

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 27, 2026
%20(10).webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !

Dans cet exemple, nous formons un modèle qui permet de classer une fleur du genre iris dans l'une des trois espèces en fonction des mesures de la taille de ses pétales et de ses sépales.
Vous pouvez également suivre cet exemple sur Carnet Google Colaboratory.
Le Ensemble de données Iris contient trois espèces différentes :
Nous devons créer un classificateur capable d'identifier l'espèce de la fleur en fonction des paramètres suivants :
True Foundry fournit deux bibliothèques pour simplifier vos flux de travail de machine learning :
fonderie ml la bibliothèque est utilisée pour suivre les expériences d'entraînement ML.
Pourquoi avez-vous besoin d'un suivi des expériences ? Si vous entraînez plusieurs modèles de machine learning pour résoudre un problème, vous entraînerez probablement plusieurs modèles avec plusieurs frameworks, hyperparamètres et plusieurs ensembles de données. Suivi de votre expérience à l'aide d'une bibliothèque telle que fonderie ml peut vous aider à organiser vos expériences de machine learning.
Vous pouvez utiliser MLFoundry pour enregistrer les hyperparamètres, les métriques, les ensembles de données et les modèles. Vous pouvez ensuite comparer différentes expériences sur le Tableau de bord TrueFoundry et choisissez un modèle à déployer en production ou décidez de le réentraîner.
Dans cet exemple, nous utiliserons 5 API différentes de MLFoundry. Ils sont les suivants :
À l'aide du fonderie de service bibliothèque, vous pouvez facilement empaqueter, conteneuriser et déployer un modèle dans un cluster Kubernetes.
Ouvrez un bloc-notes IPython : vous pouvez utiliser Jupyter exécuté localement sur votre machine ou utiliser un bloc-notes Google Colab qui s'exécute sur le cloud.
Installez les bibliothèques requises.
Connectez-vous à TrueFoundry. Créez et copiez une clé API depuis la page des paramètres. Utilisez cette clé API pour initialiser le client MLFoundry et créer une exécution. Un run est une entité qui représente une expérience unique.
Récuérez le jeu de données Iris à l'aide du sklearn data ensembles module. Nous le divisons ensuite en ensembles de données de test et d'entraînement.
Jetons un coup d'œil aux noms des cibles. Nous l'utiliserons pour établir une correspondance entre la sortie entière du modèle et les noms réels des espèces.
Initialisez un modèle. Utilisez ensuite MLFoundry pour enregistrer les paramètres du modèle et créer des balises pour cette expérience en cours.
Ensuite, nous entraînons le modèle sur notre ensemble de données de trains. Une fois la formation terminée, nous calculons les différentes métriques et les enregistrons dans MLFoundry à l'aide de log_metrics.
Si nous sommes satisfaits des scores de précision et des autres indicateurs, nous pouvons choisir de déployer le modèle actuel. Pour cela, nous devons enregistrer le modèle et copiez l'identifiant d'exécution actuel.
Vous pouvez voir toutes vos courses et comparer les statistiques grâce au Tableau de bord de suivi des expériences TrueFoundry.

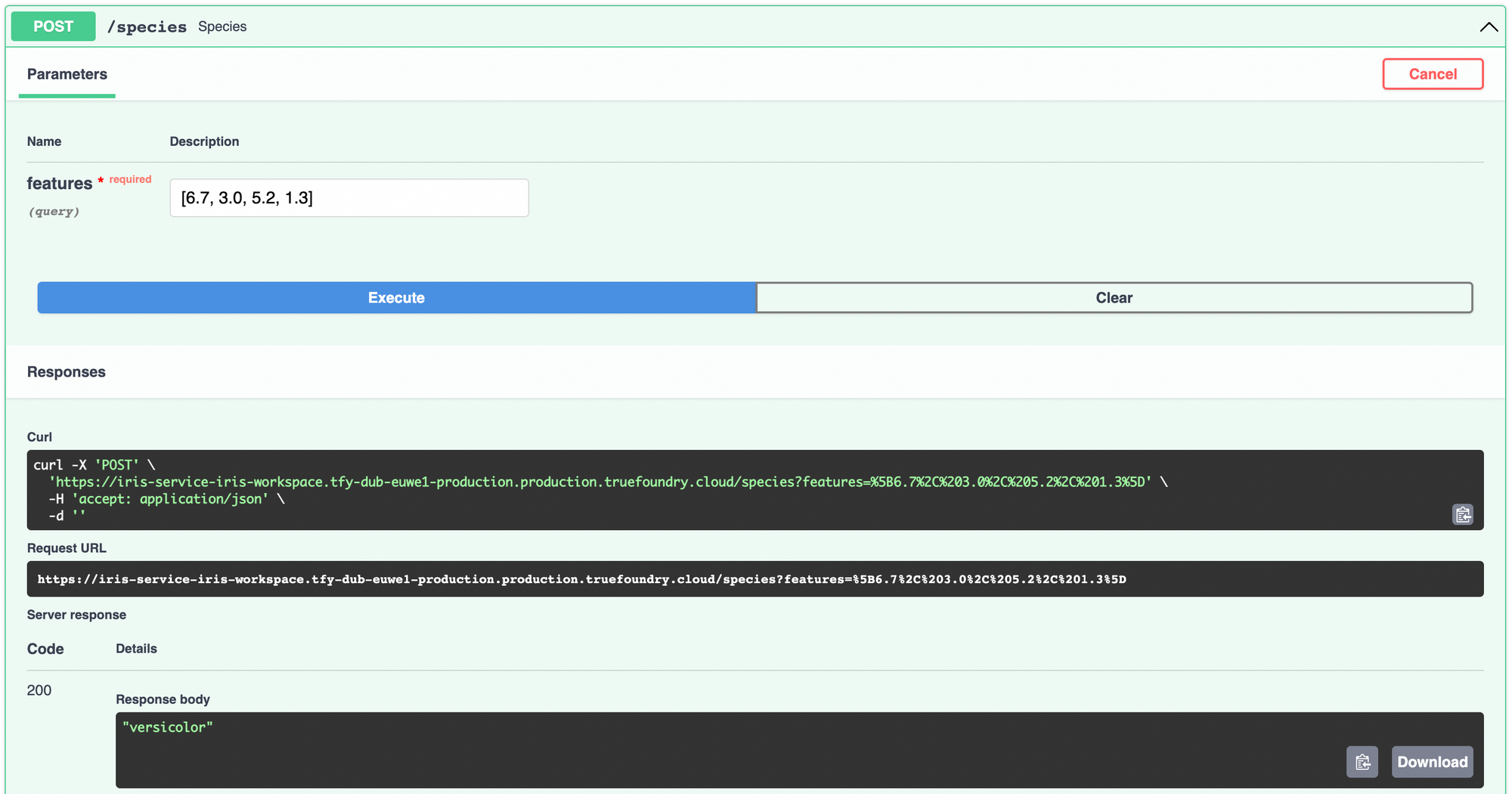
Pour déployer le modèle à l'aide de ServiceFoundry, nous devons créer un fichier Python contenant la fonction que nous voulons exposer en tant que point de terminaison.
Dans ce fichier Python, nous allons récupérer le modèle que nous venons d'entraîner et d'enregistrer à l'aide de l'identifiant d'exécution, en utilisant fonderie ml. Notez que la clé API est requise par fonderie ml sera disponible en tant que variable d'environnement TFY_API_KEY.
Dans votre bloc-notes IPython, créez un bloc avec le contenu suivant et exécutez-le pour créer un fichier Python nommé predict.py. Nous utilisons la commande magique Jupyter %%writefile for create the file in the environment of bloc-notes.
Dans la fonction d'espèce, nous chargeons les caractéristiques dans un pandas DataFrame et effectuez la prédiction à l'aide du modèle. Nous traduisons de la classe entière en noms d'espèces à l'aide du nom_cibles nous avons imprimé pendant l'entraînement.
C'est à peu près tout le travail que vous aurez à faire. Déployons maintenant ce modèle en tant que service d'API. Tout d'abord, installez et importez fonderie de service in ton carnet. Connectez-vous à fonderie de service.
Accédez au Tableau de bord TrueFoundry et créez un espace de travail pour déployer le service. Les espaces de travail sont un moyen de regrouper des projets connexes au sein de TrueFoundry. Une fois l'espace de travail créé, copiez le FQN pour que nous puissions le savoir fonderie de service où déployer le modèle.

fonderie de service la bibliothèque vous permet de rassembler toutes les dépendances du fichier que vous venez de créer à l'aide de exigences du collectionneur fonction.
Creez now a SFY.Service object, fournissez le FQN de l'espace de travail et déployez-le en appelant .déployer ()
Vous pouvez suivre la progression de ce déploiement sur tableau de bord. Une fois le déploiement terminé, vous pouvez accéder au service déployé à partir de là et l'essayer.
Le tableau de bord TrueFoundry contient également des liens vers des métriques et des journaux prêts à l'emploi avec les déploiements TrueFoundry sous la forme de tableaux de bord Grafana. You can know more to their topic ici.

Vous pouvez également déployer facilement des applications d'interface utilisateur interactive et des applications Gdio à partir d'un bloc-notes IPython en utilisant fonderie de service. Lisez ceci guide pour voir comment.
Nous nous efforçons de rendre l'intégration entre le suivi des expériences et le déploiement encore plus étroite et de rendre l'expérience plus agréable. Vous pouvez en savoir plus sur les autres choses que vous pouvez faire avec TrueFoundry sur nos documents.Si vous entraînez des modèles d'apprentissage automatique pour résoudre un problème, TrueFoundry vous aide à suivre différentes expériences et permet de déployer facilement et intuitivement des modèles conformes aux meilleures pratiques et de les mettre à la disposition du public en quelques minutes.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


