

May 23, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans le monde actuel axé sur les données, la recherche dans de grandes quantités de données pour trouver des éléments similaires est une opération fondamentale utilisée dans diverses applications, des bases de données aux moteurs de recherche et aux systèmes de recommandation. Ce processus, connu sous le nom de recherche de similarité, consiste à identifier des éléments similaires en fonction de certains critères.
Alors que les recherches traditionnelles dans les bases de données basées sur des critères numériques fixes (comme la recherche d'employés dans une fourchette salariale spécifique) sont simples, la recherche de similarité permet de répondre à des requêtes plus complexes. Par exemple, un utilisateur peut rechercher « chaussures », « chaussures noires » ou un modèle spécifique tel que « Nike AF-1 LV8 ». Ces questions peuvent être vagues et variées, obligeant le système à comprendre et à différencier des concepts tels que les différents types de chaussures.
La recherche de similarité est cruciale dans de nombreux domaines, notamment :
Le principal défi de la recherche de similarité est de traiter des données à grande échelle tout en comprenant avec précision les significations conceptuelles plus profondes des éléments recherchés. Les bases de données traditionnelles, qui reposent sur des représentations d'objets symboliques, sont insuffisantes dans de tels scénarios. Nous avons plutôt besoin de techniques plus avancées capables de gérer les représentations sémantiques des données et d'effectuer des recherches efficacement, même à grande échelle. Représentations, mesures de distance et différents algorithmes de recherche.
En tirant parti de la recherche de similarités, nous pouvons transformer des requêtes complexes et abstraites en informations exploitables, ce qui en fait un outil puissant dans divers domaines. Dans les sections suivantes, nous verrons comment fonctionne la recherche de similarité, en nous concentrant sur le rôle des représentations vectorielles, des métriques de distance et des différents algorithmes de recherche.
.webp)
Dans l'apprentissage automatique, nous représentons des objets et des concepts du monde réel sous forme de vecteurs, qui sont des ensembles de nombres continus appelés intégrations. Cette approche nous permet de saisir les significations sémantiques plus profondes des éléments. Lorsque des objets tels que des images ou du texte sont convertis en intégrations vectorielles, leur similitude peut être évaluée en mesurant la distance entre ces vecteurs dans un espace de grande dimension.
Par exemple, dans un espace vectoriel, des images similaires auront des vecteurs proches les uns des autres, tandis que des images différentes seront plus éloignées. Cela permet d'effectuer des opérations mathématiques pour trouver et comparer efficacement des éléments similaires.
.webp)
Plusieurs modèles sont utilisés pour générer ces intégrations vectorielles :
Ces modèles sont entraînés sur de grands ensembles de données et de tâches, ce qui leur permet de produire des intégrations qui représentent efficacement le contenu sémantique des éléments.
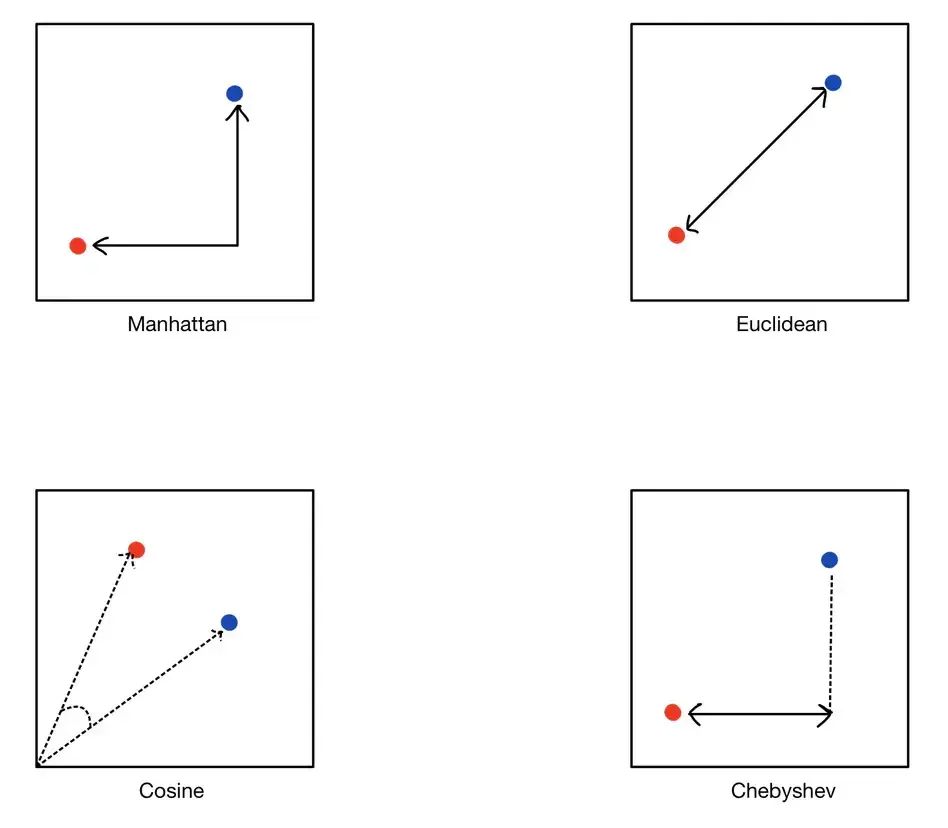
Pour déterminer dans quelle mesure deux intégrations vectorielles sont similaires, nous utilisons des métriques de distance. Ces métriques calculent la « distance » entre les vecteurs dans l'espace vectoriel, les distances plus petites indiquant une plus grande similitude.
La distance euclidienne mesure la distance en ligne droite entre deux points dans un espace de grande dimension. C'est la méthode la plus intuitive pour mesurer la distance, tout comme la distance géométrique que vous pouvez mesurer avec une règle. C'est utile lorsque les données sont denses et que le concept de distance physique est pertinent.
Formule :
.webp)
Également connue sous le nom de distance L1, la distance de Manhattan fait la somme des différences absolues de leurs coordonnées. Cette métrique convient aux structures de données de type grille et peut être visualisée comme la distance totale « d'un pâté de maisons » que l'on parcourrait entre les points d'une grille.
Formule :
.webp)
La similarité des cosinus mesure le cosinus de l'angle entre deux vecteurs, en se concentrant sur leur direction plutôt que sur leur amplitude. Cela est particulièrement utile pour les données textuelles, où l'amplitude du vecteur (fréquence des mots) peut varier, mais la direction (modèle d'utilisation des mots) est plus importante.
.webp)
La distance de Chebyshev mesure la distance maximale entre les coordonnées d'une paire de vecteurs. Il est souvent utilisé dans des scénarios de grille semblables à des échecs où vous pouvez vous déplacer dans n'importe quelle direction, y compris en diagonale.
.webp)
Le choix de la bonne métrique de distance dépend des caractéristiques et des exigences spécifiques de l'application. Voici quelques conseils pour sélectionner la métrique appropriée :
K-Nearest Nearest Neighbors (K-nN) est un algorithme populaire utilisé pour trouver les vecteurs les plus proches d'un vecteur de requête donné. Voici comment cela fonctionne, ses avantages et ses inconvénients :
.webp)
Pour remédier à l'inefficacité de k-NN avec de grands ensembles de données, les méthodes du voisin approximatif le plus proche (ANN) fournissent une alternative plus rapide, quoique moins précise. Les algorithmes ANN visent à trouver une « bonne estimation » des voisins les plus proches, en échangeant une certaine précision contre une certaine vitesse.
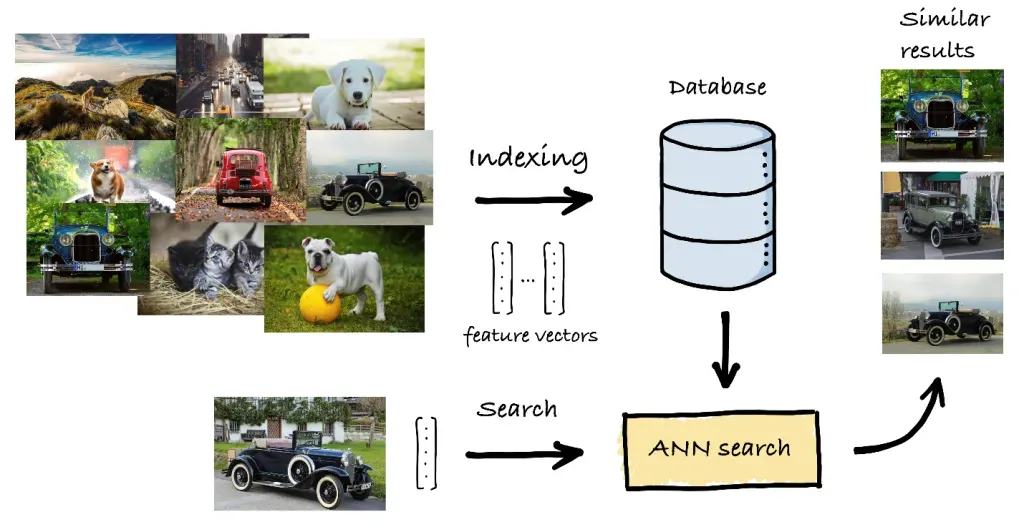
Lors de la mise en œuvre de la recherche de similarité dans la pratique, plusieurs bibliothèques et frameworks peuvent vous aider :
La recherche de similarité a un large éventail d'applications dans divers domaines, tirant parti de la capacité de trouver et de comparer des éléments similaires rapidement et avec précision. Voici quelques applications clés :
Les systèmes de recommandation utilisent la recherche de similarité pour suggérer des produits, du contenu ou des services en fonction des préférences et du comportement des utilisateurs.
La recherche de similarité est cruciale pour récupérer des images ou des vidéos visuellement similaires à partir de grandes bases de données.
En PNL, la recherche de similarité est utile dans diverses applications textuelles en trouvant des documents ou des phrases sémantiquement similaires.
Détecter les activités frauduleuses en identifiant des modèles et des anomalies qui s'écartent du comportement normal.
La recherche de similarité facilite le diagnostic médical et la recherche génétique en comparant les données des patients et les séquences génétiques.
L'un des principaux défis de la recherche de similarité est la nature des requêtes des utilisateurs. Les requêtes peuvent aller de termes très génériques tels que « chaussures » à des articles très spécifiques tels que « Nike AF-1 LV8 ». Le système doit être capable de discerner ces nuances et de comprendre comment les différents éléments sont liés les uns aux autres. Cela nécessite une compréhension approfondie de la signification sémantique des requêtes, qui va au-delà de la simple correspondance de mots clés.
L'évolutivité constitue un autre défi majeur. Dans les applications du monde réel, nous avons souvent affaire à des ensembles de données volumineux pouvant inclure des milliards d'éléments. La recherche efficace dans de tels volumes de données nécessite des techniques avancées et de puissantes ressources de calcul. Les systèmes de base de données traditionnels, conçus pour des correspondances exactes et des représentations symboliques, ont du mal à fonctionner correctement dans ces scénarios.
La recherche de similarité, également connue sous le nom de recherche vectorielle, joue un rôle central dans diverses applications modernes. En utilisant des intégrations vectorielles et des mesures de distance sophistiquées, la recherche de similarité nous permet de trouver et de comparer des éléments en fonction de leur signification sémantique. Voici les principaux points à retenir :
Pour exploiter pleinement la puissance de la recherche de similarités, il est essentiel de comprendre les principes sous-jacents et de choisir les outils et les techniques adaptés à vos besoins spécifiques. Que vous développiez un moteur de recommandation, un système de récupération basé sur le contenu ou un mécanisme de détection des fraudes, la recherche de similarité peut améliorer considérablement la précision et l'efficacité de vos solutions.
La recherche de similarité est une technique qui permet de trouver des éléments similaires dans de vastes ensembles de données. Il repose sur des intégrations vectorielles qui capturent la signification conceptuelle des données, en utilisant souvent des représentations vectorielles et des mesures de distance. Ce processus est crucial pour des applications telles que les recommandations de produits et la correspondance de texte, car il permet aux systèmes d'identifier les informations pertinentes de manière efficace et précise.
Pour effectuer une recherche de similarité, des objets tels que du texte ou des images sont d'abord convertis en intégrations vectorielles à l'aide de modèles spécialisés. Ensuite, les métriques de distance, telles que la distance euclidienne ou la distance cosinus, mesurent la « distance » entre ces vecteurs dans un espace de grande dimension. Des distances plus petites indiquent une plus grande similitude. Par ailleurs, les indicateurs de similarité, tels que la similarité des cosinus, évaluent directement la proximité, alors qu'un score plus élevé (plus proche de 1) signifie plus similaire.
Un excellent exemple de recherche de similarité est une plateforme de commerce électronique qui recommande des produits similaires à ceux qu'un utilisateur a consultés ou achetés. Cela permet aux acheteurs de découvrir des articles pertinents sans effort. La recherche d'images, qui permet de trouver des images visuellement similaires à partir de vastes bases de données, est une autre application clé utilisant la technologie de recherche de similarité.
Dans les systèmes alimentés par LLM, en particulier les pipelines RAG (Retrieval-Augmented Generation), la recherche de similarité fonctionne parallèlement au modèle en convertissant le texte en intégrations vectorielles qui capturent le sens sémantique. Une couche de récupération recherche ces vecteurs pour trouver le contenu le plus proche d'une requête, puis transmet les résultats au LLM en mesurant la distance entre ces vecteurs. Il est essentiel pour récupérer des informations pertinentes et générer des réponses contextuelles, améliorant ainsi considérablement la compréhension et l'utilité du modèle pour les utilisateurs.
La recherche de similarité est cruciale dans de nombreuses applications. Il améliore les recommandations de produits de commerce électronique, facilite la recherche d'images et de vidéos et améliore le traitement du langage naturel pour la correspondance de texte. Dans le secteur de la santé, il permet d'identifier des cas médicaux similaires et de transformer des données complexes en informations exploitables dans tous les secteurs.
La recherche sémantique repose sur la recherche de similarité pour trouver des éléments en fonction de leur signification, et pas seulement des mots clés. Il utilise des intégrations vectorielles pour représenter les données de manière sémantique. Alors que la recherche de similarité est la technique permettant de comparer ces vecteurs, la recherche sémantique est l'application qui l'exploite pour une compréhension contextuelle plus approfondie.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


