

May 23, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 8, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles linguistiques (LLM) sont devenus l'épine dorsale des applications d'IA modernes, alimentant tout, des chatbots aux assistants virtuels, en passant par les outils de recherche et les solutions d'entreprise. Cependant, tous les LLM ne sont pas créés de la même manière : chacun possède des forces, des limites et des facteurs de coût uniques. Certains excellent dans le raisonnement, tandis que d'autres sont plus doués pour l'écriture créative, le codage ou la gestion de requêtes structurées. C'est là qu'un Routeur LLM entre.
Un routeur LLM agit comme un contrôleur de trafic intelligent, dirigeant automatiquement les instructions de l'utilisateur vers le modèle le plus approprié en fonction de la tâche à accomplir. Au lieu de s'appuyer sur un modèle unique, les entreprises et les développeurs peuvent optimiser les performances, la précision et les coûts en acheminant les requêtes vers le LLM approprié en temps réel. À mesure que l'adoption de l'IA augmente, le routage LLM devient une couche essentielle pour créer des systèmes d'IA évolutifs, fiables et efficaces.
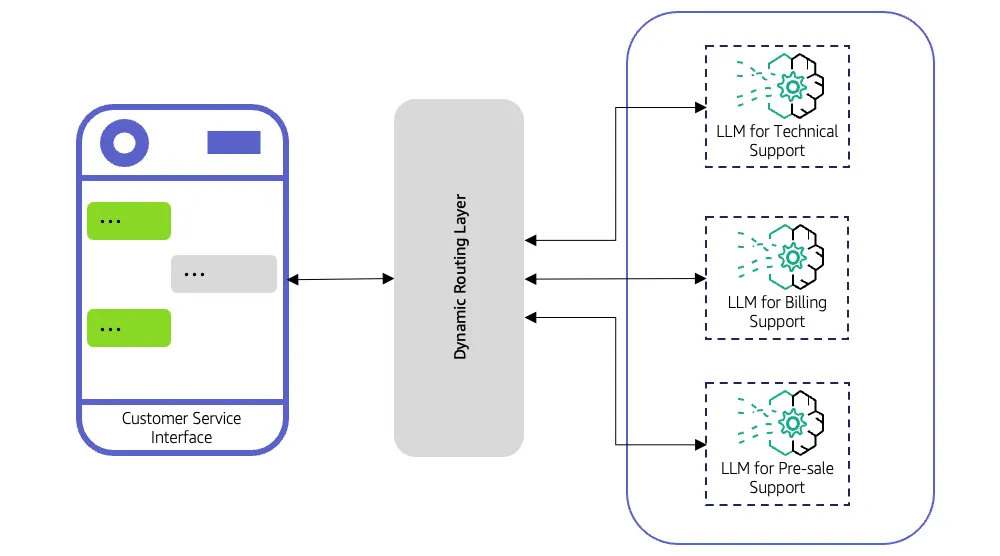
Un routeur LLM décide quel modèle de langage large doit gérer chaque demande. Au lieu d'envoyer chaque requête à un seul modèle, il évalue l'entrée, applique une logique de routage et la transmet au modèle le plus approprié.
Le routeur peut suivre des règles simples, telles que diriger les requêtes liées au code vers un modèle axé sur la programmation, ou utiliser des stratégies avancées telles que des classificateurs, des intégrations ou des modèles prédictifs légers pour déterminer quel LLM fournira la meilleure réponse.
Comment ça marche
Cette approche élimine le problème de la « solution universelle ». Les modèles légers gèrent efficacement les requêtes de routine, tandis que les tâches complexes ou nécessitant beaucoup de raisonnement sont confiées à des LLM plus compétents.
Concrètement, le routeur se situe entre les applications et plusieurs LLM, optimisant ainsi les performances, réduisant les coûts et minimisant la dépendance à l'égard d'un fournisseur unique. Cette configuration garantit que chaque demande atteint le bon modèle tout en préservant la fiabilité et la flexibilité des systèmes d'IA.
Les entreprises font de plus en plus appel à de grands modèles linguistiques pour des tâches allant des chatbots et des assistants virtuels à la création de contenu et à l'analyse de données.
L'utilisation d'un seul LLM pour toutes les tâches pose toutefois des défis. Certains modèles répondent rapidement mais manquent de profondeur, tandis que d'autres fournissent des résultats précis avec une latence et un coût élevés. Sans aucun moyen de gérer ces différences, les équipes font constamment des compromis entre performance, précision et budget.
Un routeur LLM résout ce problème en dirigeant intelligemment les demandes vers le modèle le mieux adapté à la tâche.
Envisagez ce scénario :
Un système de support client reçoit deux types de requêtes.
Une simple demande comme « Quels sont tes horaires de travail ? » n'a pas besoin d'un modèle très avancé, contrairement à une question technique complexe concernant le dépannage des produits. Sans routeur LLM, toutes les requêtes peuvent être adressées à un modèle puissant et coûteux. Cela augmente les coûts et ralentit les temps de réponse. Avec un routeur, la requête simple est dirigée vers un modèle rapide et léger, tandis que la requête complexe est acheminée vers un LLM plus performant, optimisant ainsi la vitesse, les coûts et la précision.
Avantages pour les entreprises
En acheminant intelligemment les requêtes, les entreprises fournissent des services d'IA plus rapides, plus précis et plus rentables. Les routeurs LLM transforment le déploiement de l'IA d'une approche universelle en un système flexible, fiable et efficace, ce qui les rend essentiels pour une infrastructure d'IA moderne.
Un routeur LLM est bien plus qu'un simple directeur de trafic, il fournit plusieurs fonctions essentielles qui rendent les systèmes d'IA plus intelligents, plus rapides et plus fiables. La compréhension de ces fonctions aide les organisations à concevoir des flux de travail d'IA qui évoluent efficacement tout en préservant la qualité.
Avant tout routage, le routeur analyse les requêtes entrantes. Il examine les métadonnées, les balises, le type de requête, la complexité et parfois l'intention ou le sentiment. Cette analyse fournit un contexte permettant au routeur de décider quel modèle est le mieux adapté pour traiter la demande. Par exemple, une question d'un client concernant la facturation peut être acheminée vers un LLM léger à usage général, tandis qu'une requête de dépannage technique est envoyée à un modèle spécifique au domaine.
Le routeur sélectionne le modèle le plus approprié en fonction de plusieurs critères, notamment :
En tenant compte de ces facteurs, le routeur s'assure que chaque demande obtient le meilleur équilibre entre vitesse, précision et coût.
Lorsque plusieurs modèles peuvent gérer la même tâche, le routeur distribue les demandes de manière intelligente pour éviter de surcharger un seul modèle. Cela améliore la réactivité globale du système et garantit des performances constantes pendant les pics d'utilisation.
Même les meilleurs modèles peuvent échouer, s'arrêter ou renvoyer des réponses peu fiables. Le routeur met en œuvre des mécanismes de repli, redirigeant automatiquement les requêtes vers les modèles de sauvegarde. Cela garantit la continuité et la fiabilité sans interruption pour l'utilisateur.
Les routeurs avancés suivent les modèles d'utilisation, les performances des modèles et les résultats des requêtes. Ces informations aident les équipes à optimiser les stratégies de routage, à sélectionner les meilleurs modèles et à réduire les coûts au fil du temps.
Un routeur LLM fait office de centre de prise de décision pour les systèmes d'IA multimodèles. En analysant les demandes, en sélectionnant le bon modèle, en équilibrant la charge, en gérant les défaillances et en fournissant des informations, il garantit que chaque requête est traitée de manière efficace, précise et fiable. Cette combinaison de fonctions fait des routeurs LLM un composant essentiel pour créer des solutions d'IA robustes, évolutives et rentables.
Les routeurs LLM utilisent différentes stratégies pour diriger efficacement les requêtes vers le modèle de langage le plus approprié. Ces stratégies se répartissent généralement en trois catégories : statiques, dynamiques et hybrides, les systèmes avancés intégrant parfois l'apprentissage par renforcement.
Le routage statique repose sur des règles prédéfinies pour décider quel modèle gère une requête. Il garantit un comportement de routage cohérent et est facile à mettre en œuvre.
Le routage dynamique s'adapte en temps réel, en sélectionnant les modèles en fonction des performances actuelles du système et du contexte des requêtes.
Les stratégies hybrides combinent des approches statiques et dynamiques pour une flexibilité et une efficacité accrues.
Certains systèmes avancés utilisent l'apprentissage par renforcement pour améliorer en permanence les décisions de routage. Ces routeurs tirent les leçons des requêtes passées et des performances des modèles, optimisant ainsi le routage au fil du temps pour les charges de travail complexes ou évolutives.
Un routeur LLM offre plusieurs avantages clés qui rendent les systèmes d'IA plus efficaces, fiables et rentables. L'un des principaux avantages réside dans l'optimisation des performances.
En acheminant intelligemment chaque requête vers le modèle le mieux adapté à la tâche, le routeur garantit que des modèles puissants et capables de raisonner traitent des questions complexes, tandis que des modèles légers et plus rapides traitent les demandes les plus simples. Cette approche concilie rapidité et précision, améliorant ainsi l'expérience utilisateur globale.
Un autre avantage important est la rentabilité. Sans routeur, les entreprises peuvent exécuter toutes les requêtes via des modèles puissants, ce qui augmente inutilement les coûts d'exploitation. Le routeur garantit que les modèles coûteux sont réservés aux requêtes complexes ou de grande valeur, tandis que les tâches de routine ou répétitives sont gérées par des modèles moins gourmands en ressources, ce qui réduit les dépenses de calcul et maximise le retour sur investissement.
La fiabilité s'améliore également avec un routeur LLM. Les routeurs avancés incluent des mécanismes de secours qui redirigent automatiquement les requêtes si un modèle échoue, expire ou renvoie des résultats peu fiables. Cela garantit des performances constantes et fiables, évitant les interruptions dans les applications en temps réel telles que le support client ou les assistants virtuels.
De plus, les routeurs LLM offrent de la flexibilité. Les organisations peuvent intégrer plusieurs modèles provenant de différents fournisseurs, en choisissant celui qui convient le mieux à chaque tâche.
Cela réduit la dépendance à l'égard d'un fournisseur unique et permet aux équipes d'expérimenter différents modèles à mesure que de nouvelles fonctionnalités apparaissent.
Enfin, les routeurs prennent en charge l'évolutivité. À mesure que les volumes de requêtes augmentent, le routeur distribue les demandes de manière intelligente entre les modèles, évitant ainsi les surcharges et préservant des performances optimales du système.
En combinant un routage optimisé, des économies de coûts, une fiabilité, une flexibilité et une évolutivité, un routeur LLM transforme les déploiements d'IA d'une approche rigide à modèle unique en un système dynamique, efficace et résilient.
Les routeurs LLM sont de plus en plus utilisés dans les entreprises pour optimiser les performances, la fiabilité et l'efficacité de l'IA. Ils permettent un routage intelligent des requêtes, garantissant que le bon modèle gère chaque tâche en fonction de sa complexité, de son domaine et de son contexte.
Automatisation du support client
Les entreprises traitent quotidiennement des milliers de demandes de clients, qu'il s'agisse de simples questions fréquentes ou de problèmes techniques complexes. Les routeurs LLM orientent les questions de routine vers des modèles rapides et légers, tout en redirigeant les problèmes complexes vers des modèles plus performants. Cela garantit des réponses rapides, précises et cohérentes, améliorant ainsi la satisfaction des clients et réduisant les contraintes opérationnelles.
Gestion des connaissances et recherche d'entreprise
Les entreprises gèrent de grands référentiels de documents internes, de manuels et de politiques. Les routeurs analysent les requêtes et les acheminent vers des modèles optimisés pour le raisonnement, la synthèse ou les connaissances spécifiques à un domaine. Les employés reçoivent des informations précises et contextuelles sans surcharger les modèles coûteux.
Automatisation des flux de travail et des tâches
Les LLM sont largement utilisés pour la génération de rapports, l'analyse de données et les tâches d'aide à la décision. Les routeurs attribuent dynamiquement des requêtes très complexes à des modèles puissants et des tâches de routine à des modèles plus légers, en équilibrant vitesse, précision et coûts de calcul entre les flux de travail de l'entreprise.
Orchestration multimodèle
Les organisations déploient souvent plusieurs LLM auprès de fournisseurs ou de domaines différents. Les routeurs gèrent la sélection des modèles, l'équilibrage de charge et les mécanismes de repli, garantissant ainsi la fiabilité, la flexibilité et l'évolutivité des systèmes d'IA à grande échelle.
Recommandations de produits et personnalisation
Pour les plateformes de commerce électronique ou SaaS, les routeurs LLM peuvent attribuer des tâches de personnalisation à des modèles formés en fonction du comportement et du contexte des utilisateurs, tout en déléguant des recommandations génériques à des modèles plus simples. Cela améliore la précision et les performances des recommandations tout en contrôlant les coûts.
Conformité et analyse des risques
Dans les entreprises financières, juridiques ou de santé, les requêtes peuvent nécessiter le strict respect des réglementations ou des directives spécifiques au domaine. Les routeurs peuvent diriger des requêtes sensibles ou à enjeux élevés vers des modèles dotés d'une expertise dans le domaine, garantissant ainsi la conformité tandis que les tâches générales sont gérées par des modèles standard.
Génération et résumé du contenu
À des fins de marketing, de partage de connaissances ou de documentation, les routeurs LLM peuvent attribuer des tâches de création de contenu complexes à des modèles de haute qualité et des tâches de synthèse ou de rédaction simplifiées à des modèles plus rapides, optimisant ainsi l'efficacité sans compromettre la qualité de sortie.
En appliquant les routeurs LLM à ces différents scénarios, les entreprises peuvent faire évoluer l'IA de manière intelligente, tout en maintenant les performances, la fiabilité et la rentabilité de multiples flux de travail et applications.
Après avoir exploré comment les routeurs LLM alimentent un large éventail d'applications d'entreprise, il est important de comprendre en quoi ils diffèrent d'un autre composant clé des systèmes d'IA multimodèles.
Un Routeur LLM est axé sur le routage intelligent des demandes. Sa fonction principale est d'analyser les requêtes entrantes, d'évaluer le contexte, la complexité et les métadonnées, puis de diriger chaque demande vers le modèle le plus approprié. Les routeurs intègrent souvent des stratégies avancées telles que le routage dynamique, la prise de décision contextuelle et des mécanismes de repli pour optimiser la précision, la vitesse et les coûts.
Ils sont particulièrement importants dans les environnements où le type, le domaine ou les exigences de calcul des requêtes varient considérablement, ce qui permet aux entreprises d'équilibrer la charge et de maintenir des performances élevées.
Un Passerelle LLM, d'autre part, agit comme un point d'accès centralisé pour interagir avec un ou plusieurs LLM. Son rôle principal est de simplifier l'intégration, de fournir des API standardisées, de gérer l'authentification, de gérer la limitation des taux et de surveiller l'utilisation.
Contrairement aux routeurs, les passerelles ne prennent généralement pas de décisions intelligentes en matière de sélection de modèles ; elles fournissent un accès et des contrôles opérationnels uniformes pour faciliter les déploiements multimodèles. Les passerelles se concentrent davantage sur la gestion, la sécurité et l'évolutivité au niveau de l'infrastructure plutôt que sur l'optimisation au niveau des requêtes.
Principales différences
Les routeurs et les passerelles fonctionnent souvent ensemble dans des architectures en couches. La passerelle fournit un point d'entrée sécurisé et standardisé pour les applications, tandis que le routeur se trouve derrière elle et prend des décisions intelligentes en matière de sélection de modèles. Cette combinaison permet aux entreprises d'obtenir à la fois un contrôle opérationnel et une gestion optimisée des requêtes.
Comprendre la distinction entre les routeurs LLM et les passerelles LLM permet aux organisations de déployer efficacement des systèmes d'IA multimodèles.
Les routeurs génèrent des performances intelligentes et sensibles au contexte, tandis que les passerelles garantissent un accès sécurisé, évolutif et fiable, créant ainsi une base solide pour l'IA d'entreprise.
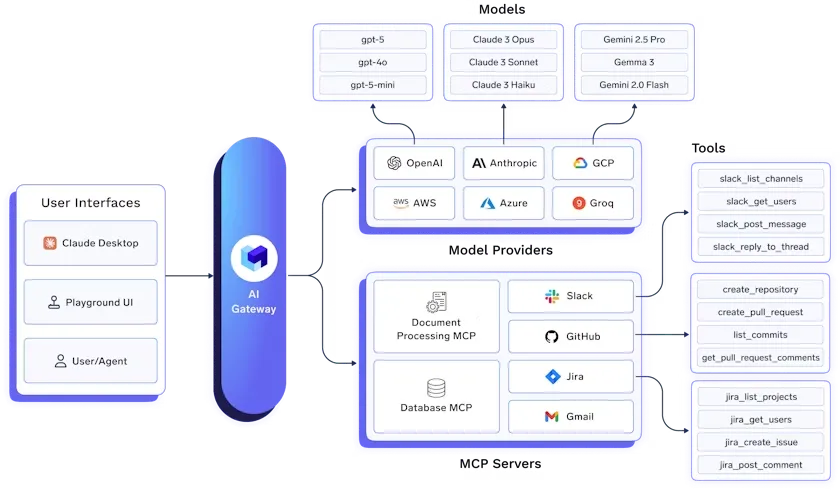
TrueFoundry LLM Gateway est une plateforme prête à l'emploi qui unifie l'accès à tous les principaux modèles de langage de grande taille (LLM) via une API unique, sécurisée et performante.
Il simplifie l'infrastructure GenAI en intégrant plus de 250 modèles, dont OpenAI, Anthropic Claude, Gemini, Groq, Mistral et des frameworks open source, sans nécessiter de modifications de code. Les équipes peuvent utiliser une API cohérente pour le chat, la complétion, l'intégration et le reclassement des charges de travail tout en centralisant l'authentification et la gestion des clés d'API.
Caractéristiques principales :
Alors que les entreprises s'appuient de plus en plus sur plusieurs grands modèles de langage, des outils tels que les routeurs LLM et les passerelles LLM sont devenus indispensables pour gérer l'IA à grande échelle. Les routeurs LLM apportent de l'intelligence au système en analysant chaque requête et en s'assurant qu'elle atteint le modèle le mieux adapté à la tâche. Cela permet d'améliorer les performances, de réduire les coûts et d'améliorer la fiabilité, en particulier pour les flux de travail complexes et volumineux.
Les passerelles, quant à elles, constituent l'épine dorsale d'un accès sécurisé et standardisé aux modèles, simplifiant l'intégration, surveillant l'utilisation et appliquant les contrôles opérationnels.
Ensemble, ces composants forment une architecture d'IA en couches qui équilibre intelligence et efficacité opérationnelle. En combinant les capacités de prise de décision des routeurs avec la fiabilité structurelle des passerelles, les entreprises peuvent optimiser la valeur de plusieurs LLM tout en maintenant l'évolutivité et le contrôle.
L'adoption de routeurs LLM n'est plus une option ; c'est une nécessité pour les entreprises qui souhaitent fournir des services d'IA rapides, précis et rentables. Comprendre leur rôle, ainsi que les passerelles, permet aux équipes de concevoir des infrastructures d'IA robustes qui répondent aux divers besoins des entreprises.
Alors que les modèles d'IA continuent d'évoluer et de se multiplier, la maîtrise du routage intelligent et de l'accès structuré sera essentielle pour les entreprises qui souhaitent rester compétitives dans le paysage de l'IA en évolution rapide.
Le routage LLM fonctionne en évaluant les demandes entrantes par rapport à une logique prédéfinie, à des intégrations sémantiques ou à des règles de classification. Le système achemine le trafic en fonction du contexte, de la précision requise ou de la latence du fournisseur en amont. Une passerelle centralisée gère ces configurations complexes afin d'automatiser la sélection des modèles et le basculement sans nécessiter de modifications manuelles du code pour chaque mise à jour du modèle.
La classification de routage LLM utilise un modèle très efficace pour classer les invites avant l'exécution de l'inférence. Cette étape permet d'identifier l'intention, par exemple de simples salutations par rapport à des tâches de codage complexes. La classification automatique empêche la surutilisation de modèles frontières coûteux en filtrant les requêtes peu complexes vers des alternatives plus petites, plus rapides et plus rentables.
TrueFoundry unifie les fonctionnalités de routage LLM et d'AI Gateway en fusionnant l'orchestration du trafic avec la gouvernance et la sécurité. La plateforme gère le basculement des modèles, la limitation du débit et le routage axé sur les coûts au sein d'un plan de contrôle centralisé unique. Cette infrastructure garantit que les déploiements d'IA d'entreprise sont hautement résilients et rentables pour les environnements de production à grande échelle.
Les principaux routeurs LLM incluent TrueFoundry pour une orchestration de niveau entreprise, LitelLM pour une API proxy unifiée et Martian pour la sélection automatique de modèles. Parmi les autres principales options du secteur, citons Portkey pour les garde-corps avancés, Helicone pour une observabilité incroyablement rapide et OpenRouter pour un accès simple à des centaines de modèles ouverts et à source fermée.
Les routeurs LLM examinent les métadonnées, le type et le contexte des requêtes pour sélectionner un modèle. Les facteurs de sélection incluent l'expertise du domaine, la capacité de raisonnement, la latence et le coût. Les requêtes simples concernent les modèles légers, les tâches complexes les modèles à haute capacité. Les routeurs avancés peuvent utiliser des intégrations ou des classificateurs prédictifs pour le routage intelligent des modèles en temps réel.
Les fonctions principales d'un routeur LLM incluent l'analyse des demandes, la sélection intelligente de modèles, l'équilibrage de charge, la gestion des solutions de secours et la surveillance. Les routeurs distribuent les requêtes sur plusieurs LLM, redirigent les demandes ayant échoué et suivent les performances. Cela garantit que les tâches sont traitées efficacement, que les modèles sont utilisés de manière optimale et que le système reste fiable et évolutif dans les flux de travail d'IA des entreprises.
Les types courants de routeurs LLM incluent le routage basé sur des règles, le routage basé sur les coûts, le routage basé sur les performances et le routage basé sur les tâches. Les routeurs basés sur des règles suivent des conditions prédéfinies, les routeurs basés sur les coûts choisissent des modèles moins chers, les routeurs basés sur les performances sélectionnent des modèles plus précis ou plus rapides, et les routeurs basés sur les tâches envoient des requêtes à des modèles spécialisés pour des tâches telles que le codage, le chat ou la synthèse.
Le routage LLM est effectué en analysant la demande de l'utilisateur et en l'orientant vers le modèle le plus approprié. Les développeurs définissent des règles ou utilisent des algorithmes qui prennent en compte des facteurs tels que le type de tâche, le coût, la latence et la capacité du modèle. Une couche de routage évalue l'entrée et envoie automatiquement la requête au LLM approprié.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


