

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 18, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
La gestion de la configuration est un aspect important de l'ingénierie logicielle. Cet article mettra en lumière le pourquoi et le quoi du problème et expliquera les différentes solutions existantes.

L'approche de gestion de la configuration change à mesure que l'application évolue, à la fois en termes de trafic et de taille de l'équipe de développeurs. Pour illustrer le voyage, commençons par une simple application.
Il s'agit d'une application serveur simple qui se connecte à MongoDB et renvoie la liste des utilisateurs. Le code n'est qu'un pseudo code et n'est pas destiné à adhérer à un langage quelconque.

Configuration en hardcode dans l'application : un GRAND NON !

Si vous codez en dur l'URI MongoDB dans l'application, il sera très difficile de l'exécuter dans un autre environnement, comme les ordinateurs portables de vos collègues ou pour la production. Nous devons suivre les Méthodologie des applications à 12 facteurs ici pour séparer la configuration du code.
« CONFIGURATION SÉPARÉE DU CODE »
Maintenant, la question est de savoir ce que comprend la configuration d'une application? Citant https://12factor.net/config
Une application config est tout ce qui est susceptible de varier entre déploie (mise en scène, production, environnements de développement, etc.) Cela inclut :
1. Les descripteurs de ressources vers la base de données, Memcached et autres services de soutien
2. Informations d'identification pour des services externes tels qu'Amazon S3 ou Twitter
3. Valeurs par déploiement, telles que le nom d'hôte canonique pour le déploiement
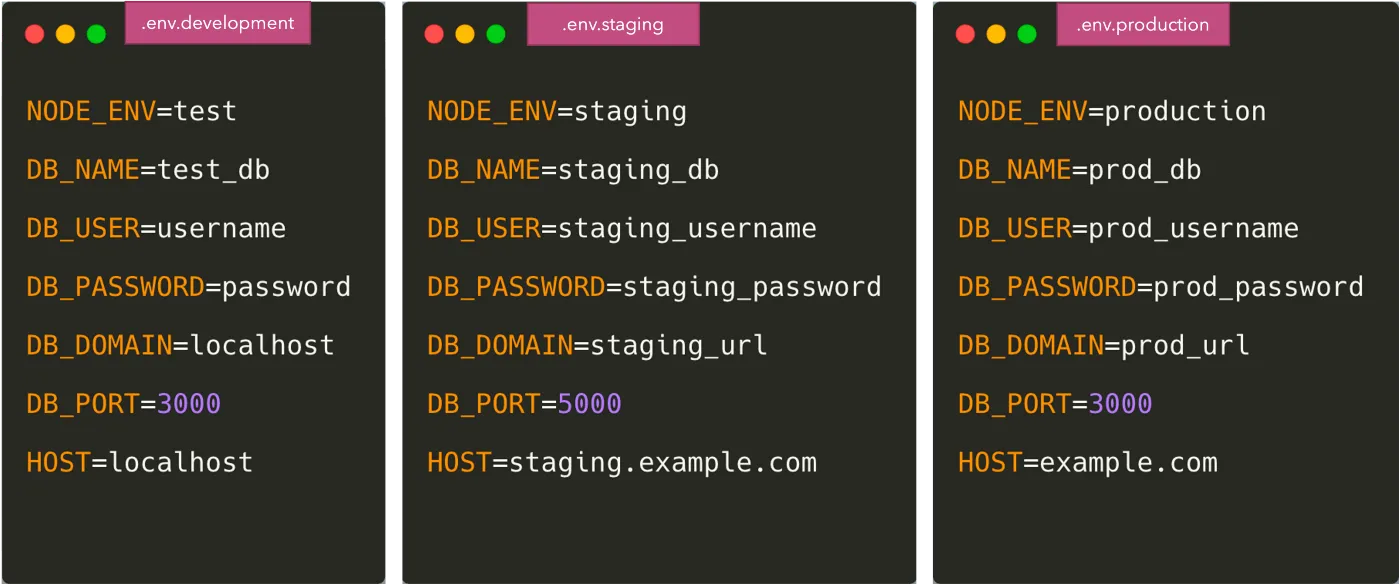
La méthode la plus simple et la plus courante pour séparer la configuration du code consiste à placer les variables dans un fichier .env.
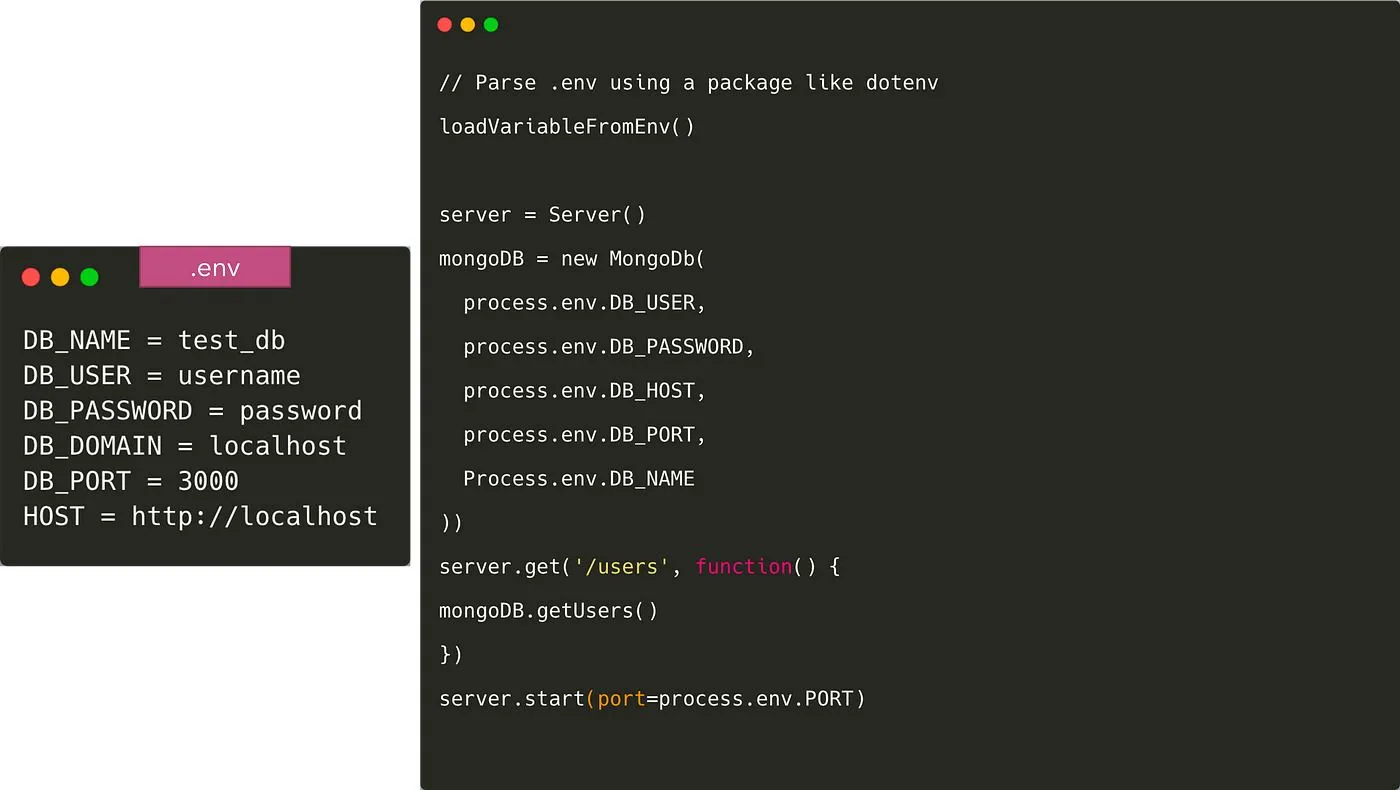
Une fois cela fait, nous devons charger les variables dans le code à partir du fichier .env. Il existe plusieurs packages pour faire comme doten c. et dotenv-expand. Le fichier .env n'est pas envoyé vers Git dans ce cas et chaque développeur remplace la variable en fonction de son propre environnement. Pour donner à tous les développeurs une idée des variables d'environnement à ajouter, nous validons généralement un fichier comme .env. exemple à Git.

Nous devrons également fournir les valeurs de ces variables dans les environnements de production et de production. Presque tous les systèmes de déploiement proposent un moyen de stocker et de fournir des variables d'environnement telles que ConfigMap et Secrets dans Kubernetes, ou S3 pour Elastic Container Service.
Nous devrons copier ces variables dans ces environnements et les synchroniser chaque fois que les développeurs ajoutent/suppriment des variables d'environnement. Une approche possible consiste à disposer d'un fichier .env distinct pour les environnements de préparation, de production, etc.

On peut suggérer de stocker ces fichiers dans Git, mais il existe un gros problème de sécurité dans ce cas, en particulier pour certaines des informations d'identification sensibles contenues dans les fichiers env.
Les gens utilisent différentes approches ici, mais certaines des méthodes les plus connues sont les suivantes :

Lorsque vous utilisez l'un de ces systèmes externes, nous avons maintenant réparti la configuration entre les fichiers .env et les secretmanagers. Certains paramètres non sensibles proviendront des fichiers .env et d'autres du stockage à distance des informations d'identification. Nous pouvons affirmer que nous pouvons stocker tous les paramètres dans le stockage distant, mais cela peut parfois être exagéré. Alors maintenant, nous en arrivons à :
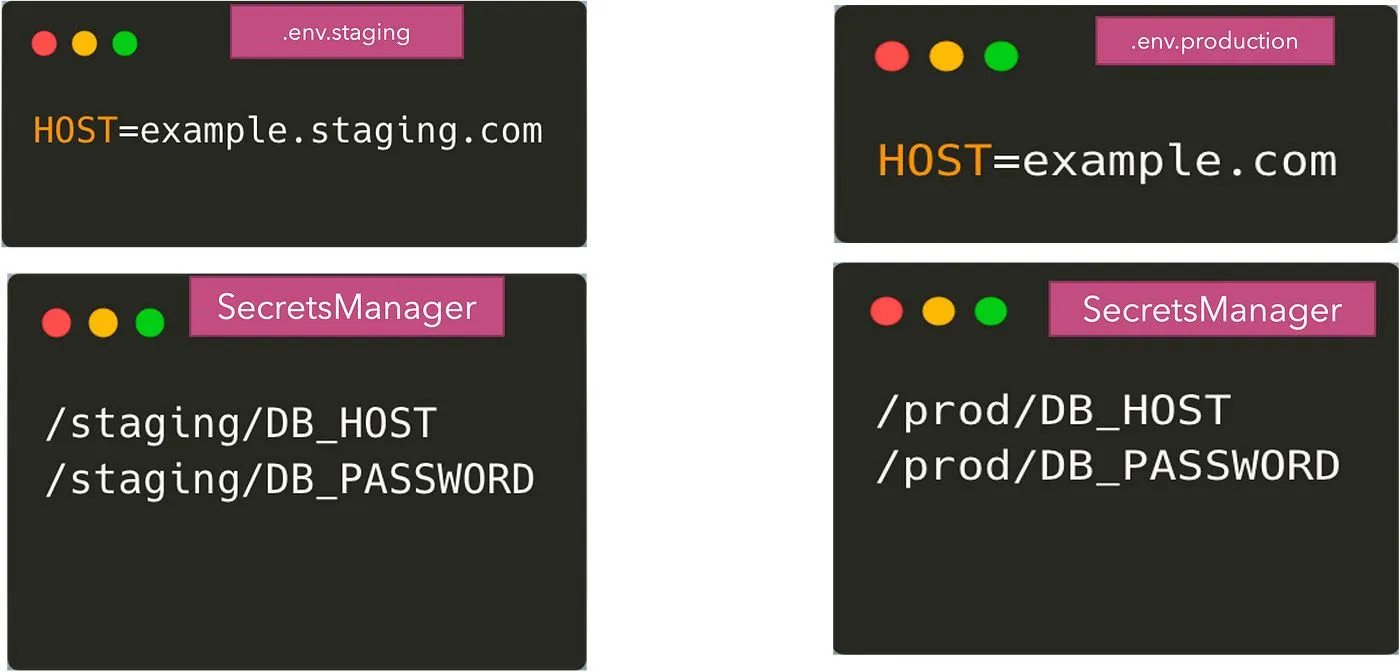
Notre application a maintenant besoin d'un code à lire à partir de ces deux sources de configuration. La lecture à partir des fichiers .env peut être effectuée à l'aide du package dotenv, cependant, l'obtention des variables d'environnement à partir des secretmanagers nous oblige à utiliser leurs API correspondantes pour obtenir les valeurs.

Cela permet de résoudre le problème de la sécurité de notre configuration et de suivre la méthodologie à 12 facteurs.
Cependant, écrire du code d'application pour obtenir des secrets finit par être une pratique répétitive dans laquelle chaque application doit désormais ajouter du code spécifique au gestionnaire de secrets pour obtenir les valeurs de l'API. Cela signifie également que si jamais nous changeons de fournisseur de secretsmanager, le code de toutes les applications doit changer. Pour résoudre ce problème, il existe plusieurs approches :
La gestion des configurations est complexe et doit être effectuée correctement dès le départ pour garantir que la rapidité des développeurs reste élevée sans pour autant sacrifier les aspects de sécurité. Kubernetes, qui est le plus utilisé aujourd'hui pour déployer des applications, possède sa propre configuration et sa propre gestion des secrets, que j'aborderai dans un autre article. De plus, si vous utilisez un autre moyen de gestion de la configuration, veuillez le mentionner dans les commentaires. J'aimerais en savoir plus et apprendre de vous !
True Foundry est une passerelle d'IA de niveau professionnel qui englobe un LLM, un MCP et des passerelles d'agents, permettant aux entreprises de se connecter, d'observer et de gérer l'accès aux modèles, aux outils, aux garde-corps et aux agents en toute sécurité à partir d'un plan de contrôle unique. L'AI Gateway permet de gérer des charges de travail agentiques qui sont les suivantes :
a) Sécurisé — résolution des problèmes de gestion des clés, d'authentification et d'autorisation
b) Efficace — optimisation des coûts, de la latence et des basculements multirégionaux
c) Sécuritaire pour l'avenir — permettant des connexions unifiées et composables entre les LLM, les MCP et les garde-corps de n'importe quel fournisseur
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


