Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Série d'accélérateurs TrueFoundry : accélérateur intelligent de traitement de documents
L'OCR et le traitement des documents ne sont-ils pas un problème résolu ?
Alors que beaucoup pensent que l'OCR et le traitement de documents sont des technologies résolues, la saisie manuelle des données coûte aux entreprises américaines entre 15 000 et 30 000 dollars par employé et par an. Source: Les pertes de temps et d'exploitation liées au traitement manuel des documents restent importantes pour les raisons suivantes :
OCR traditionnel : fragile et peu performant
Les méthodes OCR traditionnelles (Computer Vision + Rules + NLP) présentent une faible adaptabilité à divers formats et mises en page d'écriture, ne tenant souvent pas compte des exigences de contexte et de format de données.
Faible adaptabilité : même les meilleurs systèmes d'OCR traditionnels de leur catégorie atteignent une précision de 85 à 90 % pour les documents complexes, tandis que le taux de précision du contenu manuscrit n'atteint que 64 %. Ssource
Mauvaise qualité d'image ou éclairage : 300 DPI est le minimum standard pour des résultats d'OCR optimaux
Bruit
Inclinaison et orientation
Dépendance entre le modèle et la mise en page : optimisé pour fonctionner sur un modèle spécifique, nécessite des pipelines de traitement personnalisés en aval ou un changement de modèle pour chaque nouveau type de document/mise à jour du modèle. Par exemple, Nouveau format de facture d'un fournisseur, colonne légèrement décalée dans un rapport
Cécité du contexte : l'OCR au niveau des caractères ne permet pas de différencier les caractères similaires, perdant ainsi la compréhension du contexte à l'échelle du document. Par exemple, « 50 mg de metformine » peut être lu comme « 5 mg de metformine », ce qui est incorrect pour toute tâche médicale en aval.
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
OCR basé sur LLM : imprévisible et coûteux
Les OCR basés sur le LLM résolvent certains problèmes liés aux méthodes traditionnelles mais introduisent de nouvelles complexités :
Non résolu pour le texte manuscrit : malgré la réussite de GPT-4V et Claude 3.5 Sonnet Précision de 82 à 90 % en ce qui concerne le texte manuscrit, ce qui constitue une amélioration significative, reste en deçà des seuils critiques pour l'entreprise. Par exemple, dans le secteur de la santé, un taux d'erreur de 10 à 18 % sur les ordonnances manuscrites pourrait littéralement mettre la vie en danger.
Difficile à dimensionner :
Coûteux prohibitif : pour les organisations qui traitent des millions de documents chaque année.
Réponses plus lentes :
Difficile de maintenir des SLA en mode auto-hébergé
Temps d'arrêt et pics de latence chez les fournisseurs tiers
Sorties incohérentes :
Hallucinations - par exemple, une valeur entièrement fabriquée pour une clause d'un document juridique
Difficile de se conformer à une sortie structurée
Même rapidité, réponses différentes
Dans les secteurs tels que les services financiers et la santé, qui traitent des millions de documents critiques chaque année, un système capable d'évoluer de manière fiable et de générer des résultats de haute qualité à faible coût est essentiel.
Quelle est la qualité de votre pipeline de traitement de documents ? (Métriques pratiques)
Operational Metrics & World-Class Benchmarks
Metric
Definition (Short)
World-Class Benchmark
Straight-Through Processing (STP)
% of documents processed end-to-end without human touch
85–95% for structured documents
Field Extraction Accuracy
Correctness of extracted key fields (names, amounts, dates)
99%+ for critical fields
Time to Value
Time from document receipt to structured data availability
<2 min (simple docs), <10 min (complex forms)
Human Edit Rate
% of data requiring manual correction
<5% while maintaining 99%+ accuracy
Processing Cost per Document
Total cost (compute, labor, infra) per processed page
$0.02–$0.15 per page (depending on complexity)
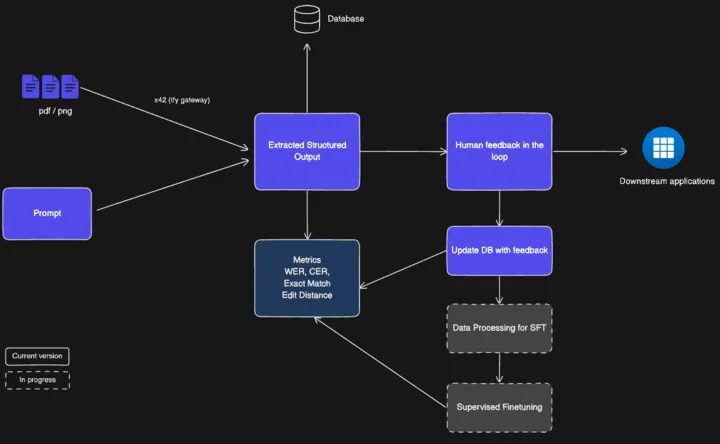
Présentation de l'accélérateur intelligent de traitement des documents de TrueFoundry
Le traitement intelligent des documents (IDP) de TrueFoundry est un accélérateur génératif basé sur l'IA qui associe des pratiques prêtes à la production à un pipeline d'OCR hautement personnalisable et précis pour créer et expédier des flux de traitement de documents de bout en bout.
Comment cela fonctionne : alimentez vos applications avec des données structurées en quelques minutes !
L'accélérateur ingère vos PDF, images ou télécopies et les nettoie : réduction du bruit, correction de l'inclinaison et mise à l'échelle. Les modèles partent donc d'une image nette. Il classe ensuite chaque document (facture, prescription, note manuscrite) et y joint le schéma, les instructions et les règles de domaine appropriés. Le modèle d'extraction extrait des champs structurés et des scores de confiance ; un moteur de règles les valide et les enrichit à l'aide de vérifications et de recherches. Les éléments sont acheminés vers un réviseur via une interface utilisateur simple, et chaque correction est renvoyée pour améliorer le système en permanence.
Composants modulaires et personnalisables
L'accélérateur est composé de composants modulaires enfichables qui, ensemble, peuvent créer à la fois un prototype du premier jour ou une application prête à être mise en production à grande échelle.
Composants de base
Support multimodèle (OSS et code source fermé)
L'humain dans la boucle (HITL) et commentaires
Infrastructure de réglage intégrée
Surveillance et observabilité
Intégration de la base de connaissances (RAG + Knowledge Graph)
Composants avancés
Classification et routage automatisés
OCR et boîtiers de délimitation tenant compte de la région
Découverte automatique des schémas (Zero-Shot)
Validation et post-traitement
Conformité et auditabilité
Notre conception a été validée dans de nombreuses implémentations d'entreprise
Construisez pour le choix et le contrôle
L'accélérateur est indépendant du modèle, qu'il soit OSS ou à source fermée, et peut acheminer les données entre les différents fournisseurs en termes de prix/performances et de basculement. Les experts restent informés grâce à une interface utilisateur de révision adaptée au domaine, dont les modifications deviennent des données d'entraînement.
Opérationnel dès le premier jour.
Vous bénéficiez d'une observabilité en temps réel (latence, débit, coût par document) ainsi que de KPI professionnels (STP, précision des champs et taux de modification). La validation et l'enrichissement appliquent des règles interdomaines et normalisent les formats avant que les données n'atteignent les applications en aval.
Adaptable, en particulier pour les cas d'utilisation complexes en entreprise
La découverte de schémas, l'OCR tenant compte des régions et la mise à la base de connaissances permettent de gérer des mises en page complexes ; les journaux d'audit préservent chaque action, chaque score et chaque dérogation pour les environnements réglementés.
Comment pouvons-nous garantir l'évolutivité de ce système ?
Notre architecture est un modèle basé sur des microservices, indépendant du cloud, conçu pour offrir une fiabilité, une évolutivité et une rentabilité de niveau entreprise. En découplant les composants principaux des files d'attente de messages asynchrones, le système gère les charges de travail fluctuantes et les défaillances des composants sans perte de données, évitant ainsi toute dépendance vis-à-vis d'un fournisseur.
Couche d'ingestion
Passerelle LLM sans état : point d'entrée unique (auth/rate-limit) qui place chaque document dans la file d'attente d'un sujet de message.
Mise en mémoire tampon durable : les téléchargements bruts sont enregistrés dans un espace de stockage d'objets à des fins de relecture, d'audit et de restauration.
Pipeline de traitement
Isolation des services : séparez les opérateurs pour la classification, l'extraction et la validation ; chacun peut être mis à jour et mis à l'échelle séparément.
Mise à l'échelle automatique indépendante : les extracteurs gourmands en CPU/GPU augmentent leur capacité pendant les pics sans affecter les étapes les plus légères.
Tâches idempotentes : les tâches rejouables avec déduplication garantissent des tentatives en toute sécurité et des sorties identiques.
Gestion des données et de l'état
Stockage portable : les compartiments compatibles S3 contiennent des documents et des artefacts avec gestion des versions.
Backbone relationnel : la base de données compatible PostgreSQL suit les métadonnées, l'état du flux de travail et les files d'attente HITL.
Contrats de schéma : des interfaces claires entre les services permettent des modifications sûres et rétrocompatibles.
Couche Feedback et MLOps
Boucle humaine : les corrections vérifiées sont capturées avec la provenance des données d'entraînement.
Boucle fermée : les pipelines de recyclage, d'évaluation et de déploiement automatisés permettent de remettre en production de meilleurs modèles.
Versions régies : le registre des modèles, les vérifications A/B et les annulations garantissent la sécurité et la contrôlabilité des améliorations.
Conclusion
L'OCR moderne n'est pas « résolue », en particulier lorsque la précision, l'échelle et le coût sont importants. L'accélérateur IDP de TrueFoundry propose une approche pragmatique prête à la production, comprenant une extraction multimodèle, une validation automatisée et une intervention humaine qui améliore continuellement le système. Il en résulte un traitement direct plus rapide, une plus grande précision au niveau des champs sur les documents qui gèrent réellement votre activité et une plateforme que vos équipes peuvent exploiter, et pas seulement une démonstration à admirer.
Cet accélérateur vous permet de traiter un plus grand nombre de documents de manière efficace et rentable, tout en préservant l'intégrité des données pour les auditeurs, les experts et les opérateurs, ce qui permet une mise en œuvre immédiate sans nécessiter une ingénierie personnalisée approfondie.
Projet pilote en cours de production : Communiquez avec nous à l'aide de ce lien. Nous pouvons créer un prototype fonctionnel sur votre propre cas d'utilisation et vous aider à fournir une application prête à être mise en production en un dixième du temps de développement normal !
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


