




October 26, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Aujourd'hui, True Foundry lance une série d'études approfondies sur l'apprentissage automatique dans le cadre de laquelle nous nous entretenons avec des leaders du ML et de la science des données dans les entreprises utilisant le ML pour explorer les cas d'utilisation et les flux de travail du ML au sein de leurs organisations. Dans le cadre de cette série, nous allons héberger et approfondir le ML Stack d'entreprises telles que Gong, StichFix, SalesForce, Gusto, Simple, et bien d'autres encore.
📌
Dans cette série, nous explorons le monde de l'apprentissage automatique pour dévoiler le spectre des applications de machine learning et des configurations d'infrastructure dans tous les secteurs.
Nos conversations tourneront autour de quatre thèmes clés :
1. Cas d'utilisation de l'apprentissage automatique pour les entreprises
2. Comment ont-ils construit leur infrastructure d'apprentissage automatique, y compris le pipeline de formation et d'expérimentation, le déploiement et le service, la surveillance, et les ont-ils optimisés en termes de coûts et de latence en cours de route ?
3. Défis rencontrés lors de la mise en place d'une suite de machines virtuelles, avec des défis spécifiques liés à l'industrie
4. Un aperçu des innovations de pointe appliquées au cours du processus de création et de mise à l'échelle de l'infrastructure ML.
Pour lancer la première discussion de la série, nous avons parlé à Noam Lotner de Gong. Gong est une plateforme de renseignement fiscal. Il permet aux équipes chargées des recettes de réaliser leur plein potentiel en dévoilant la réalité des clients à partir des conversations de l'équipe des recettes. Gong analyse les interactions avec les clients par téléphone, e-mail, Web, etc., afin de fournir les meilleures informations aux équipes chargées des ventes afin qu'elles puissent les utiliser pour conclure davantage de transactions.
Noam Lotner est chef de l'équipe des opérations de recherche chez Gong. Il construit la plate-forme opérationnelle du groupe de recherche AI/ML, en automatisant les processus de publication des modèles, la gestion des expériences et les tests de performance, en développant des outils d'étiquetage et de création de jeux de données et en permettant un accès sécurisé aux sources de données de production.
Gong analyse les interactions avec les clients par téléphone, e-mail, Web, etc. L'apprentissage automatique devient d'autant plus essentiel pour analyser les interactions commerciales et fournir des informations aux équipes chargées des recettes. Les algorithmes de machine learning peuvent automatiser des tâches qui étaient auparavant effectuées manuellement, telles que l'analyse des appels vidéo, la transcription et l'analyse des appels téléphoniques commerciaux. Cela permet de gagner du temps et d'améliorer l'efficacité du processus de vente.
Bien que nous ayons posé cette question à Gong, nous constatons que toutes les entreprises SaaS :
📌
Nombre de modèles : Nombre de clients X Types de modèles
📌
« Nous utilisons le même modèle de base pour tout le monde. Nous permettons également aux clients de suivre une formation sur des modèles spécifiques pour leur propre contenu. »
Afin d'optimiser les coûts, Gong utilise des serveurs multimodèles dans la couche d'inférence, car exécuter des modèles séparés sur des machines distinctes signifierait un système coûteux.
Voici un blog détaillé de Gong qui parle de l'utilisation du ML dans les ventes B2B
Chez Gong, le système ML est structuré selon l'organisation ML.
Dans ce blog (ainsi que dans une série de discussions), nous aborderons plus en détail les défis de Research Side infra pour Gong
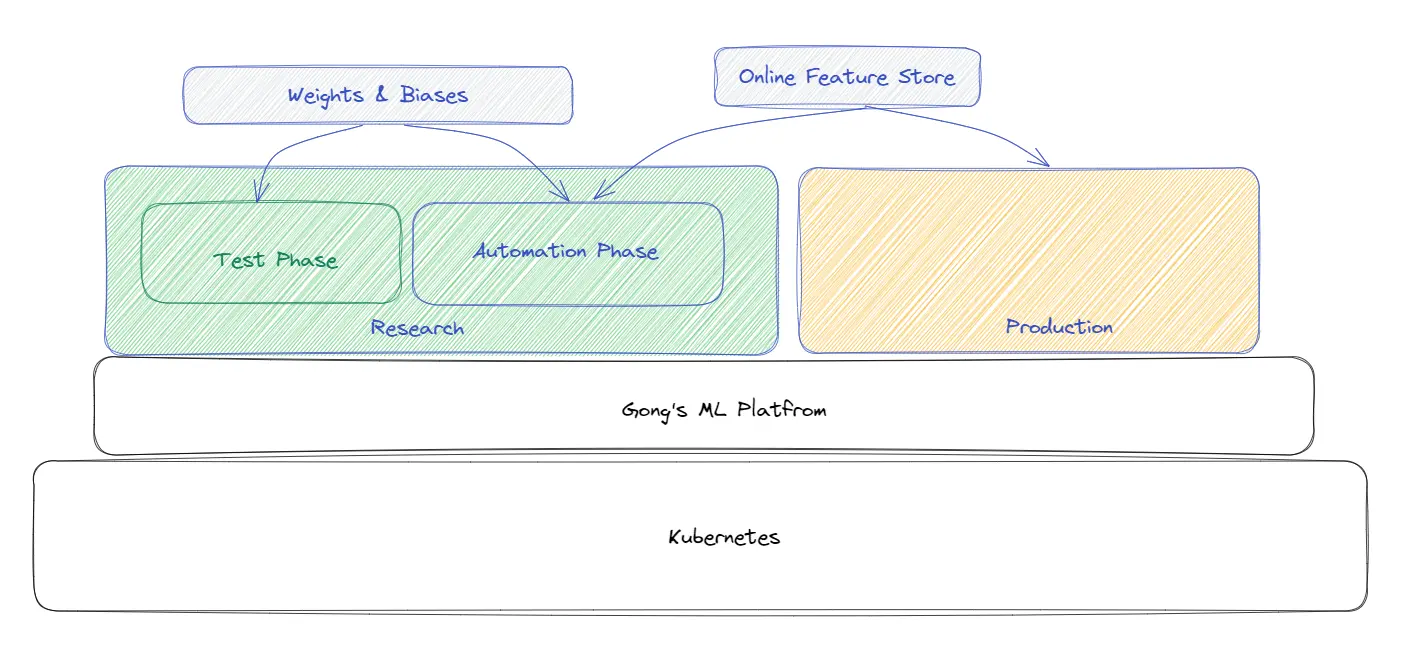
Pour permettre aux chercheurs de faire tourner facilement les machines, l'ensemble de la pile est configuré sur Kubernetes pour le Research Infra. La plupart des modèles de l'équipe de recherche n'utilisent pas les fonctionnalités en ligne.
Nuage: La majeure partie de l'infrastructure se trouve sur AWS et fonctionne également avec d'autres fournisseurs de cloud dans une capacité légèrement inférieure.
Gestion de l'infrastructure: les pipelines utilisent en fait les modèles spécifiques à chaque client. Il y a une machine qui s'affiche et gère tous les appels de cette entreprise
Tout ce qui est fait au sein de l'équipe de recherche est maintenant transféré vers Kubernetes. Une partie du travail de Noam consiste à aider son équipe à accéder automatiquement aux ressources depuis le cloud Kubernetes. Il s'agit actuellement d'un effort continu.
📌
« Je recommande à tous ceux qui se lancent dans ce domaine de réfléchir très tôt à l'échelle et à la façon dont leur groupe va fonctionner. »
« Je pense que la plupart des systèmes MLOps nécessitent Kubernetes pour gérer les ressources. Je ne vois aucune plateforme dans le futur capable de faire quoi que ce soit en rapport avec les MLOps sans utiliser Kubernetes. »
Quelques points importants à noter :
📌
« Mon point de vue est que Gong avait besoin de créer cette plateforme »
Rien ne peut être plus important pour une entreprise SaaS que la sécurité. Le pipeline ML doit donner la priorité à la sécurité en raison de la confidentialité des données lors du traitement des données sensibles des clients et pour contrôler les accès non autorisés.
J'espère que la première série de blogs des TrueML Talks a pu vous donner des informations précieuses sur la façon dont vous pouvez envisager de créer votre infrastructure de recherche en apprentissage automatique pour alimenter vos équipes de ML. #MLOps #MachineLearning #DataScience #DevOps #ModelOps #AIInfrastructure
Dirigez-vous vers notre deuxième épisode des conférences TrueML où nous discutons avec le responsable de la plateforme chez Stitch. Continuez à regarder le TrueML série youtube et retrouvez tous les épisodes de la série de blogs TrueML ici -
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


