

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 27, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
La plateforme de Vercel, en particulier son SDK d'IA et son outil en un clic déploiement sur demande workflow permet aux équipes frontales de mettre en place des démonstrations d'IA en quelques minutes. Le SDK Vercel AI est une boîte à outils open source gratuite qui permet aux équipes de proposer rapidement des fonctionnalités d'IA.
Cependant, la tarification de Vercel a été initialement conçue pour les sites statiques et les fonctions Web éphémères. Lorsque la charge de travail d'IA d'une application devient importante, par exemple en cas de diffusion en continu de réponses d'agents en plusieurs étapes ou de pipelines RAG lourds, le modèle de tarification de Vercel AI change radicalement.
Au lieu de tarifs mensuels fixes, vous commencez à payer à la milliseconde de temps d'exécution sans serveur et en gigaoctets de données transférés. Dans la pratique, les équipes constatent que leurs factures prévisibles de 20 dollars par mois augmentent considérablement à mesure que les chatbots et les agents atteignent les limites de ressources de Vercel.
Ce guide explique comment fonctionne la tarification de Vercel AI, quels sont les frais cachés engendrés par les charges de travail liées à l'IA et explique pourquoi les équipes d'ingénierie finissent par migrer vers des plateformes de cloud privé telles que TrueFoundry pour éviter ces coûts.
Pour en savoir plus sur le paysage d'AI Gateway et les considérations à prendre en compte avant de choisir un fournisseur, lisez l'intégralité Le guide du marché Gartner pour les passerelles IA 2025 est disponible ici.
.webp)
Vercel utilise désormais un modèle hybride en combinant le nombre de sièges utilisateurs avec des quotas d'utilisation et des frais d'utilisation excédentaire. En termes simples : l'utilisation par les amateurs est gratuite, mais les coûts d'utilisation professionnelle augmentent en fonction de la taille de votre équipe et des besoins informatiques. Vous trouverez ci-dessous un résumé de chaque niveau et de ses implications pour les applications d'IA.
Le Passe-temps plan est « le point de départ idéal pour votre application Web ou votre projet personnel » et est gratuit pour toujours. Il est strictement limité à un usage personnel et non commercial : l'utilisation commerciale ou génératrice de revenus du plan Hobby enfreint les conditions de Vercel. Hobby inclut des fonctionnalités généreuses (CDN, 1 million de requêtes Edge par mois, WAF simple) mais des limites de calcul très strictes. En particulier, les fonctions de Hobby ne peuvent fonctionner que pendant 60 secondes (par défaut), car durée de la fonction est plafonné (et légèrement ajustable) sur les forfaits gratuits. Les applications d'IA ont souvent besoin de diffuser des réponses ou d'exécuter des boucles d'agents de plus d'une minute. Sur Hobby, ces longues tâches seront simplement délai d'expiration avec 504 erreurs. En bref, si votre démo d'IA nécessite un calcul soutenu (par exemple, une requête complexe ou une recherche vectorielle), Hobby est susceptible de s'arrêter avant que le résultat n'arrive. Dans la pratique, les équipes constatent que même les appels LLM ou les chaînes d'agents modérément complexes dépassent les limites de durée fixées par Hobby. Cela rend le niveau gratuit idéal pour les prototypes et les expériences légères, mais ne convient pas aux charges de travail d'IA de production qui nécessitent des sorties de calcul ou de streaming étendues.
Le Pro le plan commence à 20$ par utilisateur en déploiement et par mois. (Chaque siège de développeur coûte 20$ par mois ; vous pouvez ajouter un nombre illimité de sièges « spectateurs » gratuits.) Pro convertit ces quotas de loisirs en limites plus élevées, mais cela a un coût. Par exemple, Pro inclut 1 To de bande passante par mois (environ 350$ d'une valeur), soit dix fois les 100 Go inclus dans Hobby. Au-delà de ce 1 To, le trafic sortant est facturé à 0,15 $/GO. Pro augmente également la fonction compute incluse : par défaut, vous vous déplacez 1 000 Go-heures d'exécution sans serveur par mois (pour toutes les fonctions), soit à peu près ce que consommerait un développeur exécutant de petites tâches, avant de payer un excédent.
Cependant, les charges de travail de l'IA franchissent ces limites extrêmement rapidement. Chaque flux ouvert ou chaque longue inférence consomme de la mémoire et du temps processeur. Dans la pratique, les développeurs signalent avoir épuisé les quotas Pro en quelques jours : un exemple montre un service de capture d'écran déployé utilisant 494 Go-heures en seulement 12 jours de tests, de projections 1 276 Go-heures par mois. Étant donné que Vercel facture en fonction du temps d'exécution, les 1 276 Go-heures de ce travailleur entraîneraient un 160$ supplémentaires par mois (à environ 0,18 dollar par Go par heure) au-delà du forfait de base. En bref, le coût de Vercel AI sur le plan pro peut facilement atteindre des centaines, voire des milliers de dollars une fois que vous démarrez des flux d'IA de longue durée, des récupérations RAG intensives ou des transferts de données volumineux.
Principaux points à retenir pour Pro : it peut prennent en charge les applications de production, mais chaque développeur que vous ajoutez coûte plus de 20 dollars par mois, et une utilisation imprévisible (streaming IA, grands modèles) peut entraîner des moyennes élevées. Les crédits gratuits inclus ne font que reporter la facturation ; la diffusion de réponses en 45 secondes signifie que les serveurs restent actifs pendant 45 secondes, soit 45 fois plus cher qu'un appel d'API d'une seconde.
Le niveau Enterprise est personnalisé et s'adresse aux grandes organisations. Officiellement, les détails sont entre guillemets, mais dans la pratique, l'entrée commence à peu près 25 000$ par année pour les fonctionnalités de base.
Ce niveau débloque des outils avancés de conformité et de mise à l'échelle, tels que :
Par exemple, seul le contrat Enterprise bénéficie de centaines d'emplacements de règles WAF (jusqu'à 1 000 règles de blocage IP). En termes de tarification de Vercel AI, Enterprise supprime certaines limites d'utilisation et autorise des fonctions plus importantes, mais les débits de données et d'heures de mémoire par gigaoctet restent inchangés.
De nombreuses startups considèrent le passage de la version Pro à la version Enterprise comme une « falaise », car les fonctionnalités supplémentaires sont destinées aux entreprises, mais leur prix est supérieur d'un ordre de grandeur. Comme l'a fait remarquer un développeur, le niveau Pro est peut-être « tout ce dont vous avez besoin », mais le coût à grande échelle dépend de l'utilisation et non de la licence.
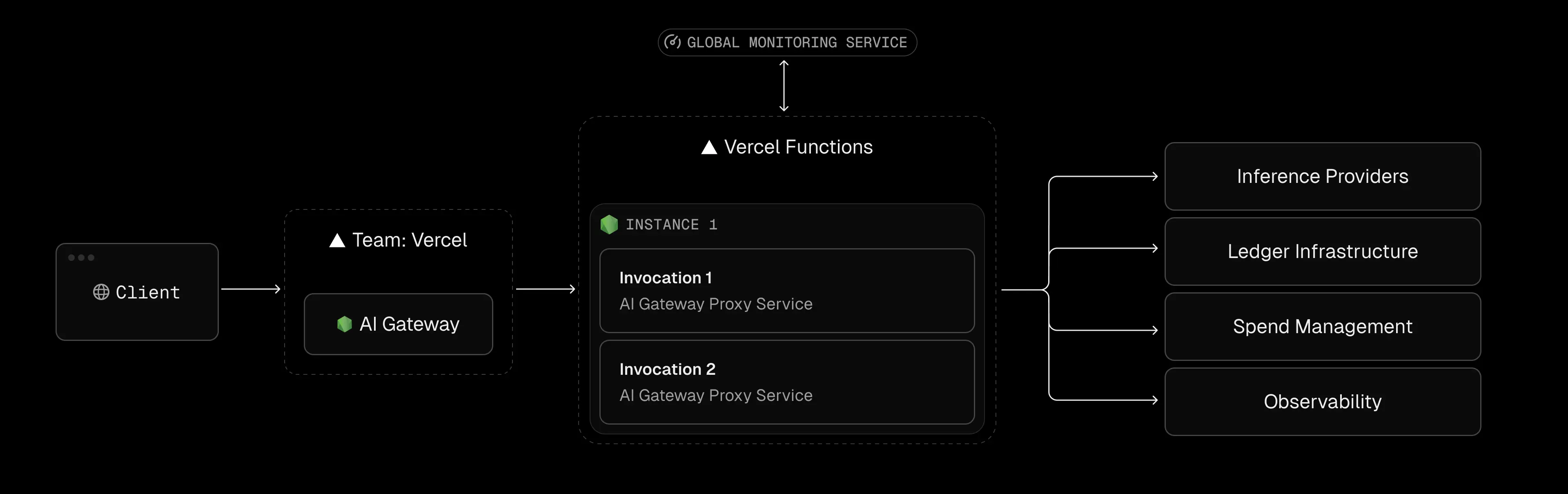
La tarification de Vercel AI est optimisée pour les applications Web (nombreuses demandes courtes et sans état). Les applications d'IA se comportent différemment. Le principaux facteurs de coûts pour l'IA sur Vercel, ce sont : exécution durée, données sortie, et concurrence contraintes.
Sur Vercel, vous payez pour chaque milliseconde d'une fonction actif. L'attente d'une E/S ou d'une diffusion en continu est considérée comme du temps facturable. Les documents indiquent explicitement : « Function Duration génère des factures en fonction du temps d'exécution total d'une fonction Vercel. ». Pour un appel d'API Web normal (10 à 100 ms), cela est négligeable, mais un chat LLM peut être diffusé pendant 30 à 60 secondes. Dans ce cas, une seule demande peut coûter bien plus cher.
Imaginons un scénario type :
Une fonction Next.js Edge ouvre une réponse en streaming au navigateur jusqu'à la fin du LLM. Pendant ce flux, l'instance sans serveur est occupée en permanence, ce qui entraîne une facturation continue de la mémoire (et d'une partie du processeur). Dans la pratique, les équipes ont fait état d'une utilisation incroyablement élevée. Dans une étude de cas, un développeur a migré un service de capture d'écran Puppeteer très développé vers Vercel. Le plan Pro comprenait 1 000 Gbit/s, mais en 12 jours, ce service était déjà consommé 494 Go-heures. Extrapolé à un mois complet, c'est 1 276 Go-heures, ce qui signifie à peu près 160$ de frais supplémentaires sur Vercel pour cette fonction unique. (Ce développeur est finalement passé à AWS Lambda car la même charge de travail sur AWS n'était que d'environ 101 Go-heures/mois.)
La leçon : les longs flux d'IA sont fondamentalement « lourds » en termes de facturation sans serveur. Une réponse de chat d'une minute peut brûler 20 à 50 Mo de mémoire pendant 60 secondes, soit un coût d'environ 0,001$ par demande. Multipliez cela par une utilisation intensive, et le tout s'additionne rapidement.
Les applications d'IA impliquent souvent la génération augmentée par extraction (RAG) ou des pipelines de données qui déplacent des mégaoctets de texte et d'intégrations. Chaque fois que votre fonction Vercel extrait un document ou un modèle depuis un magasin distant, ces données quittent le réseau Vercel.
Une utilisation intensive de RAG entraîne des excédents importants. Par exemple, récupérer dix fois un document de 100 Mo consommerait 1 Go de bande passante. Si un pipeline RAG mélange des centaines de gigaoctets par mois, cela pourrait rapporter des centaines de dollars à la facture.
En résumé, les quotas de bande passante de Vercel semblent généreux pour le trafic Web régulier, mais les applications d'IA qui envoient régulièrement des charges utiles importantes ou intègrent des lots les dépasseront rapidement et entraîneront des dépassements coûteux.
Les fonctions de Vercel s'adaptent automatiquement jusqu'à un certain point, mais elles ont des limites. Par défaut, la plateforme autorise jusqu'à environ 30 000 exécutions simultanées sur Hobby/Pro (et plus de 100 000 sur Enterprise). Pour la plupart des applications, cela semble élevé, mais les charges de travail de l'IA peuvent augmenter la simultanéité de manière inattendue.
Par exemple, un service de chat basé sur l'IA peut ouvrir des dizaines de flux de fonctions simultanés à de nombreux utilisateurs à la fois. Une fois que vous avez atteint le plafond de simultanéité, les nouvelles demandes sont mises en file d'attente ou limitées. À ce stade, vous devez soit effectuer une mise à niveau (par exemple, Enterprise), soit implémenter une mise à l'échelle externe.
En fait, Vercel plafonne le trafic d'IA en rafale, à moins que vous ne payiez beaucoup plus cher. Pour l'anecdote, des équipes ont vu des chatbots commencer à échouer (erreurs 504/429) lors de pics de trafic, car le pool sans serveur sous-jacent était saturé.
.webp)
Une idée fausse courante est que l'utilisation du Vercel AI SDK vous force à accéder à l'infrastructure de Vercel. En réalité, le SDK AI n'est qu'une boîte à outils (open source, gratuite) permettant de créer des fonctionnalités d'IA dans Next.js/TypeScript.
Vous pouvez utiliser le SDK pour effectuer un routage vers n'importe quel fournisseur LLM, y compris les modèles auto-hébergés, ce qui est un élément important à prendre en compte lors de la comparaison Vercel AI gateway et OpenRouter pour la flexibilité des fournisseurs et le contrôle des coûts. Il y a aucune exigence pour exécuter votre code sur les serveurs de Vercel. En fait, la plupart des composants du SDK (composants de l'interface utilisateur, fournisseurs, bibliothèques clientes) fonctionnent n'importe où. Par exemple, une équipe pourrait conteneuriser son application Next.js avec le SDK AI et la déployer sur Kubernetes (EKS/GKE) ou sur n'importe quelle machine virtuelle cloud. Le code ne « sait » pas que c'est hors de Vercel.
Pourquoi les équipes sont bloquées :
Généralement pour des raisons de commodité. L'hébergement de Vercel s'intègre étroitement au SDK : vous validez du code et Vercel crée, déploie et fournit même un onglet AI Gateway intégré. De nombreuses équipes cliquent par défaut sur « Déployer vers Vercel ».
Le compromis est que la commodité masque le modèle de coût sans serveur. Les ingénieurs peuvent réaliser des prototypes avec Vercel avec plaisir, sans savoir que chaque appel de modèle est facturé aux tarifs sans serveur de Vercel (souvent plus élevés), jusqu'à ce que la facture arrive.
Au fur et à mesure que les projets d'IA pilotés par Vercel se développent, plusieurs problèmes opérationnels apparaissent parallèlement aux problèmes de tarification de Vercel AI :
Même sur les forfaits payants, Vercel impose des limites d'exécution strictes. Par défaut, les fonctions HTTP de la version Pro s'éteignent après 5 minutes (configurable jusqu'à 13 minutes avec « Fluid Compute »). Sur Hobby, cela ne dure que 60 secondes.
Dans la pratique, tout agent d'IA ou tout flux de travail de recherche qui s'exécute pendant plus de quelques minutes sera détruit. Par exemple, un agent en plusieurs étapes qui a besoin de 10 à 15 minutes pour interroger des bases de données, résumer des documents et émettre un rapport dépassera la limite de manière fiable et échouera.
Les équipes signalent fréquemment 504 erreurs dans leurs tâches d'IA une fois qu'elles dépassent ces limites. En revanche, sur votre propre infrastructure cloud, vous pouvez autoriser des fonctions ou des conteneurs à s'exécuter indéfiniment (ou au moins pendant des heures) selon vos besoins.
Le middleware Edge de Vercel (comme Next.js Edge Functions) peut améliorer les performances, mais il est livré avec un verrouillage.
Dans la pratique, les équipes intègrent parfois une logique critique dans Edge Functions pour gagner en rapidité, avant de trouver migrer loin de Vercel devient une réécriture majeure.
Vercel ne dispose actuellement d'aucune instance GPU native pour les charges de travail d'IA. Cela signifie que tout travail d'inférence ou d'intégration de modèles nécessitant une accélération doit être effectué hors plateforme.
Les équipes finissent souvent par héberger des modèles de style GPT ou des recherches vectorielles sur AWS/GCP/Render/Azure avec des GPU, puis par les appeler depuis les fonctions de Vercel. Cette configuration divisée ajoute de la latence (chaque appel passe vers un service externe) et de la complexité opérationnelle.
En revanche, une infrastructure basée sur Kubernetes (comme TrueFoundry) peut exécuter du code Web uniquement basé sur le processeur et l'inférence GPU côte à côte dans le même cluster, éliminant ainsi cette fragmentation.
Malgré ces mises en garde, Vercel n'est pas un mauvais choix pour quelques Scénarios d'IA. Ses points forts brillent lorsque :
En résumé : La tarification de Vercel AI fonctionne bien pour les applications frontales qui utilisent légèrement l'IA, ou pour les équipes qui privilégient avant tout le délai de mise sur le marché. Le seuil de rentabilité est atteint lorsque les charges de travail liées à l'IA deviennent des parties « réelles » de l'application, et pas seulement des démonstrations de nouveautés. C'est à ce moment que les coûts deviennent difficiles à prévoir.
.webp)
À mesure que les fonctionnalités d'IA occupent une place centrale dans le produit, de nombreuses équipes atteignent un point critique et recherchent des alternatives. TrueFoundry se positionne comme une solution qui offre la simplicité d'une solution sans serveur tout en offrant les avantages d'un cloud brut. Vous trouverez ci-dessous une comparaison des principaux facteurs relatifs aux charges de travail liées à l'IA :
Qu'est-ce que cela signifie dans la pratique ? De nombreuses équipes constatent que leurs factures mensuelles sur Vercel augmentent de façon disproportionnée par rapport à leur calcul réel. Dans un exemple concret, un service a consommé environ 1 276 Go par heure sur Vercel (soit environ 2 000 dollars par an), mais seulement environ 101 Go par heure sur AWS Lambda brut (niveau gratuit) pour la même charge. Tout simplement, des charges de travail d'IA équivalentes peuvent être exécutées à bien moindre coût sur une infrastructure cloud autogérée. Avec TrueFoundry, votre facture est essentiellement constituée d'un cloud computing « classique » (nœuds EC2, GKE, etc.) plus des frais de plateforme, au lieu du multiplicateur imposé par le mode sans serveur.
.webp)
TrueFoundry propose une approche hybride : vous conservez le modèle sans serveur convivial pour les développeurs (dimensionnement automatique, API simples) tout en l'exécutant sur votre propre compte cloud. Les principaux aspects sont les suivants :
TrueFoundry vous permet de déployer Next.js (et toute autre application) en tant que services Docker standard sur Kubernetes (EKS, GKE ou AKS) dans votre propre compte cloud. Comme l'explique un blog, « TrueFoundry permet de déployer très facilement des applications sur des clusters Kubernetes depuis votre propre compte de fournisseur de cloud. ». Sous le capot, vos points de terminaison Next.js s'exécutent dans des pods/nœuds que vous contrôlez.
Cela signifie que vous êtes facturé à tarifs bruts du cloud pour le processeur et la mémoire, sans prime cachée sans serveur. Un WebSocket inactif ou un flux ouvert consomme toujours de la RAM sur le nœud, mais le prix de cette RAM ne représente qu'une fraction du coût d'un Gbit/s sans serveur.
Puisque vous gérez les nœuds Kubernetes, vous contrôlez les délais d'expiration et les durées de vie des fonctions. Vous pouvez exécuter des modules ou des tâches de longue durée pendant des minutes ou des heures selon les besoins. TrueFoundry n'impose pas de limite de 5 ou 15 minutes, c'est votre infrastructure qui le fait.
Les pipelines d'agents complexes et les tâches de recherche s'exécutent simplement jusqu'à leur terme (sous réserve uniquement de la durée de vie maximale normale du pod, le cas échéant). Cela élimine le problème courant de Vercel, à savoir les erreurs 504 à mi-parcours. Si un agent d'IA a besoin de 20 minutes pour terminer, il peut le faire sur TrueFoundry ; sur Vercel, il aurait échoué au bout de 5 minutes.
L'un des principaux avantages de TrueFoundry for AI est la prise en charge intégrée du GPU. Parce que Kubernetes est sous le capot, vous pouvez associer des pools de nœuds GPU et planifier des charges de travail d'inférence parallèlement à vos services Web. Cela signifie que vos API frontales et votre inférence ML intensive peuvent s'exécuter dans le même cluster (ce qui réduit la latence et le transfert de données). En fait, l'architecture native du cloud de TrueFoundry est explicite « nous permet d'avoir accès aux différents matériels fournis par différents fournisseurs de cloud, en particulier dans le cas des GPU ».
En pratique, cela signifie que vous pouvez exécuter l'inférence LLM ou intégrer la génération sur des nœuds accélérés par GPU sans quitter la plate-forme. Il n'est pas nécessaire de connecter un service GPU distinct (et de payer pour le trafic interrégional).
Vercel reste une excellente plateforme pour la livraison frontale. Mais dès que l'IA effectue des calculs depuis le backend, l'économie change. Le principal point à retenir : évitez de payer la prime basée sur la durée de Vercel pour les tâches d'IA lourdes.
Contrairement au simple trafic HTTP, les backends d'IA fonctionnent souvent beaucoup plus longtemps par requête et transfèrent de nombreuses données. Selon le modèle de tarification de Vercel AI, cela signifie payer pour chaque seconde de calcul et chaque gigaoctet sorti. En revanche, avec TrueFoundry, vous payez pour les nœuds bruts et les secondes de disponibilité, soit le même modèle de coût que si vous utilisiez un conteneur sur EC2 ou GKE.
Le résultat final est une réduction des coûts de mise à l'échelle. Les équipes constatent que leurs dépenses mensuelles augmentent linéairement avec le calcul réel utilisé, et non pour chaque milliseconde de temps de fonction. Dans de nombreux cas, ce qui leur coûte des centaines de dollars par mois sur Vercel peut être effectué pour des dizaines sur leur propre cloud.
Si votre équipe est confrontée à des factures Vercel en spirale ou à des problèmes constants de temps mort, il vaut la peine d'envisager un changement d'infrastructure. True Foundry est conçu pour vous permettre de conserver la productivité du mode sans serveur (déploiements faciles, évolutivité) tout en supprimant ses inconvénients. Une démonstration rapide peut montrer comment le transfert de votre charge de travail d'IA vers TrueFoundry peut réduire les coûts sans sacrifier la vitesse.
Réservez une démonstration rapide pour découvrir comment le transfert de votre charge de travail d'IA vers TrueFoundry peut réduire les coûts sans sacrifier la rapidité.
La passerelle Vercel AI offre une niveau gratuit. Chaque compte de l'équipe Vercel reçoit 5$ de crédits AI Gateway par mois une fois que vous aurez fait votre première demande. Vous pouvez continuer à utiliser ce crédit gratuit indéfiniment (il est actualisé tous les 30 jours) pour expérimenter des LLM via Vercel. Au-delà de cela, vous passez au paiement à l'utilisation et devez acheter des crédits supplémentaires. Notez que ce crédit de 5$ est uniquement destiné à l'utilisation de la passerelle ; c'est le cas pas couvrez vos frais de fonctionnement, de calcul ou de bande passante sur la plateforme. Ils sont facturés séparément dans le cadre du forfait de votre compte.
Le niveau Hobby de Vercel est gratuit pour des projets personnels. Le Pro le plan commence à 20$ par siège de développeur et par mois, ainsi que tous les modules complémentaires basés sur l'utilisation. En pratique, une petite équipe de 3 développeurs paie environ 60 dollars par mois. Si vous avez besoin de fonctionnalités supplémentaires (SSO, disponibilité garantie, etc.), le niveau Enterprise commence dans une fourchette à cinq chiffres par an. Au-delà de ces frais de base, vous payez les Go-heures supplémentaires, les requêtes Edge et le transfert de données en fonction des taux d'utilisation de Vercel.
Le Forfait de 20$ fait référence à Vercel Niveau Pro (parfois simplement appelé « compte Pro »), qui coûte 20$ par utilisateur et par mois. Il inclut toutes les fonctionnalités de Hobby, ainsi que des outils de collaboration en équipe et des quotas plus élevés. Par exemple, la version Pro inclut 1 To de bande passante périphérique par mois et une plus grande allocation de Go par heure pour les fonctions. Si une équipe Pro dépasse ces quotas, l'utilisation supplémentaire est facturée aux taux d'excédent de Vercel. En bref, le plan à 20$ est le plan payant d'entrée de gamme pour les équipes professionnelles (au-delà du niveau gratuit Hobby).
La plateforme de Vercel présente plusieurs contraintes qui affectent les applications d'IA. Par défaut, les fonctions sans serveur temps d'arrêt rapide (60 à 300 secondes sur Hobby/Pro). Les réponses de l'IA en streaming sont considérées comme du temps d'activité complet, de sorte que les longues requêtes deviennent coûteuses. Il existe des limites strictes en matière de simultanéité et de taille de charge utile des demandes (maximum 4,5 Mo de corps). De plus, Vercel fait ne supporte pas les GPU, de sorte que toute inférence de modèle lourde doit être exécutée hors plateforme. L'AI Gateway elle-même propose un crédit gratuit de 5$ par mois uniquement ; au-delà de cela, vous payez les prix catalogue des fournisseurs pour les jetons. Dans la pratique, les équipes de Vercel signalent 504 erreurs inattendues, des factures élevées en Go-heures et un verrouillage architectural de l'environnement périphérique de Vercel si elles en deviennent trop dépendantes. Pour ces raisons, les charges de travail avancées en matière d'IA atteignent souvent un plafond sur Vercel et entraînent une migration vers des plateformes telles que TrueFoundry.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


