



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Já passamos da fase de "veja esta demonstração legal" da IA de Voz. As empresas não estão mais apenas criando habilidades fofas para a Alexa. Elas estão implementando sistemas complexos e multimodais, projetados para lidar com milhões de interações sensíveis com clientes — desde transferências bancárias até triagem de saúde.
Mas aqui está a verdade incômoda sobre a transição da IA de Voz do protótipo para a produção: ela é incrivelmente frágil.
Ao contrário dos chatbots baseados em texto, onde uma falha é apenas uma resposta de texto ruim, uma falha na IA de Voz é visceral. É silêncio total. É uma voz robótica gaguejando. É um cliente gritando "agente!" repetidamente porque a latência na consulta RAG demorou 400ms demais e o ASR o interrompeu.
Quando você está orquestrando uma pilha complexa e extensa envolvendo Reconhecimento Automático de Fala (ASR), classificação complexa de intenções, Geração Aumentada por Recuperação (RAG) baseada em agentes e Síntese de Fala (TTS) realista, as ferramentas padrão de monitoramento de aplicações (APMs) são lamentavelmente inadequadas. Elas dizem a você que algo quebrou, mas raramente o porquê.
Este artigo abordará um caso de uso empresarial realista e em larga escala para demonstrar por que a observabilidade especializada é inegociável e como plataformas como a TrueFoundry estão emergindo como o plano de controle para esses sistemas complexos.
Para entender o desafio da observabilidade, precisamos primeiro olhar para a "fera" que estamos tentando domar. Um agente de voz conversacional moderno não é um modelo único; é uma corrida de revezamento de componentes altamente especializados, muitas vezes distribuídos por diferentes infraestruturas.
Se qualquer etapa nesta corrida de revezamento falhar, toda a experiência do usuário é comprometida.
Vamos imaginar a Apex Financial, um grande banco implementando um assistente de voz para lidar com transações de nível médio, como verificar saldos em diferentes classes de ativos e iniciar transferências internacionais.
A Escala: 50.000 chamadas simultâneas durante horários de pico.
Os Riscos: Elevados. Interpretar "cinquenta" como "sessenta" por engano durante uma transferência é catastrófico.
A Pilha de Tecnologia:
Uma cliente, "Sarah", liga. Ela tem um leve ruído de fundo e diz: "Preciso enviar 5 mil para meu irmão em Londres das minhas economias."
Veja como esse fluxo de trabalho se parece e onde as coisas geralmente dão errado.
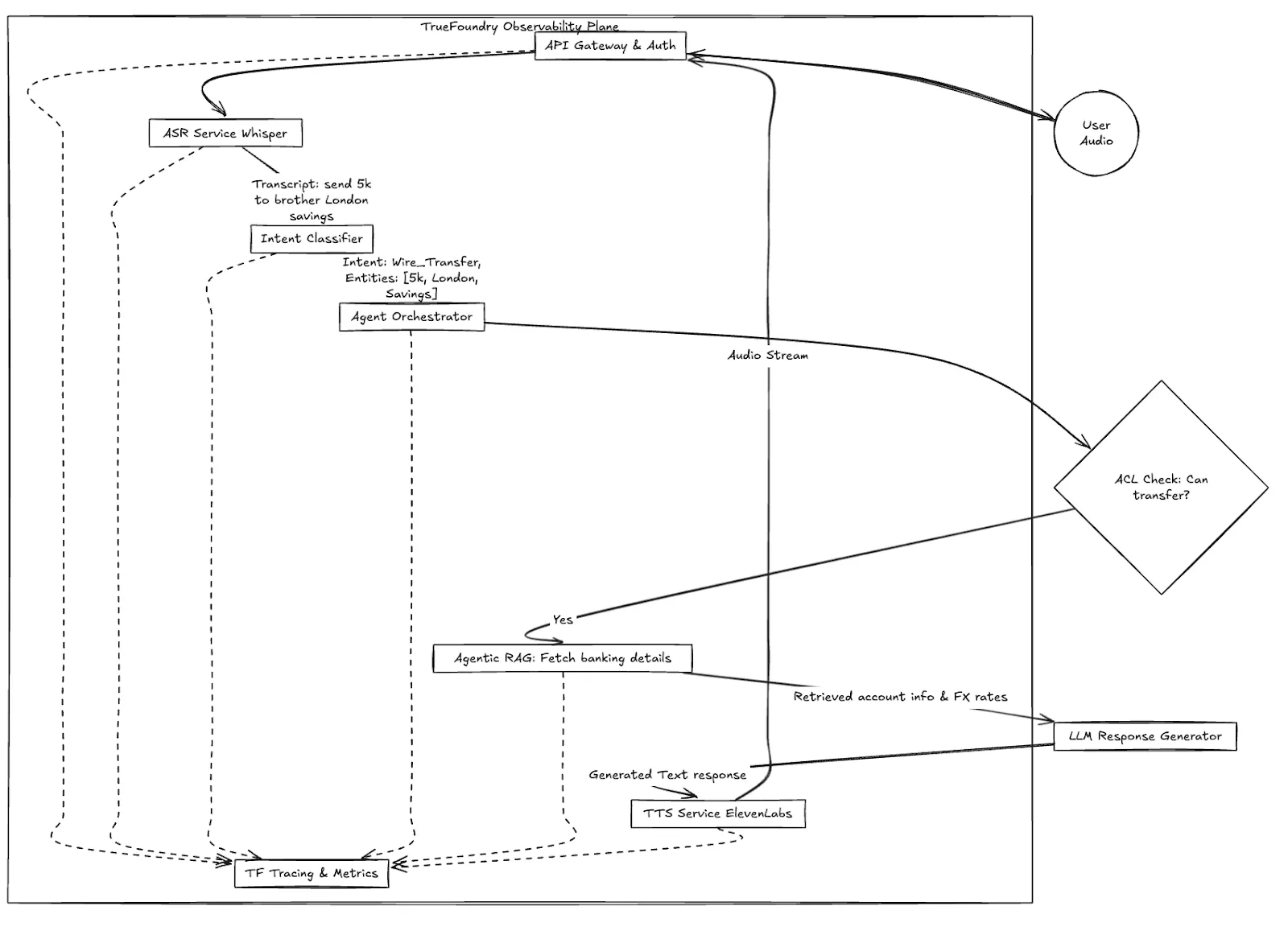
Fig 1: Fluxo de Trabalho de Alto Nível da Transação de Voz da Apex Financial, mostrando o papel crítico do Plano de Observabilidade.
Numa configuração padrão, se a chamada de Sarah falhar, a equipa de engenharia recebe um ticket a dizer "O bot de voz desligou."
Eles verificam o Datadog ou o Prometheus. A CPU está bem. A memória está bem. Os pods do Kubernetes estão ativos. O que aconteceu?
Sem observabilidade especializada de IA de Voz, depurar isso é como resolver um mistério de labirinto sem ferramentas forenses.
Num sistema de IA de Voz distribuído, a latência é cumulativa. Um atraso de 200ms no ASR mais um atraso de 400ms no RAG resulta numa experiência do cliente falhada. É necessário um rastreamento que compreenda os quadros de áudio, e não apenas os pedidos HTTP.
É aqui que plataformas como a TrueFoundry se tornam essenciais. A TrueFoundry não é apenas mais um painel de monitorização; é uma plataforma de infraestrutura e observabilidade de IA/ML construída especificamente para as complexidades das pilhas GenAI, incluindo voz.
A TrueFoundry trata toda a cadeia — desde o primeiro pacote de áudio até ao fluxo TTS final — como um fluxo observável.
Veja como ela aborda as necessidades críticas das empresas que as ferramentas genéricas não conseguem atender:
O rastreamento padrão mostra os tempos de salto de serviço para serviço. O rastreamento especializado da TrueFoundry permite visualizar o orçamento de latência de uma conversa em tempo real.
Pode ver que, para a chamada da Sarah, o ASR demorou 350ms (aceitável), mas a etapa RAG Agente demorou 2,1 segundos (inaceitável). Pode aprofundar imediatamente a etapa RAG: Foi a recuperação da base de dados vetorial? Foi o modelo de reclassificação?
Deixa de adivinhar e começa a corrigir o gargalo.
Quando a sua IA de Voz utiliza um agente para tomar decisões (como verificar se a Sarah tem fundos suficientes antes de perguntar pelo destino), precisa de auditar o "processo de pensamento" do agente.
A TrueFoundry oferece observabilidade nas etapas intermédias do agente. Não está apenas a ver a entrada e a saída; está a ver as ferramentas que o agente selecionou, as consultas que executou na base de dados vetorial e o contexto bruto que recuperou. Se o bot der uma resposta errada, pode ver exatamente qual pedaço de dados desatualizados ele recuperou do sistema RAG que causou a alucinação.
No setor bancário, "quem pode fazer o quê" é fundamental. Não pode permitir que o seu bot de voz de marketing aceda acidentalmente ao agente de transações.
A TrueFoundry fornece Listas de Controlo de Acesso (ACL) robustas que governam quais modelos e agentes podem interagir. Além disso, à medida que os sistemas multiagente crescem, a TrueFoundry está a adotar padrões como o Protocolo de Contexto de Modelo (MCP) para garantir uma comunicação autenticada e segura entre diferentes agentes de IA dentro do seu ecossistema.
A observabilidade aqui não é apenas desempenho; é auditoria de segurança. Precisa de um registo que prove porquê O Agente A teve o acesso negado à Fonte de Dados B durante uma chamada ao vivo.
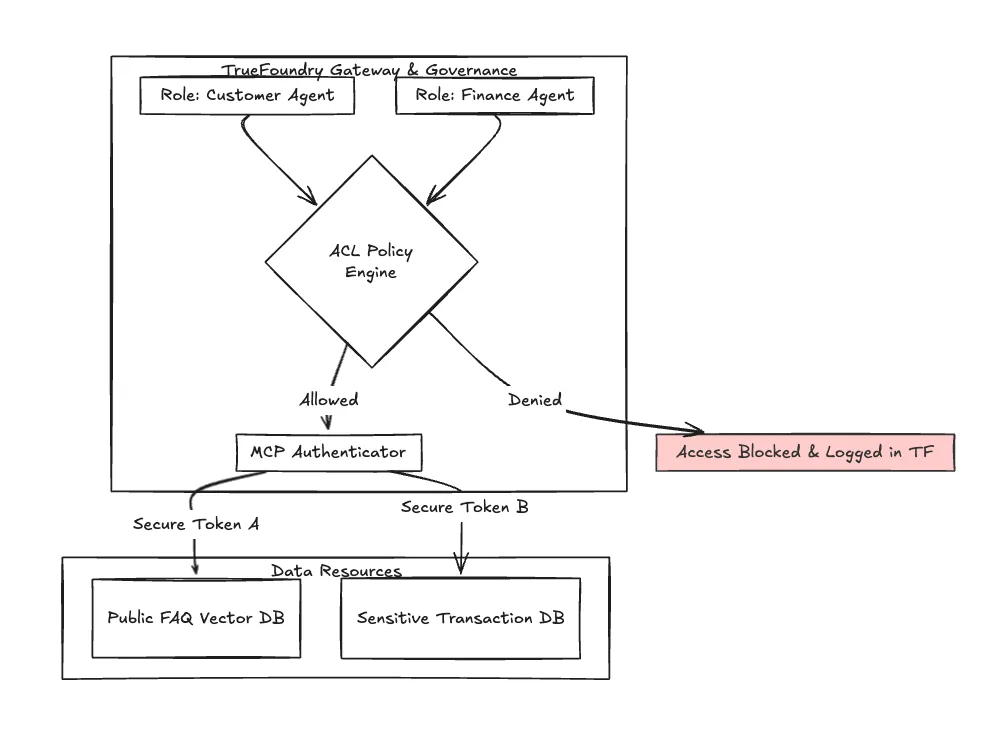
Fig. 2: Visão simplificada do fluxo de autenticação ACL e MCP gerenciado dentro do ecossistema TrueFoundry, garantindo o isolamento de agentes de voz sensíveis.
Para resumir a diferença entre o monitoramento padrão e o que é necessário para IA de voz empresarial:
Tabela 1: Comparação entre APM Padrão vs. Profundidades de Observabilidade da IA de Voz TrueFoundry.
Para a Apex Financial, a implantação do TrueFoundry significou a diferença entre reverter seu programa de assistente de voz e escalá-lo. Eles passaram de um Tempo Médio Para Detecção (MTTD) de horas para minutos. Eles puderam identificar proativamente que um modelo de embedding RAG específico estava causando picos de latência durante períodos de alto volume antes que os clientes começassem a desligar.
Ao construir IA de Voz empresarial, os modelos que você escolhe — Whisper, ElevenLabs, GPT-4o — são apenas o motor. A observabilidade é o sistema de aviônicos. Você não deveria tentar pilotar um jato apenas com um velocímetro; não tente operar uma pilha de voz empresarial sem observabilidade profunda e especializada.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




