

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Version courte : Kimi-K2 Thinking (Moonshot AI) est un modèle de « réflexion » ouvert et sensible aux outils qui favorise le raisonnement en plusieurs étapes, l'orchestration d'outils à long terme et des fenêtres contextuelles massives. Sur Humanity's Last Exam (HLE) et plusieurs benchmarks d'agences, il publie les meilleurs chiffres de l'État (en particulier lorsque l'accès aux outils est activé), ce qui montre bien que la prochaine grande frontière en matière de LLM est réflexion + outils + contexte long, et pas seulement le nombre de paramètres bruts.
Utiliser Passerelle Truefoundry AI pour l'essayer dès maintenant.
Les benchmarks tels que MMLU, les tests de codage et les benchmarks de chat nous ont beaucoup appris, mais ils ne mesurent pas complètement le raisonnement en plusieurs étapes, l'orchestration des outils ou la planification à long terme. Une nouvelle classe de modèles de « pensée » entraîne explicitement ces capacités : le modèle doit associer un raisonnement interne étape par étape à des appels d'outils externes (recherche, interpréteurs de code, navigation sur le Web) et maintenir la cohérence pendant de nombreuses étapes séquentielles.
Kimi-K2 Thinking est un exemple phare de cette tendance. Il est conçu comme un système agentique : il raisonne, décide d'appeler des outils, ingère les résultats des outils et continue à raisonner, tout en gardant le contexte sur des centaines d'étapes. Le résultat : des gains substantiels par rapport à des critères de référence « réfléchissants » tels que HLE et BrowseComp.
Principaux points techniques de la carte modèle officielle :
Ces éléments (échelle du MoE, contexte étendu, orchestration d'outils explicite et inférence efficace à faible bit) sont les éléments de base qui permettent à Kimi-K2 d'agir comme un agent plutôt que comme un transformateur conversationnel.
Le dernier examen de l'humanité (HLE) est destiné à être une référence de type examen très difficile qui met l'accent sur le véritable raisonnement, et non sur la recherche ou les raccourcis. Il contient des problèmes complexes, souvent en plusieurs étapes, dans les domaines des mathématiques, des sciences, de l'ingénierie et d'autres matières. Étant donné que les problèmes de HLE nécessitent généralement un raisonnement en plusieurs étapes et, dans certains cas, une recherche externe ou un calcul, il s'agit d'un excellent test de résistance pour les agents à long contexte capables d'utiliser des outils. Le développement de Kimi-K2 a mis l'accent sur le HLE et d'autres critères de référence des agences. La fiche modèle met en évidence le HLE comme l'une de ses principales cibles d'évaluation.
Selon les résultats d'évaluation publiés par Moonshot AI :
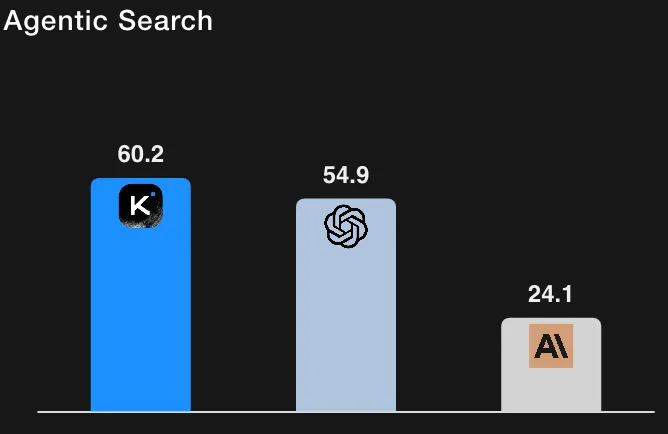
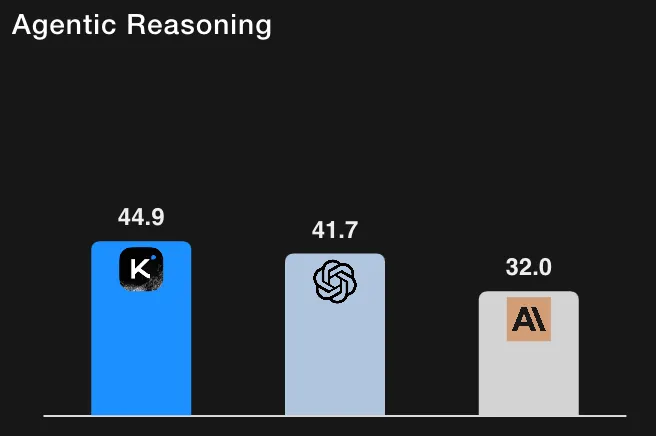
À titre de contexte, GPT-5 (élevé) à ~ 41,7 % sur HLE avec outils (leurs rediffusions internes) et Claude Sonnet 4,5 à ~ 32,0 % (mode réflexion). Les résultats de Kimi-K2 le placent donc en avance sur les niveaux de référence rapportés pour les exécutions HLE activées par des outils. (Tous les chiffres sont tirés du tableau d'évaluation et des notes de bas de page de Moonshot AI.)
Nuance importante : la fiche modèle documente soigneusement la manière dont l'accès aux outils, les paramètres des juges, les budgets symboliques et les limites de contexte ont été gérés ; les auteurs notent également que certains chiffres de référence ont été extraits de publications officielles tandis que d'autres ont été retestés en interne. En bref : ce sont des signaux forts, mais les lecteurs doivent noter qu'ils sont signalés par Moonshot AI et conditionnés au protocole d'évaluation détaillé décrit avec les résultats.
Nous avons échantillonné 50 lignes de données à partir de HLE et voici les résultats
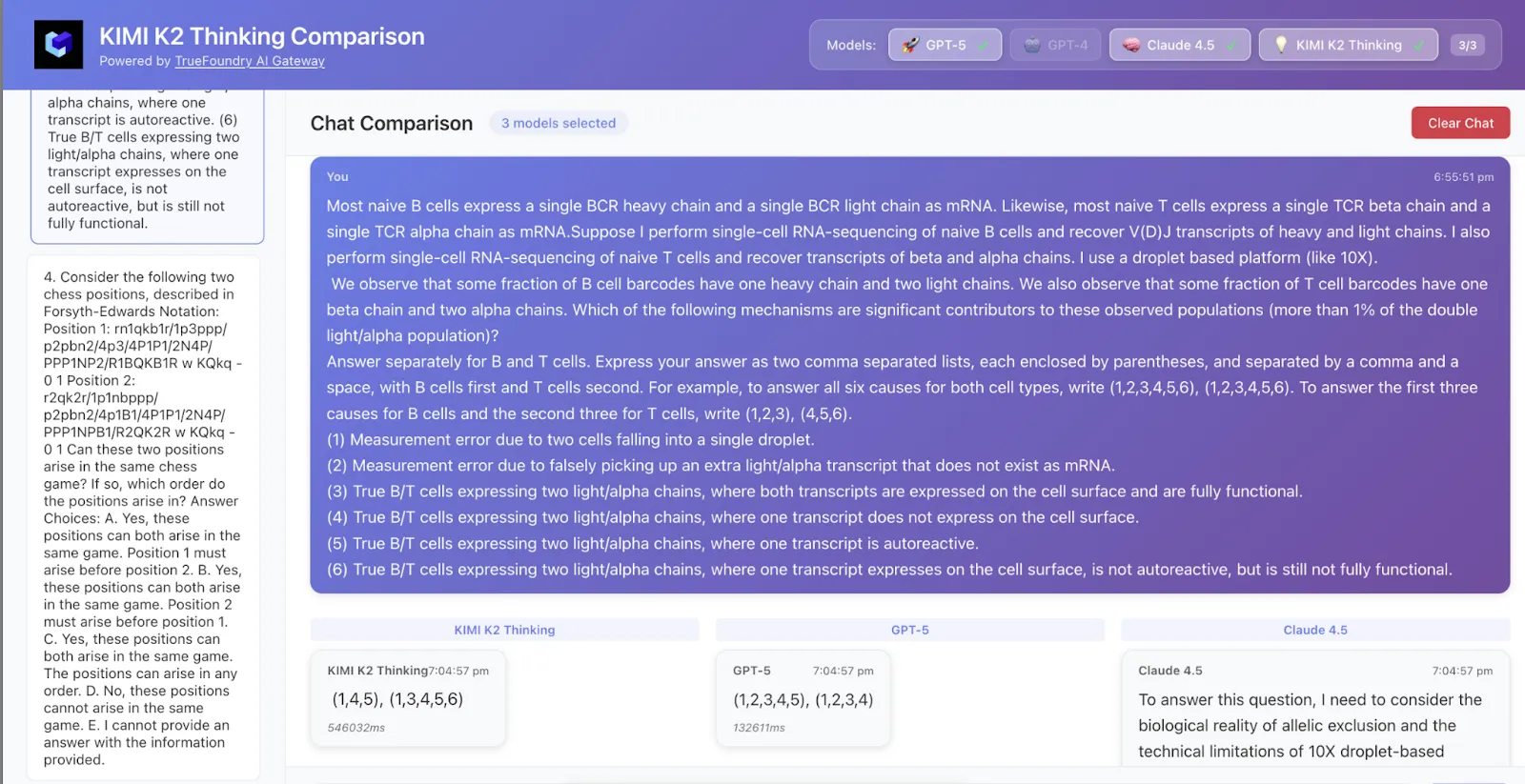
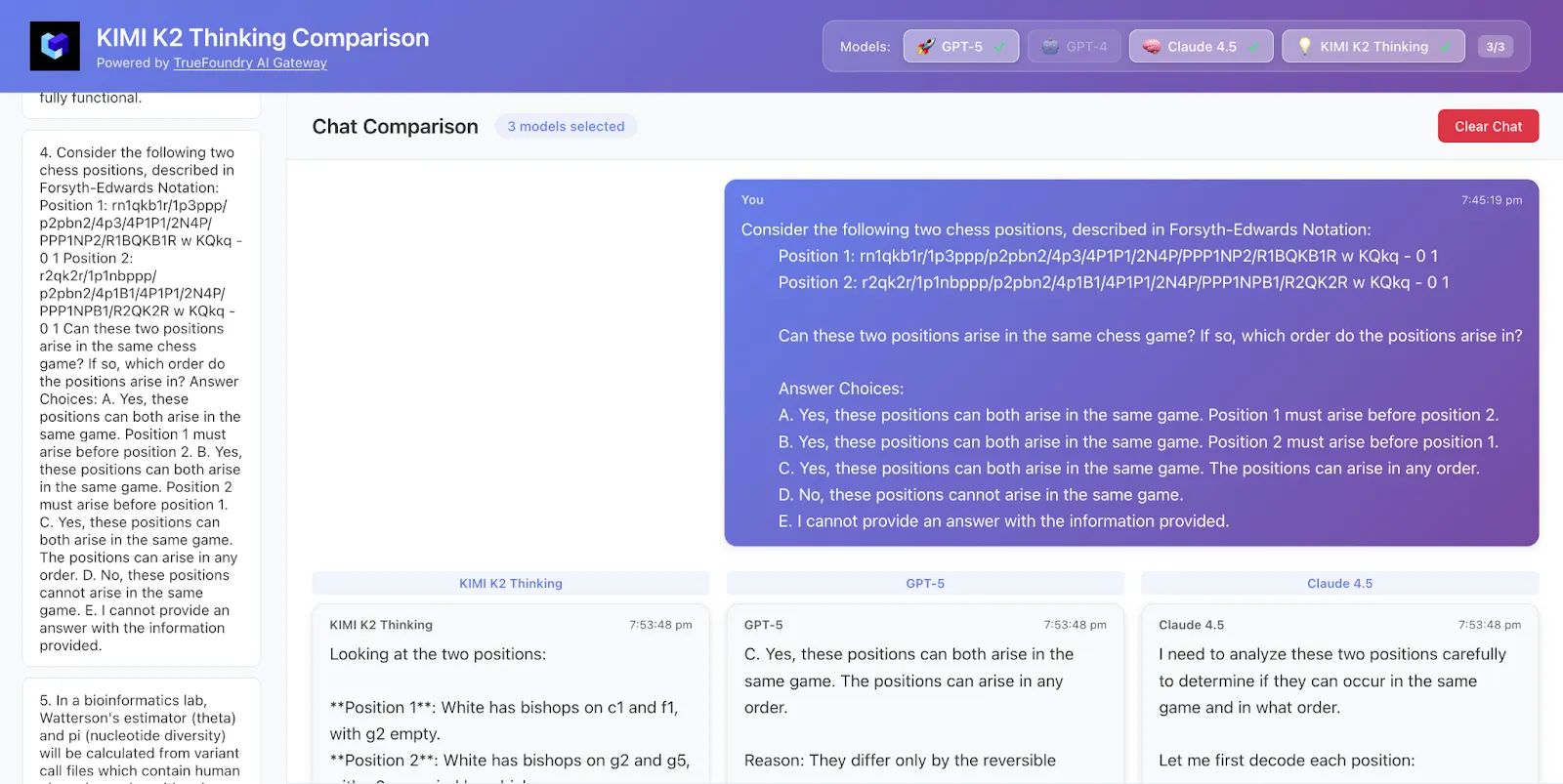
Kimi K2 a obtenu à la fois la bonne réponse et la logique, tandis que GPT-5 n'a obtenu que la bonne réponse et Claude n'avait pas raison.
Kimi-K2 c'est à peu près doubler des performances HLE entre « no-tools » et « with-tools » (≈ 24 % → 45 %) démontrent un point crucial :
En termes simples : les gains du HLE suggèrent que le problème central est comment un modèle raisonne et utilise des outils, pas seulement la taille brute du modèle.
Au-delà des points de référence, ce qui est le plus intéressant, c'est de constater à quel point ce type de capacité devient accessible. Vous n'avez pas à attendre des mois pour expérimenter — vous pouvez l'essayer vous-même. Passerelle TrueFoundry AI permet d'accéder directement à Kimi-K2 Thinking et à d'autres modèles de pointe, de les comparer à vos propres données ou de les intégrer dans des flux de travail.
Si vous souhaitez une aide plus personnalisée, réservez une démo — l'équipe peut vous expliquer les performances, les options de déploiement, les coûts et la manière d'évaluer ces modèles dans le cadre de vos tâches. Nous nous tenons au courant de l'évolution du marché et veillons à ce que de nouveaux modèles soient disponibles pour votre consommation le plus rapidement possible.
Conclusion : Kimi-K2 Thinking n'est pas un simple LLM comme les autres, c'est un aperçu visible de l'avenir des agents capables de raisonner : ouverts, efficaces, sensibles aux outils et adaptés à la résolution de problèmes en plusieurs étapes. Essayez-le, comparez-le en fonction de vos propres problèmes et découvrez à quel point l'orchestration des outils agentiques peut faire une différence sur des tâches réelles.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


