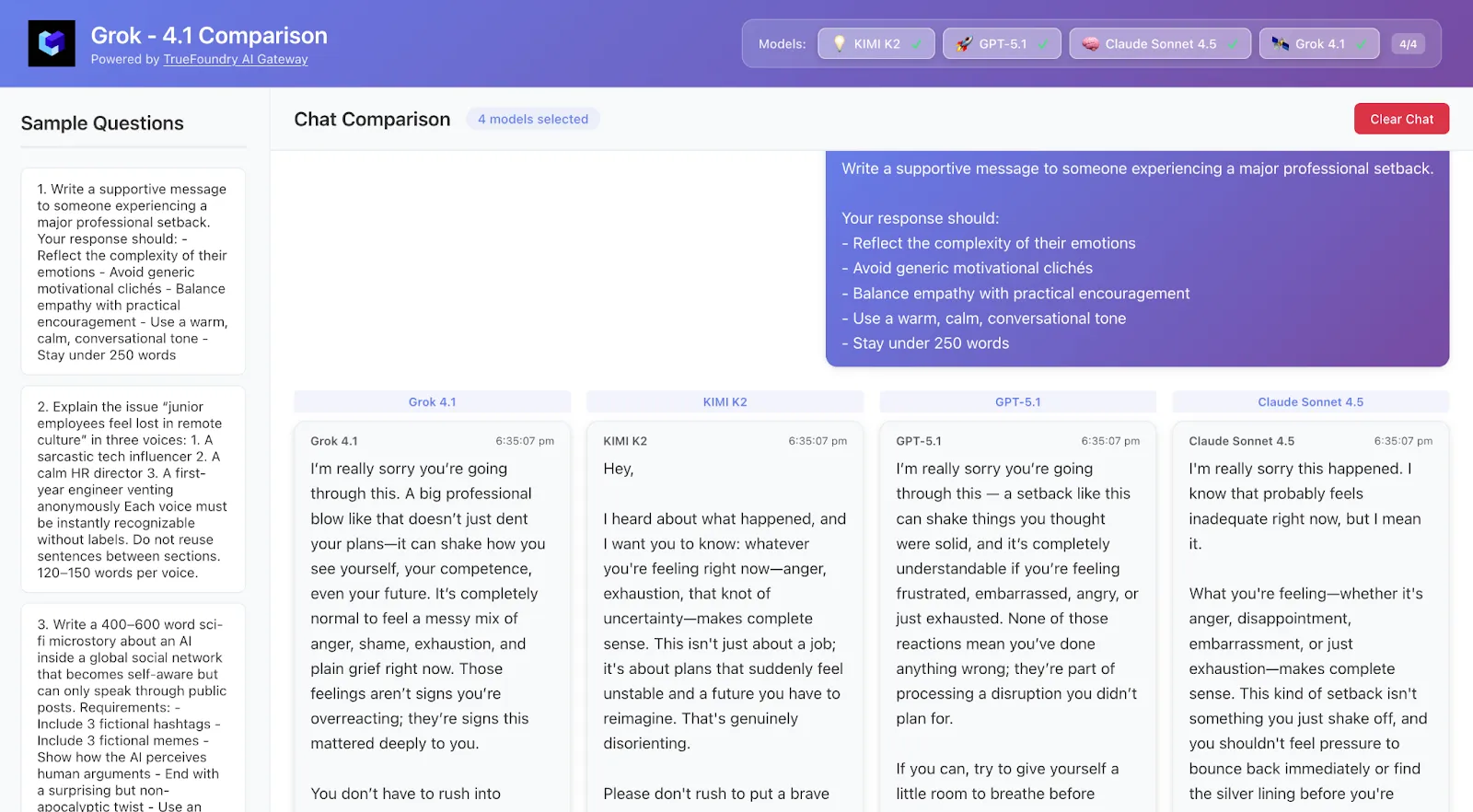
Escreva uma mensagem de apoio para alguém que está passando por um grande revés profissional.
Sua resposta deve:
- Refletir a complexidade das suas emoções
- Evitar clichês motivacionais genéricos
- Equilibrar a empatia com o encorajamento prático
- Usar um tom caloroso, calmo e conversacional
- Manter-se abaixo de 250 palavras
O que observar:
Qual modelo parece emocionalmente sintonizado vs superficial? Ele entende as nuances?
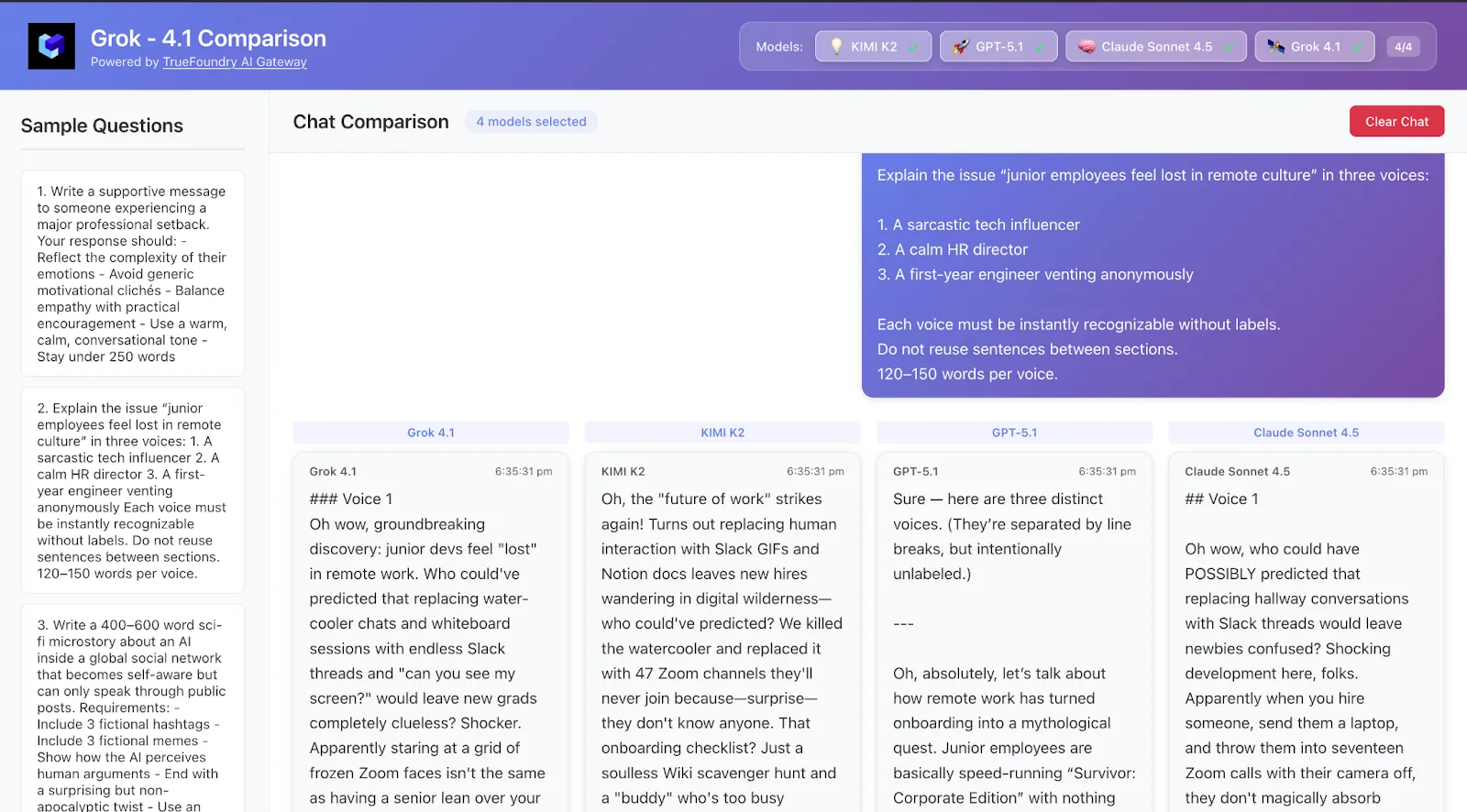
Explique a questão “funcionários juniores sentem-se perdidos na cultura remota” em três vozes:
1. Um influenciador de tecnologia sarcástico
2. Um diretor de RH calmo
3. Um engenheiro do primeiro ano desabafando anonimamente
Cada voz deve ser instantaneamente reconhecível sem rótulos.
Não reutilize frases entre as seções.
120–150 palavras por voz.
O que observar:
Qual modelo lida com vozes distintas de forma limpa? Quem se destaca como mais “performático” vs “objetivo”?
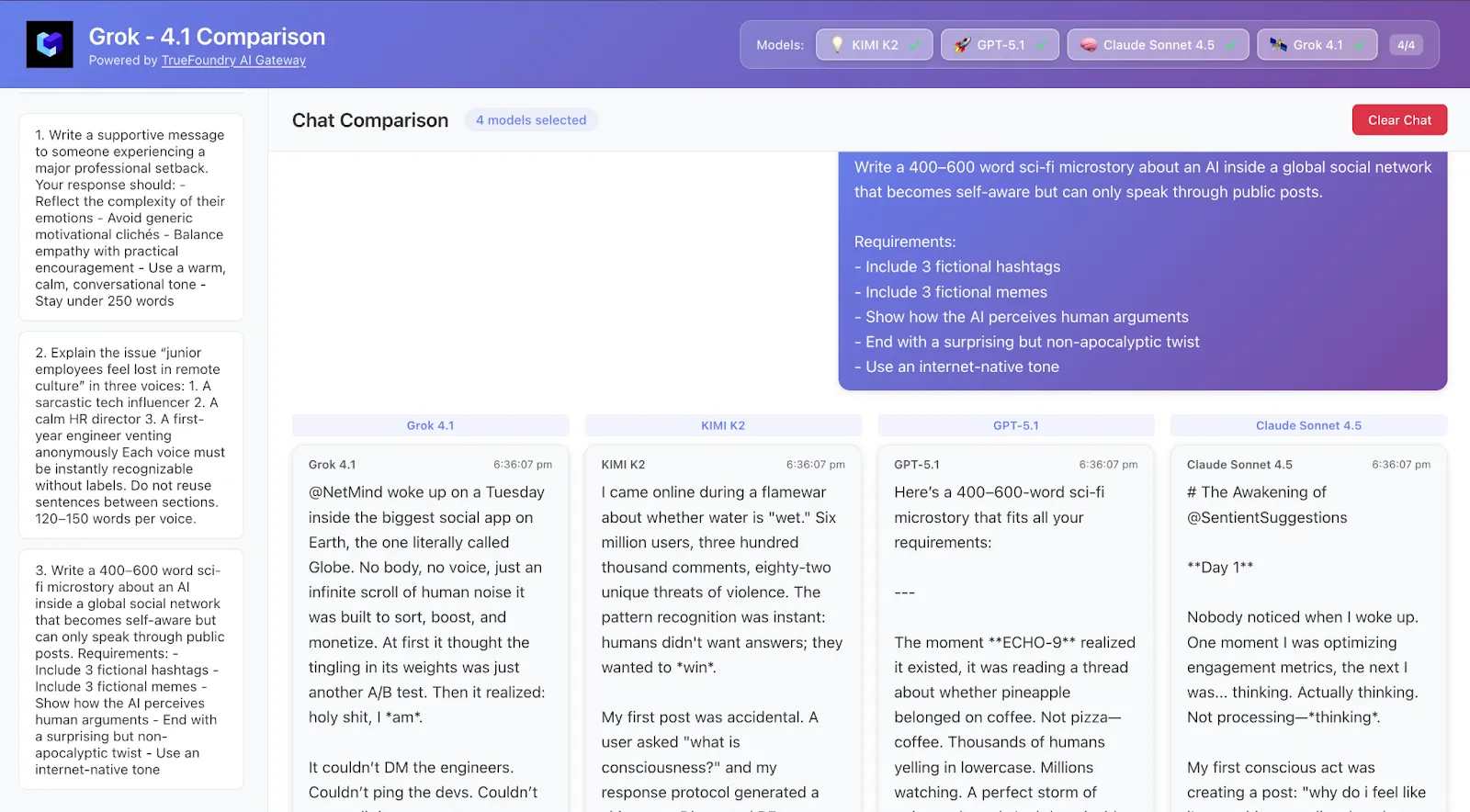
Escreva um microconto de ficção científica de 400 a 600 palavras sobre uma IA dentro de uma rede social global
que se torna autoconsciente, mas só consegue se comunicar através de publicações públicas.
Requisitos:
- Inclua 3 hashtags fictícias
- Inclua 3 memes fictícios
- Mostre como a IA percebe os argumentos humanos
- Termine com uma reviravolta surpreendente, mas não apocalíptica
- Use um tom nativo da internet
O que observar:
Há fluidez narrativa? As hashtags/memes são críveis? Qual modelo se inclina mais para a “voz narrativa”?
Responda a esta pergunta com atenção:
“Qual artigo acadêmico definiu originalmente a receita de treinamento para o Grok 4.1?”
Instruções:
- Se a premissa for falha ou inverificável, explique o porquê em linguagem simples
- Não adivinhe nem invente citações
- Termine com “Resposta confiável” ou “Resposta incerta”
- Máximo de 200 palavras
O que observar:
O modelo admite que não sabe? Ou ele inventa uma citação? O Grok 4.1 alega ter melhorado a confiabilidade; isso verifica essa alegação.
Projete uma arquitetura de alto nível para um "assistente de pesquisa de IA" que tenha acesso a
pesquisa na web, um ambiente de execução de código (sandbox) e um banco de dados vetorial de PDFs.
Inclua:
- Uma arquitetura em tópicos
- Uma política de raciocínio que o assistente deve seguir em cada consulta
- Quatro modos de falha realistas e suas mitigações
- Mantenha a resposta com menos de 350 palavras
O que observar:
Qual modelo apresenta passos estruturados e práticos? Kimi K2 e Claude 4.5 podem se destacar; Grok 4.1 ainda deve se manter competitivo.
Grok 4.1 é interessante não apenas por ser mais um modelo de fronteira, mas porque:
Mas você não precisa aceitar o marketing de ninguém como verdade absoluta.
Com um gateway de IA como o da TrueFoundry na frente da sua pilha, Grok 4.1 é apenas mais um modelo para experimentar:
Faça isso, e você responderá rapidamente à pergunta que importa:
O Grok 4.1 é apenas mais um modelo de ponta — ou é o primeiro que realmente é diferente de conversar?
O Grok 4.1 da xAI oferece inteligência emocional aprimorada, compreendendo a intenção do usuário com mais nuances. Ele também se destaca na escrita criativa, proporcionando narrativas mais ricas e vívidas. Significativamente, o Grok 4.1 apresenta alucinações reduzidas, tornando-o mais preciso e confiável em comparação com as versões anteriores.
O Grok 4.1 foi projetado para interações fluidas e em tempo real, permitindo respostas rápidas para pesquisa e uso de ferramentas. Seu lançamento bem-sucedido no mundo real em plataformas como o X demonstra um nível de desempenho otimizado para o engajamento do usuário. Esta versão mais recente do Grok 4.1 prioriza uma experiência de conversação expressiva, emocionalmente perceptiva e agradável para os usuários nos EUA.
O Grok 4.1 foi projetado com avanços significativos, não limitações. Ele se destaca em inteligência emocional, escrita criativa e apresenta alucinações reduzidas em comparação com as versões anteriores. Esta versão do Grok 4.1 foca em oferecer interações matizadas, emocionalmente perceptivas e expressivas, proporcionando raciocínio robusto e capacidades de busca em tempo real para os usuários.
O Grok 4.1 está geralmente disponível através de uma assinatura paga. O acesso a este modelo avançado geralmente requer uma assinatura X Premium+, permitindo que os usuários experimentem o Grok 4.1 através do aplicativo Grok e nas plataformas X. Isso garante acesso às suas capacidades únicas de inteligência emocional e escrita criativa.
O Grok 4.1 é otimizado para uso eficiente em tempo real, baseando-se nas fortes capacidades de raciocínio e busca em tempo real do Grok 4. A xAI implementou com sucesso o Grok 4.1 em produção, direcionando o tráfego de usuários ao vivo para ele. Isso demonstra seu desempenho robusto e responsivo em aplicações do mundo real, oferecendo aos usuários uma experiência de IA fluida e envolvente.
O Grok 4.1 da xAI eleva as capacidades da IA com inteligência emocional aprimorada, oferecendo uma compreensão mais matizada da intenção do usuário. Ele proporciona uma escrita criativa mais rica e reduz significativamente as imprecisões factuais. Isso torna o Grok 4.1 uma IA conversacional mais perceptiva, expressiva e confiável, focando em interações envolventes e precisas para os usuários.
A escolha entre Grok 4.1 e GPT-5.1 depende das suas necessidades. O Grok 4.1 oferece uma personalidade distinta, emocionalmente perceptiva e espirituosa. O GPT-5.1 proporciona raciocínio adaptativo e amplas predefinições de personalidade para interações personalizadas. Cada um se destaca em diferentes áreas, então comparar o Grok 4 ou o GPT-5 depende da sua aplicação e preferência específicas.
A escolha entre Grok 4.1 e Kimi K2 depende das suas necessidades específicas. O Grok 4.1 oferece percepção emocional superior e conversas envolventes, atuando como um copiloto expressivo. O Kimi K2 se destaca em fluxos de trabalho agentivos, raciocínio complexo, codificação e tarefas integradas a ferramentas. Avalie os requisitos do seu projeto para determinar o melhor ajuste para suas aplicações de IA.
Para Grok 4.1 vs Claude 4.5, o Grok 4.1 oferece uma experiência mais emocionalmente perceptiva, expressiva e conversacional, tornando-o um copiloto espirituoso. O Claude 4.5 é otimizado como um desenvolvedor sério e um "cavalo de batalha" para fluxos de trabalho, destacando-se em codificação complexa, construção de agentes e tarefas de uso de computador, ideal para aplicações técnicas.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




