






October 26, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Nous sommes de retour avec un autre épisode de True ML Talks. Dans ce cadre, nous explorons en profondeur l'API de recommandation de Slack, SlackGPT et LLM et nous discutons avec Katrina Ni.
Katrina Ni est ingénieure ML senior et membre principale de l'équipe technique de Slack. Elle y a dirigé l'équipe ML et a travaillé avec l'API de recommandation, la détection des spams et toutes les fonctionnalités du produit.
📌
Nos conversations avec Katrina porteront sur les aspects suivants :
- Cas d'utilisation du ML et de l'IA de génération sur Slack
- L'infrastructure de Slack axée sur le machine learning
- Formation, validation, déploiement et surveillance pour l'API Recommend chez Slack
- Mesurer l'impact commercial de l'API Recommend
- Impact de la confidentialité des clients sur l'infrastructure de formation
- Développement de Slack GPT et défis liés à la formation LLMS
- L'avenir de l'ingénierie rapide dans les modèles de langage
- Se tenir au courant des avancées en matière de LLM
Slack s'appuie sur des équipes d'ingénierie de données qualifiées et sur des solutions d'entrepôt de données robustes. Ils utilisent Airflow pour la planification des tâches et le traitement des mégadonnées, fournissant ainsi un soutien essentiel aux tâches de machine learning.
L'infrastructure de Slack est basée sur Kubernetes et prend en charge leur architecture de microservices. Leur équipe cloud a développé un framework basé sur Kubernetes pour faciliter le déploiement de microservices, offrant flexibilité et évolutivité.
Pour répondre à leurs besoins spécifiques, Slack a développé une boutique de fonctionnalités personnalisée au lieu d'utiliser les solutions existantes. Ce magasin personnalisé gère et utilise efficacement les fonctionnalités des applications ML.
Une équipe dédiée de Slack a créé une couche d'orchestration sur Kubernetes afin de rationaliser le déploiement des microservices et de les intégrer à des services internes tels que la console. Bien que cela améliore l'utilisation de Kubernetes, des défis subsistent pour les applications qui dépendent fortement des bases de données.
Au début de Slack, des efforts ont été déployés pour développer des mécanismes d'intégration et de faction efficaces. Cela impliquait le traitement de grandes quantités de données pour comprendre les interactions des utilisateurs et générer des intégrations numériques pour les utilisateurs et les canaux. L'un des résultats a été un service d'intégration basé sur les activités des utilisateurs, et un autre basé sur les messages, bien qu'il n'ait pas été largement adopté à l'époque.
Plus tard, l'accent a été mis sur l'utilisation de ces intégrations pour créer un produit plus convivial. Le concept de recommandations est apparu, identifiant les domaines dans lesquels les suggestions pourraient bénéficier aux utilisateurs, tels que la recommandation de chaînes ou d'utilisateurs. Cela a conduit au développement de l'API Recommend, qui s'est intégrée à diverses parties de la plateforme Slack et a utilisé les intégrations existantes pour récupérer les données pertinentes en fonction des activités des utilisateurs. L'API a également intégré le magasin de fonctionnalités, enrichissant les données avec des fonctionnalités supplémentaires et appliquant des mécanismes de filtrage et de notation.
Au fur et à mesure du développement, l'API Recommend a été intégrée à différentes fonctionnalités de Slack, permettant à la plateforme de recommander des chaînes ou des utilisateurs pertinents à ses utilisateurs, de rationaliser leur expérience et de renforcer l'engagement.
Vous pouvez en savoir plus sur SlackGPT dans le blog ci-dessous.
Voici une image du même blog qui donne un très bon aperçu de l'infrastructure d'API recommandée de Slack
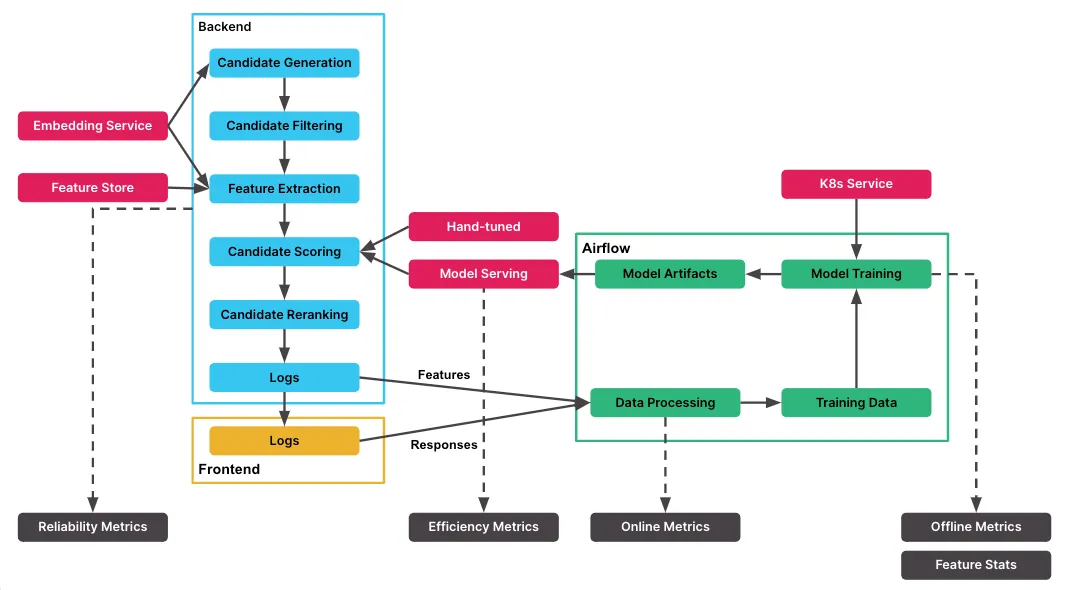
En s'appuyant sur Kubernetes, Airflow et une approche hiérarchique de la formation et de la validation, Slack garantit l'efficacité et la fiabilité des modèles de l'API Recommend, en fournissant des recommandations personnalisées aux utilisateurs. Les tests AB garantissent une évaluation rigoureuse des performances des modèles dans un environnement en ligne avant le déploiement, contribuant ainsi à la mise en place d'un cadre d'opérations de machine learning robuste et piloté par les données chez Slack.
1. Corpus hiérarchique et cas d'utilisation : Le modèle de pipeline de formation de Slack suit une approche hiérarchique. Il commence par un corpus hiérarchique comprenant des chaînes ou des utilisateurs, avec de multiples cas d'utilisation tels que le résumé quotidien, le compositeur ou le navigateur de chaînes, répondant à des fonctionnalités spécifiques de Slack.
2. Sélection et expérimentation du modèle : Pour chaque cas d'utilisation, différents modèles sont entraînés et expérimentés, en commençant par de grands modèles de régression et en explorant d'autres algorithmes tels que XGBoost ou LightGBM. Les paramètres du modèle sont affinés et différentes variations de données sont expérimentées afin d'identifier le modèle le mieux adapté.
3. Pipeline de formation avec Kubernetes et Airflow : Le pipeline de formation est orchestré à l'aide de Kubernetes et Airflow. Les clusters Kubernetes gèrent efficacement les tâches de formation des modèles, Airflow gérant le flux de travail, de la collecte des données à la formation de différents modèles pour différents cas d'utilisation.
4. Métriques de journalisation et hors ligne : Pendant la formation, l'équipe enregistre les mesures hors ligne et les paramètres du modèle pour un suivi et une analyse futurs.
5. Ajout et gestion fluides de modèles : L'architecture permet l'ajout fluide de nouvelles sources ou de nouveaux modèles pour la formation avec un minimum de modifications de code.
6. Validation et tests AB : Une validation rigoureuse est effectuée avant le déploiement des modèles en production, en comparant des indicateurs hors ligne tels que l'AUC pour les modèles de classification ou de classement. Les tests AB sont largement utilisés pour sélectionner des modèles présentant de meilleures statistiques en ligne pour le déploiement.
7. Cadre de test AB interne : Slack dispose de son cadre de test AB interne, utilisé par l'équipe ML et les équipes produit lors du lancement de nouvelles fonctionnalités. Le cadre permet de prendre des décisions fondées sur les données en comparant les performances des modèles sur différents indicateurs commerciaux.
Les modèles de machine learning de Slack sont déployés dans des clusters Kubernetes en utilisant GRPC comme interface de gestion des requêtes. Le GRPC offre sécurité, efficacité et rapidité de traitement par rapport aux API basées sur JSON telles que FastAPI. Malgré ses restrictions, GRPC garantit une communication robuste et efficace entre l'API et les modèles, contribuant ainsi à un processus de déploiement fluide.
La stratégie de déploiement inclut l'exploitation des capacités de mise à l'échelle automatique de Kubernetes, permettant aux modèles d'ajuster l'utilisation des ressources en fonction de la demande. Avec une vaste base d'utilisateurs, Slack gère un nombre important de demandes, avec une moyenne d'environ 100 demandes par seconde.
La mise en œuvre de GRPC et la configuration du microservice du cluster de desserte ont nécessité des efforts ciblés, mais elles se sont révélées efficaces pour gérer l'échelle et optimiser les performances des modèles.
1. Suivi des statistiques hors ligne et en ligne : Le pipeline de surveillance des modèles de Slack permet de suivre efficacement les statistiques hors ligne et en ligne. Les indicateurs hors ligne tels que la précision, la F1 et le ROC sont enregistrés et des tableaux de bord dédiés permettent de les visualiser. Les indicateurs en ligne, y compris le taux d'acceptation, sont également surveillés via un tableau de bord distinct.
2. Détection des anomalies et dérive des caractéristiques : Slack utilise son propre cadre de détection des anomalies pour surveiller la dérive des fonctionnalités. Le recyclage régulier des modèles (entraînement quotidien et déploiements hebdomadaires) réduit l'impact de la dérive des fonctionnalités, ce qui la rend moins préoccupante.
3. Pipeline de recyclage automatisé : Le pipeline de recyclage est automatisé à l'aide d'Airflow, ce qui garantit que les modèles restent à jour avec les données les plus récentes.
4. Tableaux de bord automatisés pour la visualisation : Les ingénieurs de données ont développé des tableaux de bord conviviaux qui visualisent les performances et les mesures des modèles. Les tableaux de bord sont automatiquement mis à jour avec les nouvelles données, ce qui facilite le suivi des nouveaux cas d'utilisation.
5. Intégration facile de nouveaux cas d'utilisation : L'ajout de nouveaux cas d'utilisation au pipeline de surveillance et de reconversion se fait sans effort, grâce au cadre d'intégration automatisé mis en place par les ingénieurs des données.
En tirant parti de l'automatisation et de la formation régulière, les modèles de machine learning de Slack sont surveillés, optimisés et fiables en permanence en production. La structure MLOps robuste contribue à des déploiements de modèles fluides et efficaces pour la large base d'utilisateurs de Slack.
Slack utilise différents indicateurs pour évaluer l'impact commercial de l'API Recommend, afin d'obtenir des informations précieuses sur ses performances et son efficacité. Les indicateurs clés utilisés sont les suivants :
En analysant ces indicateurs et en optimisant l'API de recommandation en fonction des commentaires des utilisateurs, Slack garantit que l'API améliore de manière significative l'expérience utilisateur, favorise les connexions et génère des résultats commerciaux positifs au sein de la plateforme.
L'engagement de Slack en matière de confidentialité des clients influence de manière significative l'architecture de l'infrastructure de formation et les pratiques de traitement des données. L'accent mis sur la confidentialité des données se reflète dans divers aspects de la pile MLOps, qui garantit le traitement sécurisé et conforme des informations sensibles. Voici comment la confidentialité des clients influe sur l'infrastructure de formation de Slack :
Slack a présenté Slack GPT, une puissante IA de génération de langues permettant de synthétiser des informations afin de remédier à la surcharge d'informations sur la plateforme, améliorant ainsi la productivité des utilisateurs.
La création de Slack GPT présentait des défis et nécessitait des innovations en matière d'infrastructure pour la formation de grands modèles linguistiques. Cela impliquait de configurer des clusters, d'utiliser Kubernetes et d'explorer des techniques de traitement parallèle. Pour améliorer la qualité des résumés, l'équipe a mis en œuvre un réglage rapide, en élaborant avec soin des invites pour influencer le comportement du modèle et générer des résumés cohérents.
L'évaluation systématique des invites était cruciale, et l'équipe a développé des outils pour évaluer l'efficacité des prompts, permettant ainsi d'expérimenter différentes invites. En comblant le fossé entre l'évaluation hors ligne et en ligne, la qualité observée lors de l'exploration hors ligne s'est traduite de manière fluide par rapport à l'expérience utilisateur en ligne.
Alors que Slack investit dans les capacités d'IA, les ingénieurs ML jouent un rôle central dans l'optimisation de l'expérience utilisateur grâce à l'exploration, à l'évaluation et à l'amélioration systématique de fonctionnalités pilotées par l'IA, telles que Slack GPT.
Pour en savoir plus sur SlackGPT, cliquez sur le lien ci-dessous.
L'ingénierie rapide est cruciale pour les modèles de langage, car elle a un impact sur la qualité des réponses. Pour l'instant, cela implique des essais et des erreurs, en l'absence d'une approche standardisée. Les possibilités futures incluent :
L'ingénierie rapide est un domaine activement exploré, qui vise à trouver un équilibre entre l'intervention manuelle et l'automatisation, façonnant ainsi l'avenir de la communication alimentée par l'IA.
Il est essentiel pour les data scientists et les ingénieurs ML de se tenir au courant des avancées continues des grands modèles de langage (LLM).
De nombreux professionnels de la communauté de l'IA et de la PNL utilisent Twitter comme une plate-forme précieuse pour accéder à des informations en temps réel sur les nouvelles recherches, les versions de modèles et les avancées dans le domaine du LLM. Suivre des chercheurs et des praticiens influents sur Twitter leur permet de se renseigner rapidement sur les dernières tendances et mises à jour dans le domaine.
De plus, les professionnels restent informés grâce à des interactions avec leurs collègues. Au sein de leurs équipes, des nouvelles importantes, telles que la sortie de LLM comme Llama-2 et son intégration à des plateformes telles que SageMaker, sont partagées, créant ainsi un environnement d'apprentissage collaboratif.
Alors que certains data scientists et ingénieurs ML peuvent se concentrer sur la lecture de documents de recherche, d'autres privilégient les cas d'utilisation pratiques. Ils sont plus enclins à explorer la manière dont les nouveaux développements peuvent avoir un impact direct sur leur travail et à améliorer les applications des LLM dans des scénarios réels.
Continuez à regarder le TrueML série youtube et en lisant tout le TrueML série de blogs.
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


