

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 26, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les systèmes LLM de production se comportent comme des systèmes distribués. Une seule demande utilisateur peut déclencher plusieurs appels de modèles, des appels d'outils et de nouvelles tentatives. Sans limite d'exécution unique, la télémétrie se fragmente et le débogage devient une conjecture.
Cet article explique comment connecter TrueFoundry AI Gateway à Elastic Cloud afin que les traces de la passerelle soient transférées vers Elastic Observability à l'aide d'OpenTelemetry. Vous allez configurer un point de terminaison OTLP et une clé API dans la passerelle.
Lorsque les applications communiquent directement avec les fournisseurs de modèles, il n'existe aucun endroit cohérent pour appliquer la politique et capturer les traces. Une passerelle crée cette surface cohérente afin de centraliser la gouvernance, le routage et la génération de télémétrie.
Passerelle TrueFoundry AI établit un point d'entrée régi unique pour les demandes de modèles et d'agents. Les applications et les agents communiquent avec le proxy de la passerelle au lieu de parler directement aux fournisseurs. Cette architecture assure la cohérence des décisions de routage et de la génération de télémétrie pour chaque demande.
La passerelle peut exporter des traces à l'aide des protocoles OpenTelemetry standard afin que vous puissiez envoyer le même flux de traces à la plateforme d'observabilité que vos équipes utilisent déjà.
Cloud élastique est un service géré pour la Suite Elastic qui prend en charge l'observabilité de la recherche et les flux de travail de sécurité. Il peut analyser les logs, les métriques et les traces à grande échelle, ce qui en fait une destination naturelle pour les traces des passerelles.
TrueFoundry AI Gateway prend en charge l'exportation de traces OpenTelemetry vers des plateformes externes telles qu'Elastic Cloud afin que vous puissiez utiliser Elastic pour l'observabilité tout en conservant TrueFoundry en tant que couche d'accès LLM unifiée.
Cette intégration utilise OpenTelemetry de bout en bout. La passerelle exporte les traces OTEL et Elastic Cloud les ingère via son point de terminaison OTLP géré.
Dans la console Elastic Cloud, ouvrez votre projet de déploiement ou votre projet sans serveur, puis accédez à Ajouter des données, puis à Applications, puis à OpenTelemetry. Copiez l'URL du point de terminaison OTLP géré et copiez la valeur de la clé API affichée pour les en-têtes d'authentification. Les déploiements Elastic Cloud Hosted nécessitent la version 9.2 ou ultérieure pour le point de terminaison OTLP géré.
Dans le tableau de bord TrueFoundry, accédez à AI Gateway, puis à Contrôles, puis à Paramètres. Accédez à la section OTEL Config et ouvrez l'éditeur pour la configuration de l'exportateur.
Activez l'exportateur OTEL Traces. Définissez le type de configuration sur http. Définissez le point de terminaison des traces sur le point de terminaison OTLP géré que vous avez copié depuis Elastic Cloud. Choisissez l'encodage Json ou Proto.
Une configuration minimale ressemble à ceci.
Type de configuration : http
Point de terminaison des traces : https ://<your motlp endpoint>
Encodage : Json ou Proto
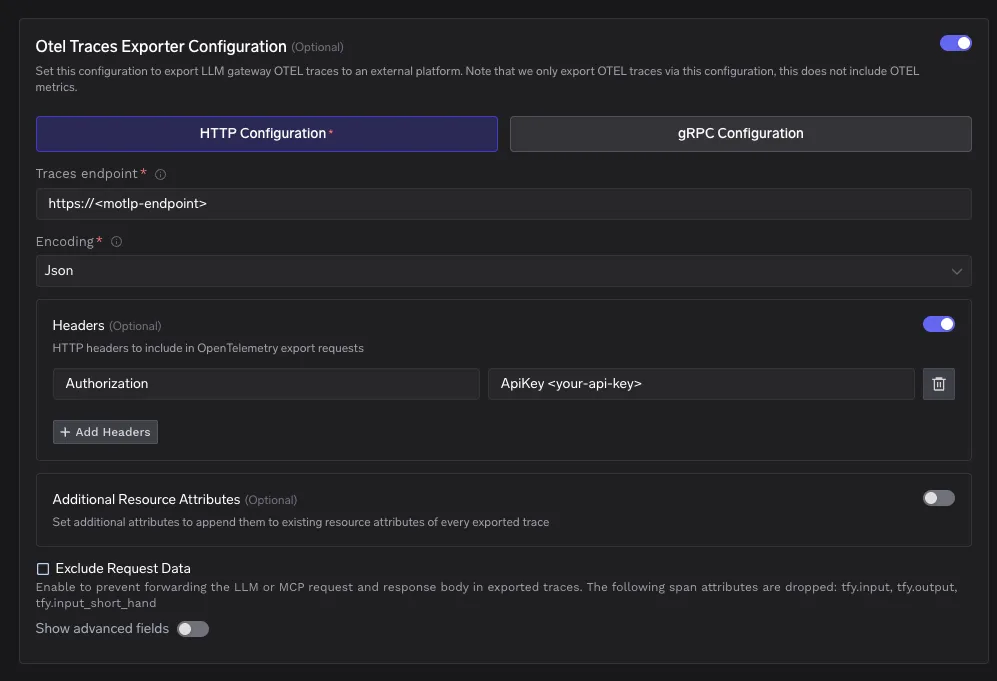
Ajoutez un en-tête HTTP nommé Authorization dont la valeur est au format ApiKey. Le préfixe APIKey est obligatoire.
Autorisation : ApiKey <your api key>
Enregistrez la configuration d'exportation OTEL. Ensuite, toutes les traces de passerelle seront automatiquement exportées vers Elastic Cloud.
Envoyez quelques demandes via la passerelle. Ouvrez ensuite Kibana et accédez à Observability, puis APM, puis Services et recherchez le service nommé passerelle tfy-llm. De là, vous pouvez inspecter les traces et les transactions pour chaque demande.
Le point de terminaison OTLP géré par Elastic Cloud prend en charge Json et Proto. Json est plus facile à lire pendant le débogage. Proto est plus efficace pour les gros volumes de données.
Vous pouvez définir des attributs de ressources supplémentaires dans la configuration de l'exportateur pour associer des balises cohérentes à chaque trace exportée. Cela est utile pour le filtrage au niveau de l'environnement et du locataire dans Elastic.
Si vous voyez une erreur d'authentification qui mentionne un préfixe APIKey, cela signifie que l'en-tête Authorization n'est pas correctement formaté et doit commencer par ApiKey. Si vous voyez le protocole HTTP 429, cela signifie que votre déploiement atteint peut-être des limites de débit d'ingestion et vous devez envisager de modifier votre plan ou d'ajuster l'échantillonnage.
Lorsqu'AI Gateway exporte des traces vers Elastic Cloud, vous disposez d'un seul endroit pour analyser les traces de passerelle avec les mêmes flux de travail d'observabilité que vous utilisez déjà pour le reste de votre stack. Elastic regroupe les journaux, les métriques, les traces et les vues APM sur une seule plateforme afin que votre trafic LLM ne soit pas isolé des signaux des applications et de l'infrastructure.
Vous pouvez déboguer une requête utilisateur de bout en bout en ouvrant la trace dans Elastic. L'interface utilisateur de Traces affiche le traçage distribué afin que vous puissiez voir le chemin complet d'exécution. La carte des services vous aide à comprendre les dépendances entre les services. Les détails de la transaction indiquent le calendrier et les métadonnées de la demande afin que vous puissiez identifier rapidement l'étape la plus lente.
Vous pouvez détecter les régressions plus tôt en surveillant les tendances plutôt que les incidents isolés. Elastic Observability fournit des tableaux de bord et des fonctionnalités d'analyse qui aident les équipes à passer de la télémétrie brute aux informations. Il inclut également des fonctionnalités de style de détection des anomalies qui peuvent faire apparaître des modèles inhabituels sur l'ensemble des signaux.
Vous pouvez exécuter des flux de travail de surveillance spécifiques à LLM dans Elastic. Elastic met en évidence les cas d'utilisation de l'observabilité LLM, tels que le suivi des erreurs de latence, les réponses, l'utilisation et les coûts. Avec AI Gateway comme limite d'exécution, vous pouvez rendre cette couverture cohérente pour chaque appel de modèle qui passe par la passerelle.
Vous pouvez faciliter le filtrage et le regroupement des traces en ajoutant des attributs de ressource dans la configuration de l'exportateur de passerelle. Cela est utile pour les métadonnées d'environnement et les balises de locataire afin que les équipes puissent découper les traces par production, étape de production ou unité commerciale au sein d'Elastic.
TrueFoundry AI Gateway vous offre une limite d'exécution cohérente pour l'ensemble du trafic LLM. Elastic Cloud vous offre une surface d'observabilité mature pour les traces et les flux de travail au niveau de service. En les connectant à OpenTelemetry, vous pouvez déboguer et exploiter les systèmes LLM avec la même rigueur que vous attendez de tout système distribué de production.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


