



May 21, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Nous sommes de retour avec un autre épisode de True ML Talks. Dans ce cadre, nous approfondissons à nouveau les applications MLOps et LLMS chez GitLab et nous discutons avec Rayon de Monmayuri.
Monmayuri dirige le secteur de la recherche sur l'IA chez GitLab en mettant l'accent sur les LLM au cours de la dernière année. Auparavant, elle était responsable de l'ingénierie au sein de la division ModelOps de GitLab. Elle a également travaillé avec d'autres entreprises comme Microsoft, eBay.
📌
Nos conversations avec Monmayuri porteront sur les aspects suivants :
- Cas d'utilisation du ML et du LLM sur GitLab
- Évolution de l'infrastructure ML de GitLab pour prendre en charge les grands modèles de langage (LLM)
- Le parcours de GitLab avec les LLM : de l'open source à la mise au point
- Formation de grands modèles de langage à GitLab
- Triton contre PyTorch, GPU assemblés et traitement par lots dynamique pour l'inférence LLM
- Défis et recherches liés à l'évaluation des LLM chez GitLab
- L'architecture LLM de GitLab et l'avenir des LLM
L'apprentissage automatique (ML) transforme le cycle de vie du développement logiciel, et GitLab est à la pointe de cette innovation. GitLab utilise le machine learning pour responsabiliser les développeurs tout au long de leur parcours, qu'il s'agisse de créer des problèmes, de fusionner des demandes ou de déployer des applications.
L'un des cas d'utilisation les plus intéressants du ML chez GitLab concerne les grands modèles de langage (LLM). GitLab utilise LLMS et GenAI pour développer de nouvelles fonctionnalités pour ses produits, telles que la complétion de code et la synthèse des problèmes.
GitLab a joué un rôle de premier plan dans l'utilisation de grands modèles de langage (LLM) pour responsabiliser les développeurs. GitLab a donc dû faire évoluer son infrastructure de machine learning pour prendre en charge ces modèles complexes.
Pour relever les défis mentionnés ci-dessus, GitLab a apporté un certain nombre de modifications à son infrastructure de machine learning. Ces changements peuvent être classés dans les domaines suivants :
GitLab a joué un rôle de premier plan dans l'utilisation de grands modèles de langage (LLM) pour responsabiliser les développeurs. Au début, GitLab a commencé par utiliser LLM open source, comme Salesforce code gen. Cependant, à mesure que le paysage a changé et que les LLM sont devenus plus puissants, GitLab a décidé d'affiner ses propres LLM pour des cas d'utilisation spécifiques, tels que la génération de code.
La mise au point des LLM nécessite un investissement important dans l'infrastructure, car ces modèles sont très volumineux et complexes. GitLab a dû développer de nouveaux pipelines de formation et de déploiement pour les LLM, ainsi que de nouvelles méthodes de gestion de son infrastructure ML dans un environnement distribué.
L'un des principaux défis auxquels GitLab a été confronté pour peaufiner les LLM est de trouver le juste équilibre entre coût et latence. Les LLM peuvent être très coûteux à former et à déployer, et ils peuvent également être lents à générer des résultats. GitLab a dû expérimenter différentes tailles de clusters, configurations de GPU et techniques de traitement par lots pour trouver le bon équilibre pour ses besoins.
Un autre défi auquel GitLab a été confronté est de garantir la précision et la fiabilité de ses LLM. Les LLM peuvent être entraînés sur des ensembles de données volumineux de texte et de code, mais ces ensembles de données peuvent également contenir des erreurs et des biais. GitLab a dû développer de nouvelles techniques pour évaluer et débiaiser ses LLM.
Malgré les défis, GitLab a réalisé des progrès significatifs dans l'utilisation des LLM pour responsabiliser les développeurs. GitLab est désormais en mesure de former et de déployer des LLM à grande échelle, et utilise ces modèles pour développer de nouvelles fonctionnalités et de nouveaux produits qui rendront le processus de développement logiciel plus efficace et plus agréable.
La formation de grands modèles linguistiques (LLM) est une tâche difficile qui nécessite un investissement important dans l'infrastructure et les ressources. GitLab a joué un rôle de premier plan dans l'utilisation des LLM pour responsabiliser les développeurs, et l'entreprise a beaucoup appris en cours de route.
Voici quelques idées et leçons tirées de l'expérience de GitLab en matière de formation des LLM :
Outre les informations ci-dessus, GitLab a également tiré un certain nombre de leçons précieuses sur l'importance d'une bonne compréhension du modèle de base et des données d'entraînement. Par exemple, GitLab a découvert qu'il était important de connaître la construction du modèle de base et de savoir comment organiser les données d'entraînement afin de les optimiser pour le cas d'utilisation souhaité.
GitLab utilise Triton pour l'inférence LLM car il est mieux adapté à l'adaptation au volume élevé de requêtes que GitLab reçoit. Triton est également plus facile à encapsuler et à dimensionner que d'autres serveurs modèles, tels que les serveurs PyTorch.
GitLab n'a pas encore expérimenté les serveurs modèles TGI ou VLLM de Hugging Face, car ceux-ci en étaient encore aux premiers stades de développement lorsque GitLab a déployé pour la première fois son pipeline d'inférence LLM.
En matière de traitement par lots dynamique, la stratégie de GitLab consiste à optimiser en fonction du cas d'utilisation spécifique, de la charge, du niveau de requête, du volume et du nombre de GPU disponibles. Par exemple, si GitLab possède 500 GPU pour un modèle 7B, il peut utiliser une stratégie de traitement par lots différente de celle s'il ne dispose que de quelques GPU pour un modèle plus petit.
GitLab utilise également un ensemble de GPU pour gérer les requêtes. Cela signifie que GitLab utilise un mélange de différents types de GPU, y compris des GPU hautes performances et des GPU moins performants. GitLab équilibre la charge des requêtes sur l'ensemble des GPU afin d'optimiser les performances et les coûts.
Voici quelques conseils pour concevoir une architecture permettant d'organiser des GPU et d'optimiser l'équilibrage de charge :
Voici quelques exemples spécifiques de la manière dont GitLab a optimisé son architecture pour les GPU assemblés et le traitement par lots dynamique :
En suivant ces conseils, vous pouvez concevoir une architecture capable de gérer efficacement de grands volumes de demandes d'inférence LLM.
Nous avons également essayé le streaming, et je pense que nous étudions également le streaming pour nos tiers - Monmayuri
L'évaluation des performances des grands modèles de langage (LLM) est une tâche difficile. GitLab a travaillé sur ce problème et a dû faire face à plusieurs défis, notamment :
GitLab répond à ces défis en :
L'objectif de GitLab est de développer une approche évolutive et basée sur les données pour évaluer les LLM. Cette approche aidera GitLab à s'assurer que ses LLM fonctionnent bien en production et répondent aux besoins de ses utilisateurs.
GitLab mène également des recherches sur de nouvelles méthodes d'évaluation des LLM. Parmi les axes de recherche explorés par GitLab, citons :
Les recherches de GitLab sur l'évaluation des LLM sont en cours. GitLab s'engage à développer de nouvelles méthodes innovantes pour évaluer les LLM afin de s'assurer que ses LLM répondent aux besoins de ses utilisateurs.
L'architecture LLM de GitLab est une approche complète de la formation, de l'évaluation et déploiement de LLM. L'architecture est conçue pour être flexible et évolutive, afin que GitLab puisse facilement adopter de nouvelles technologies et répondre aux besoins de ses utilisateurs.
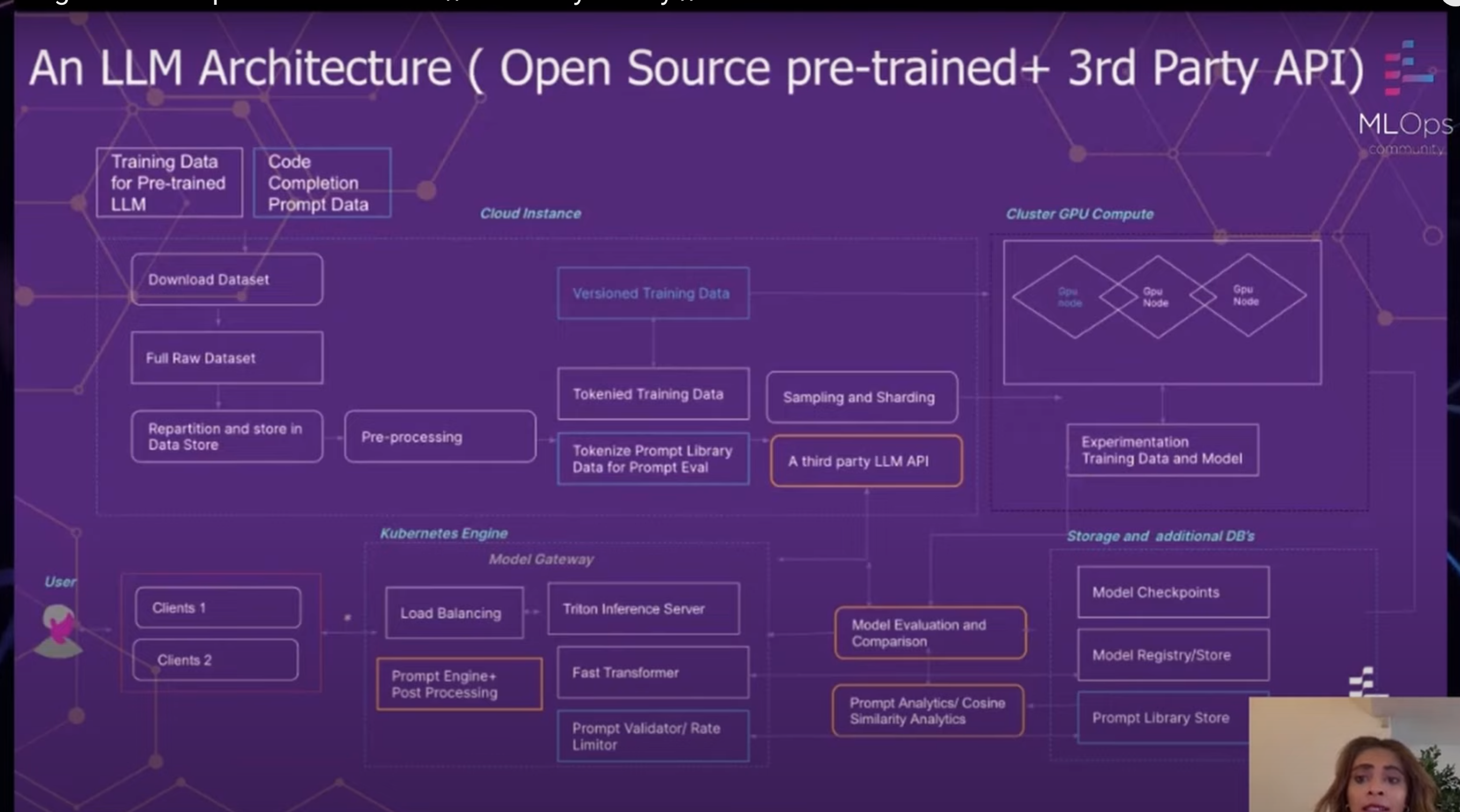
L'architecture comprend plusieurs éléments clés :
L'architecture LLM de GitLab est un outil puissant qui permet à GitLab de former, d'évaluer et de déployer des LLM à grande échelle. L'architecture est conçue pour être flexible et évolutive, afin que GitLab puisse facilement adopter les nouvelles technologies et répondre aux besoins de ses utilisateurs.
Les LLM sont encore une technologie relativement nouvelle, mais ils ont le potentiel de révolutionner de nombreux secteurs. GitLab estime que les LLM auront un impact significatif sur l'industrie du développement de logiciels.
GitLab utilise déjà les LLM pour améliorer ses produits et services. Par exemple, GitLab utilise des LLM pour générer des suggestions de code, expliquer les vulnérabilités et améliorer l'expérience utilisateur de ses produits.
GitLab estime que d'autres organisations devraient également investir dans les LLM. Les LLM ont le potentiel d'améliorer la productivité, l'efficacité et la qualité dans de nombreux secteurs.
GitLab recommande aux organisations d'investir dans les domaines suivants pour garder une longueur d'avance dans le domaine du LLM :
En investissant dans ces domaines, les organisations peuvent garder une longueur d'avance dans le domaine du LLM et bénéficier des avantages de cette puissante technologie.
Continuez à regarder le TrueML série youtube et en lisant le TrueML série de blogs.
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


