

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
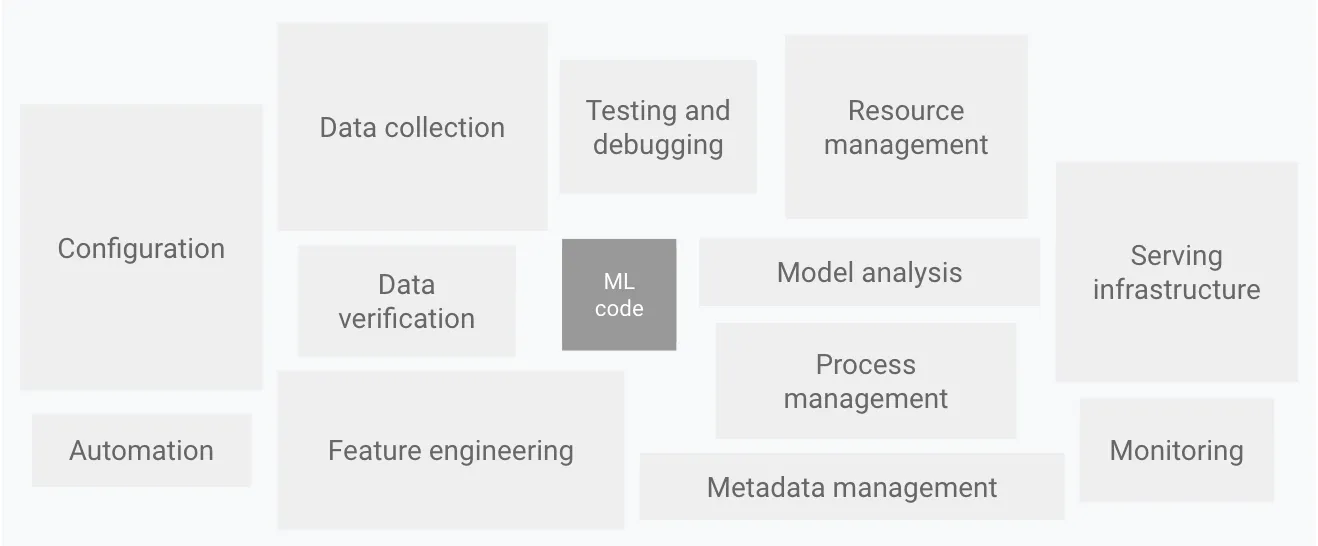
L'équipe Truefoundry a travaillé d'arrache-pied le mois dernier pour ajouter des fonctionnalités à notre plateforme de déploiement de machine learning. Notre objectif est de créer une plateforme de déploiement qui facilite le déploiement de modèles et de services de machine learning tout en appliquant les meilleurs principes d'ingénierie et de sécurité. Pour créer une excellente plateforme de machine learning, nous avons besoin d'une plate-forme d'ingénierie solide et c'est pourquoi l'objectif initial a été en grande partie de fournir une plate-forme solide pour déployer du code.
Parmi tous les éléments de la plate-forme Ml décrits ci-dessus, nous nous concentrons sur l'infrastructure de service, la surveillance et toute l'automatisation qui en résulte.
Beaucoup de travail a été consacré à la création de notre plateforme de déploiement sur Kubernetes. L'objectif était de le rendre absolument facile à déployer en moins de 5 minutes, la plateforme se chargeant de créer l'image à partir du code source, de la stocker dans un registre Docker, puis de déployer enfin l'application sur Kubernetes. Voici quelques-unes des mises à jour que nous avons apportées le mois dernier :
Les modèles d'apprentissage automatique peuvent présenter des latences d'inférence ou des performances très différentes selon le type d'instance. Par exemple, lorsque nous avons testé la latence d'inférence d'un modèle à visage câlin sur des processeurs Intel par rapport à des processeurs AMD, nous avons constaté que les processeurs Intel étaient environ 30 % plus rapides. C'est pourquoi nous disposons désormais d'une option permettant aux utilisateurs de choisir le type d'instance lors du déploiement de leurs charges de travail. Si le type d'instance n'est pas sélectionné, la charge de travail peut être déployée sur n'importe quel type d'instance disponible.

Auparavant, nous avions un lien Grafana pour afficher les journaux et les statistiques. Bien que Grafana soit hautement personnalisable, le contrôle des autorisations et des accès n'était pas vraiment possible sur Grafana. De plus, cela s'est avéré un peu lent et difficile à comprendre pour les utilisateurs qui n'étaient pas habitués à Grafana. C'est pourquoi nous avons implémenté notre propre interface utilisateur pour afficher les journaux et les métriques, ce qui devrait suffire dans la plupart des cas. Nous proposons toujours l'intégration de Grafana dans le cloud public pour les utilisateurs plus avancés.

Nous pouvons désormais ajouter des utilisateurs en tant qu'éditeur, afficheur ou administrateur sur des groupes secrets.

Nous pouvons désormais déployer directement sur Truefoundry à partir de n'importe quel référentiel Github ou bitbucket. Les utilisateurs peuvent intégrer leurs propres référentiels privés à l'aide du flux Oauth et sélectionner les paramètres appropriés pour déployer l'application.
Le mois prochain, nous travaillerons sur quelques fonctionnalités intéressantes, telles que :
Restez à l'affût et faites-nous part de vos commentaires !
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


