

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 27, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
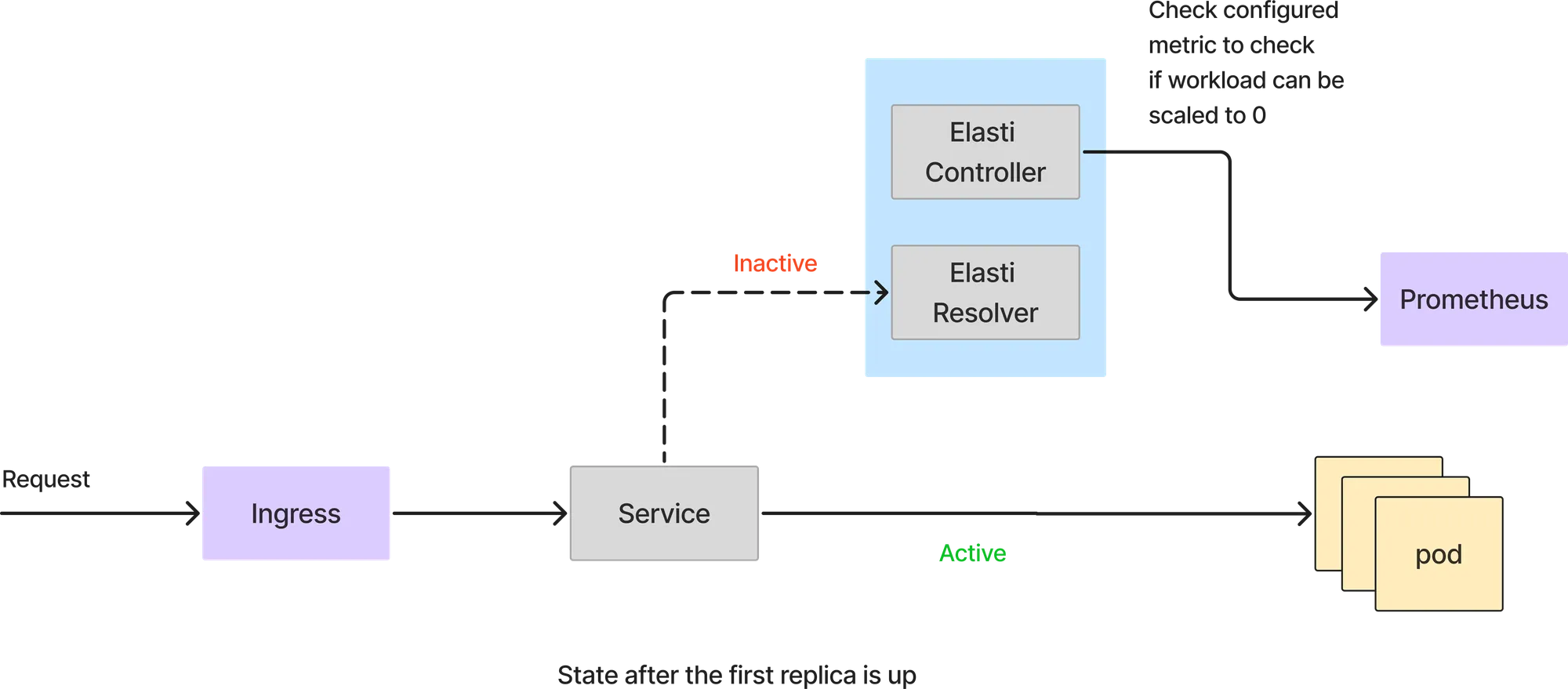
Élastique est une solution open source innovante conçue pour optimiser l'utilisation des ressources de Kubernetes en permettant aux services de réduire à zéro pendant les périodes d'inactivité et de les augmenter à la demande. Construit avec une architecture à deux composants (un contrôleur Kubernetes et un résolveur de requêtes), ELASTI gère de manière fluide la disponibilité des services tout en minimisant les coûts. Cet article se veut une présentation technique de son architecture, de son installation et de ses flux opérationnels, afin de vous permettre d'intégrer et d'étendre efficacement Elasti dans vos environnements Kubernetes.
💡 Cette fonctionnalité est incluse dans la suite de mise à l'échelle automatique de Truefoundry. Pour plus de détails, veuillez vous référer au documentation.
Bien que Kubernetes offre de solides capacités de mise à l'échelle grâce à HPA et à des solutions telles que KEDA, la mise à l'échelle jusqu'à zéro réplication reste un défi. Les approches existantes se répartissent généralement en deux catégories :
Elasti a été créé pour répondre à ces limites avec trois objectifs de conception clés :
Elasti comprend deux composants principaux qui fonctionnent en tandem pour gérer la mise à l'échelle des services :
Contrôleur (opérateur) :
Résolveur :
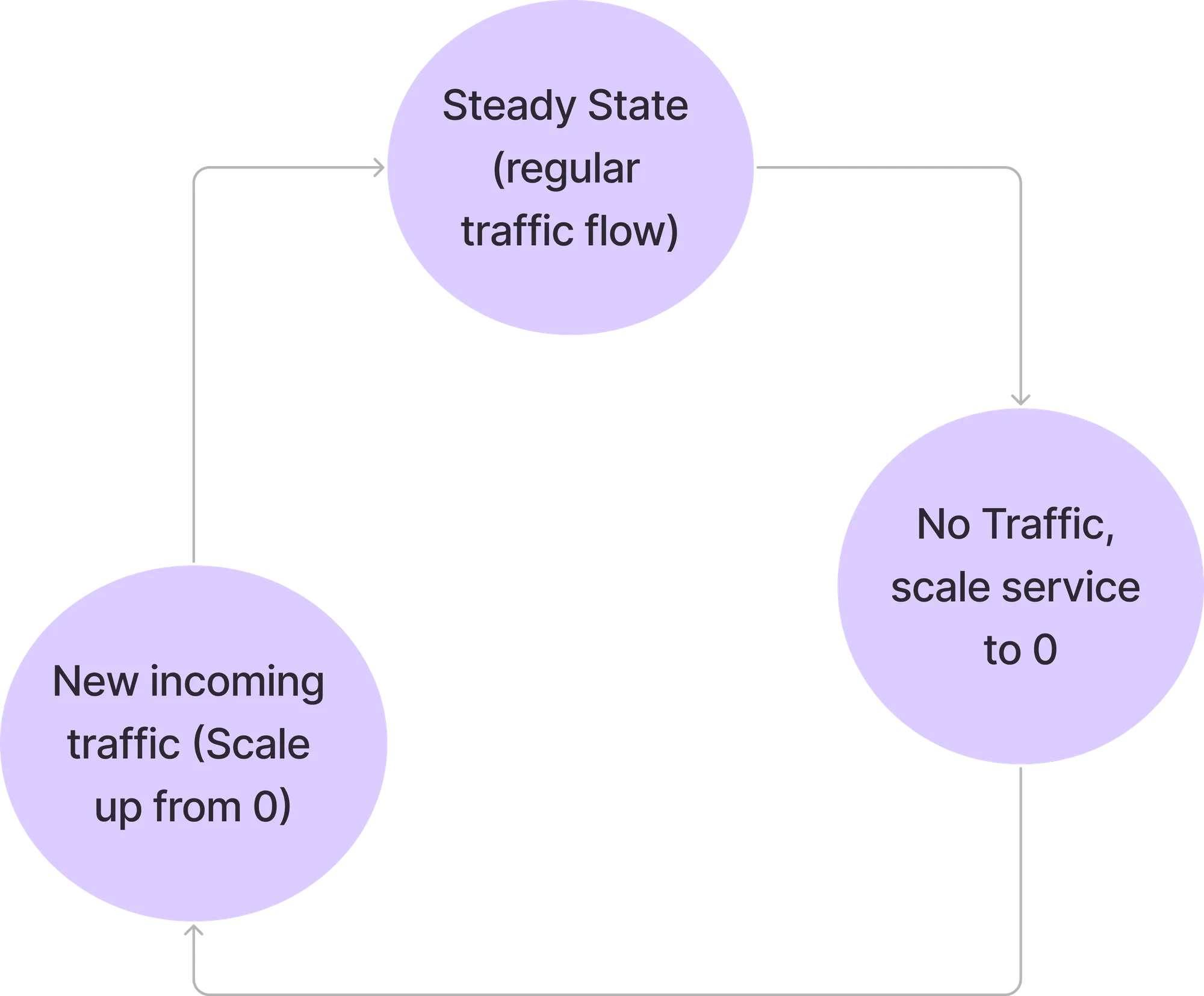
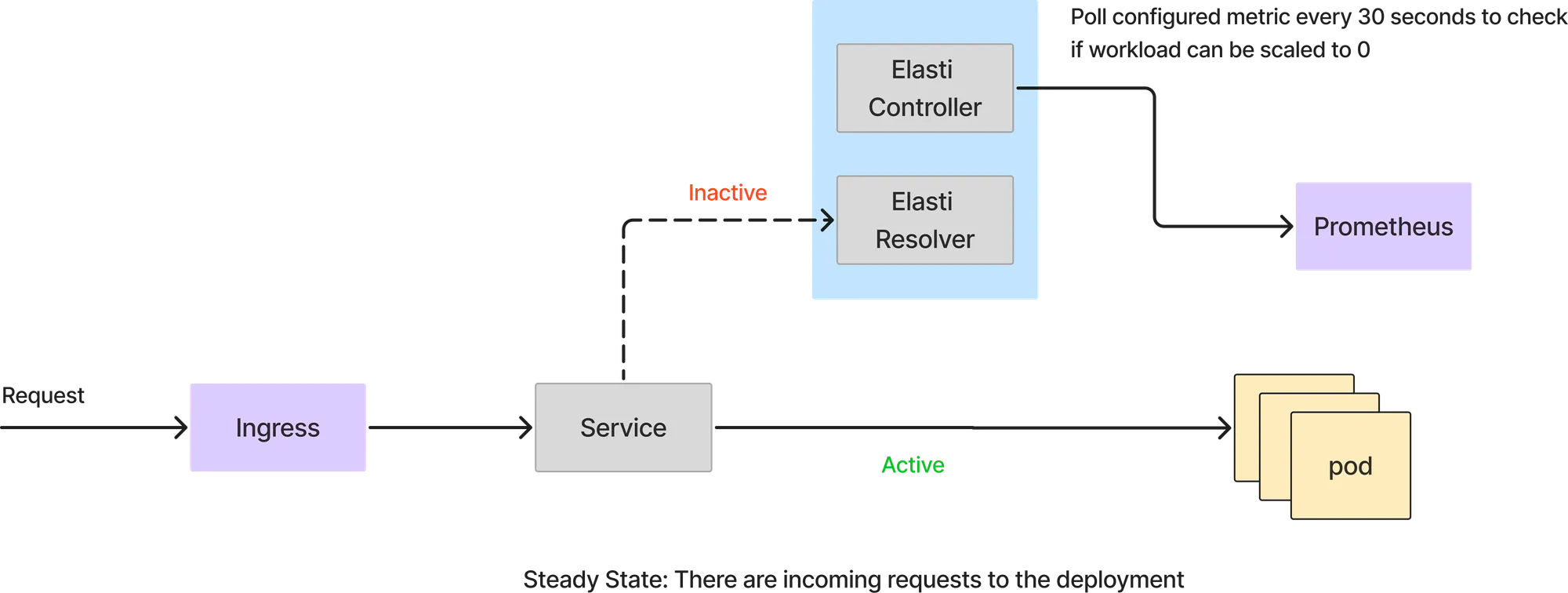
Dans ce mode, toutes les demandes sont traitées directement par les modules de service. Le résolveur Elasti n'entre pas dans le chemin de la requête. Le contrôleur Elasti continue d'interroger Prometheus avec la requête configurée et vérifie le résultat avec une valeur de seuil pour voir si le service peut être réduit.
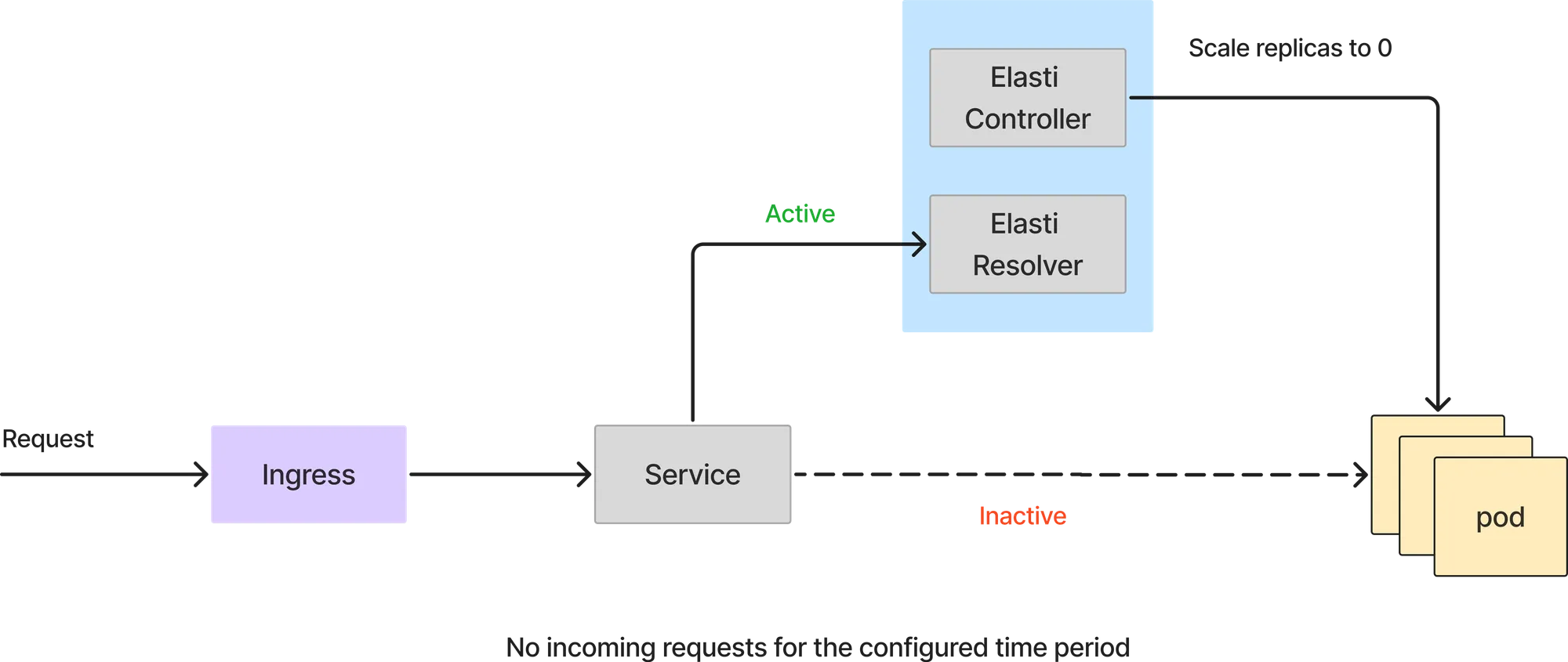
Si la requête de Prometheus renvoie une valeur inférieure au seuil, Elasti réduira le service à 0. Avant de passer à 0, il redirige les demandes à transmettre au résolveur Elasti, puis a modifié le déploiement/déploiement pour qu'il n'y ait aucune réplication. Il met également Keda en pause (si Keda est utilisé) pour l'empêcher d'étendre le service puisque Keda est configuré avec MinReplicas comme 1.
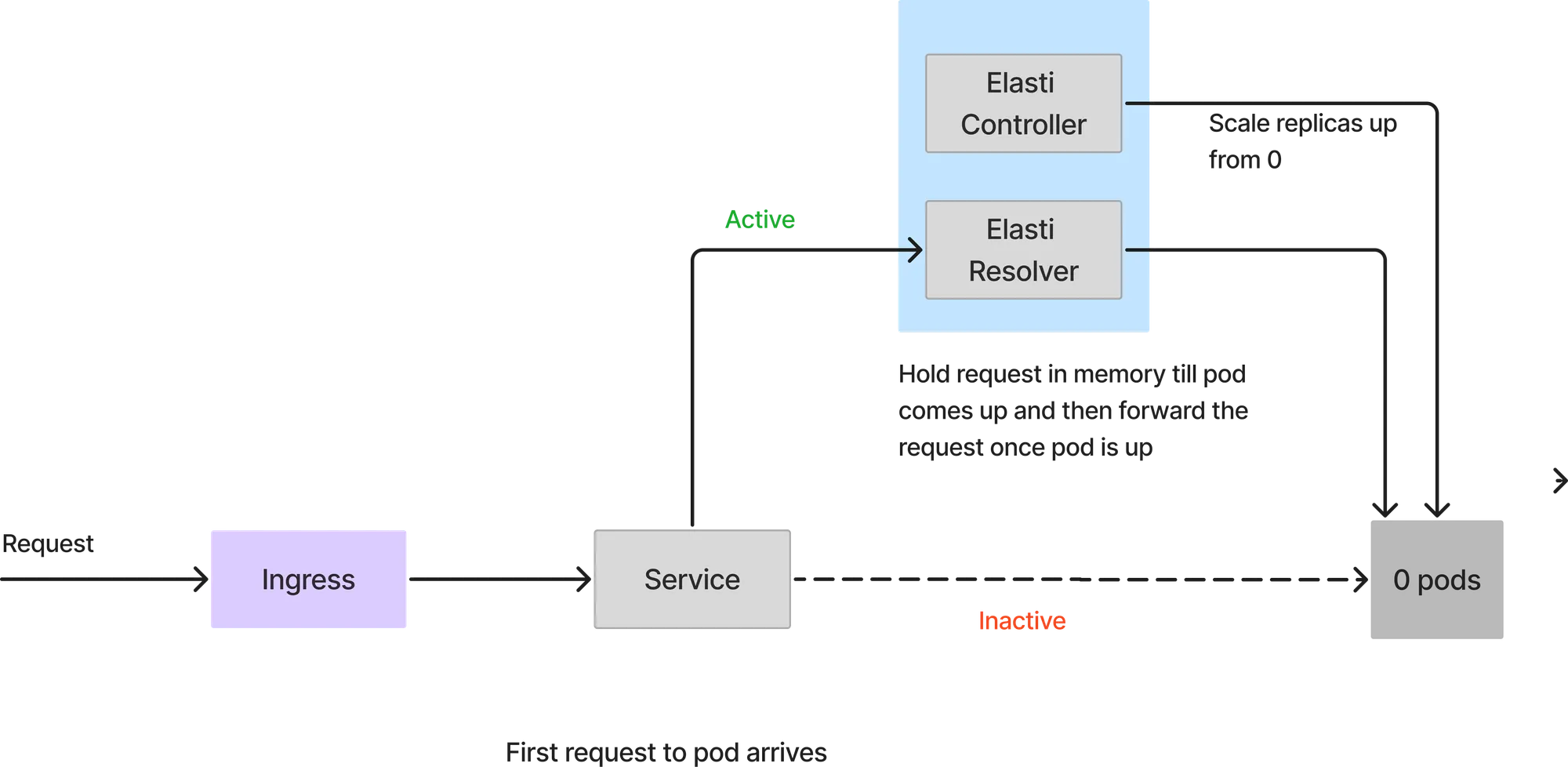
Comme le service est réduit à 0, toutes les demandes seront envoyées au résolveur Elasti. Lorsque la première demande arrive, Elasti étend le service aux MinTargetReplicas configurés. Il relance ensuite Keda pour poursuivre la mise à l'échelle automatique au cas où il y aurait une soudaine rafale de demandes. Il modifie également le service pour pointer vers les modules de service réels une fois que le module est activé. Les requêtes qui sont parvenues à ElastiResolver sont réessayées pendant 6 minutes et la réponse est renvoyée au client. Si le module met plus de 6 minutes à apparaître, la demande est supprimée.
démarrage du minikube
ou
type créer un cluster --name elasti-demo
ou
Créez un cluster local avec Docker Desktop
helm repo ajoute la communauté Prometheus https://prometheus-community.github.io/helm-charts
mise à jour du référentiel helm
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--surveillance des espaces de noms \
--create-namespace \
--set alertmanager.enabled=false \
--set grafana.enabled=false \
--set Prometheus.PrometheusSpec.ServiceMonitorSelectorNiluseShelmValues=False
Installez et configurez Prometheus dans surveillance espace de noms
Prometheus sera utilisé pour lire les métriques à partir de nginx ingress, qui seront ensuite utilisées par elasti pour interroger les métriques en fonction desquelles il décidera quand redimensionner un service vers et à partir de zéro.
helm repo ajoute ingress-nginx https://kubernetes.github.io/ingress-nginx
mise à jour du référentiel helm
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx \
--set controller.metrics.enabled=true \
--set controller.metrics.ServiceMonitor.enabled=True \
--create-namespace
Déploie un contrôleur Nginx dans le entrée nginx espace de noms
Le contrôleur sera utilisé pour acheminer le trafic vers notre service de démonstration httpbin.
4. Configuration d'Elasti :
helm repo ajoute elasti https://charts.truefoundry.com/elasti
mise à jour du référentiel helm
helm install elasti oci : //tfy.jfrog.io/tfy-helm/elasti \
--namespace elasti --create-namespace
Installation d'Elasti avec helm dans l'espace de noms elasti
Une fois Elasti installé, vous devriez voir ses deux composants clés fonctionner :
Pour des configurations plus avancées, consultez valeurs.yaml pour voir toutes les options de configuration dans le fichier de valeurs helm.
kubectl crée un espace de noms elasti-demo
kubectl apply -n elasti-demo -f \
https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-application.yaml
Déploiement d'un service httpbin dans elasti-demo espace de noms
Ce service httpbin sera utilisé pour montrer comment configurer un service pour gérer le trafic via elasti.
Créez un fichier yaml avec la configuration suivante pour un ElastiService.
Version de l'API : elasti.truefoundry.com/v1alpha1
type : ElastiService
métadonnées :
nom : httpbin-elasti
espace de noms : elasti-demo
spécification :
Répliques MinTarget:1
service : httpbin
Période de recharge : 5
Référence de la cible d'échelle :
Version de l'API : applications/v1
type : déploiements
nom : httpbin
déclencheurs :
- type : prométhée
métadonnées :
requête : somme (taux (nginx_ingress_controller_nginx_process_requests_total [1m]) ou vecteur (0)
Adresse du serveur : http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
seuil : « 0,5 »
demo-elasti-service.yaml
Une fois le fichier créé, appliquez l'ElastiService
kubectl apply -f https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-elastiService.yaml
Voici quelques champs clés de la spécification CRD :
Répliques Mintarget: Nombre minimal de répliques à afficher lors de l'arrivée de la première demande.Période de refroidissement: Temps minimum (en secondes) à attendre après la mise à l'échelle avant d'envisager une réductiondéclencheurs: liste des conditions qui déterminent le moment de la réduction d'échelle (ne prend actuellement en charge que les métriques Prometheus)Echelle Target Ref: référence à la cible d'échelle similaire à celle utilisée dans HorizontalPodAutoscaler.Pour plus de détails et pour configurer un ElastiService pour votre cas d'utilisation, consultez ce document.
Grâce à ces étapes, vous disposez désormais de :
Cette configuration vous permet de tester des scénarios de routage réels et de surveiller les performances et les indicateurs de votre trafic entrant.
Pour tester cette configuration, vous pouvez envoyer des demandes à l'équilibreur de charge Nginx et surveiller les modules de notre service de démonstration.
kubectl port-forward svc/nginx-ingress-nginx-controller \
-n entrée-nginx 80:80:80
Redirection de port vers le contrôleur Nginx
kubectl get pods -n elasti-demo -w
Démarrer une surveillance sur le service httpbin
Vous pouvez maintenant envoyer une demande à http://localhost:8080/httpbin et vous pouvez voir que le service est mis à l'échelle à 1 réplique par elasti.
curl -v http://localhost:8080/httpbin
Envoyer une demande au service httpbin
Le service sera ensuite réduit à nouveau après aucune activité pendant Période de refroidissement secondes spécifiées dans l'ElastiService (5 secondes dans ce cas).
Pour désinstaller Elasti, vous devrez d'abord supprimer tous les ElastiServices installés. Il vous suffit ensuite de supprimer le fichier d'installation.
kubectl supprime elastiservices --all
helm uninstall elasti -n elasti
kubectl supprime l'espace de noms elasti
Elasti est le meilleur choix lorsque vous :
Elasti a été développé pour répondre à un défi spécifique à Kubernetes : implémenter une véritable scale-to-zero sans sacrifier l'intégrité des requêtes ni imposer de surcharge excessive. Cette solution prend en charge la mise à l'échelle automatique native avec HPA et KEDA, garantissant ainsi que les configurations de service existantes restent inchangées tout en optimisant l'utilisation des ressources.
En ouvrant cet outil à source ouverte, nous visons à fournir une solution robuste pour les environnements qui nécessitent une véritable évolutivité vers zéro, aucune perte de demandes et une empreinte opérationnelle minimale.
Les contributions et les commentaires de la communauté sont les bienvenus. Explorez le document de développement pour plus de détails.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


