

August 27, 2025
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Le paysage de l'infrastructure de machine learning regorge de solutions parmi les plus impressionnantes disponibles pour simplifier le pipeline de machine learning. TrueFoundry peut être une solution si vous rencontrez certains des problèmes mentionnés ci-dessous :
La principale raison que nous avons constatée concernant les retards dans les délais est la dépendance entre les équipes et le manque de compétences avec des personnes différentes. TrueFoundry permet aux data scientists de se former et de déployer facilement sur Kubernetes à l'aide de Python. Il permet également aux équipes d'infrastructure de définir des contraintes de sécurité et des budgets de coûts. Dans la plupart des entreprises à qui nous avons parlé, le flux de mise en œuvre se présente comme suit :
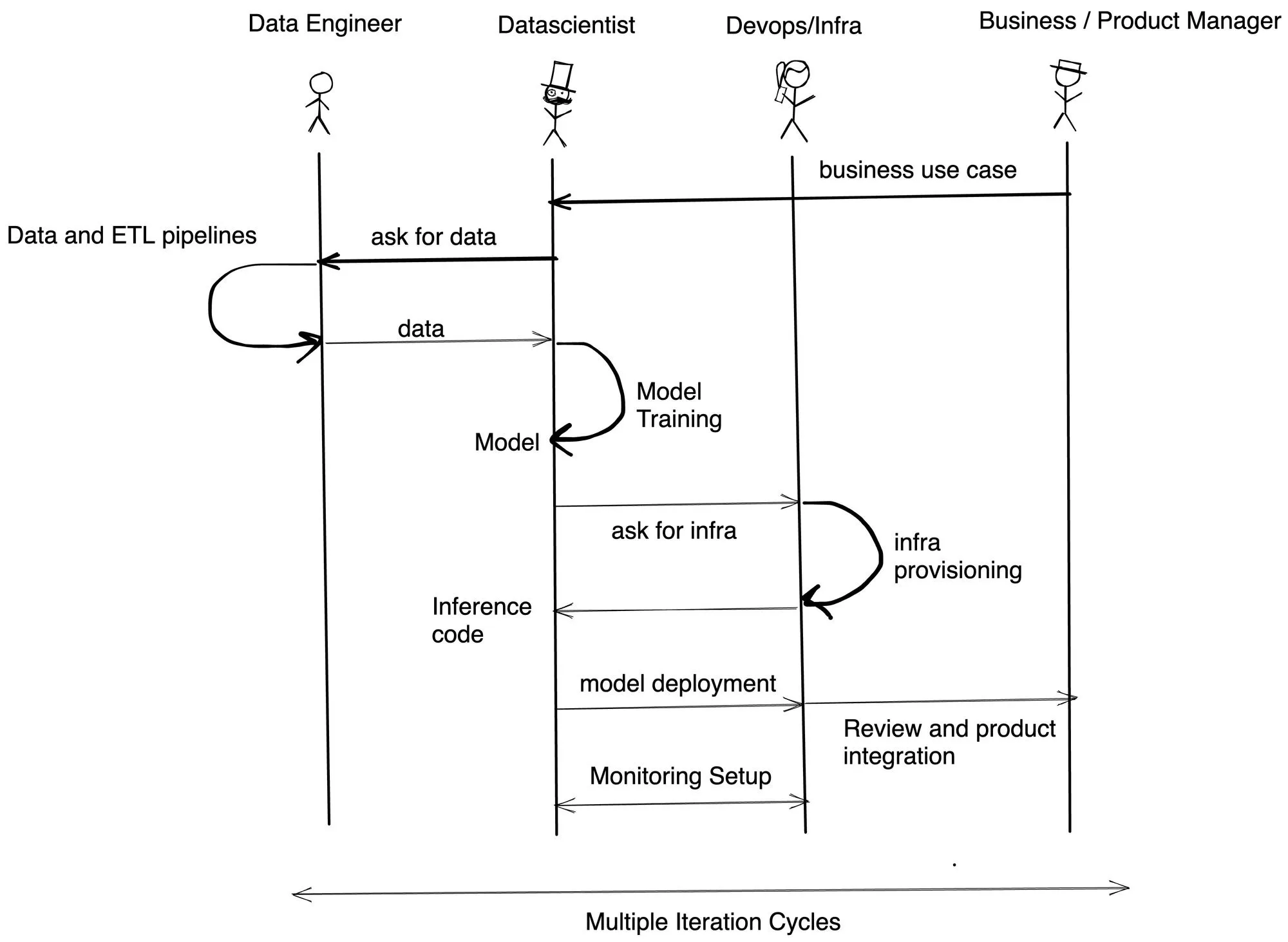
TrueFoundry vous aide à réduire le temps de développement d'au moins 3 à 4 fois en permettant aux data scientists de déployer et d'évaluer le modèle eux-mêmes sans avoir à faire appel à l'équipe Infra/DevOps.
Avec TrueFoundry, le flux est similaire à celui ci-dessous :
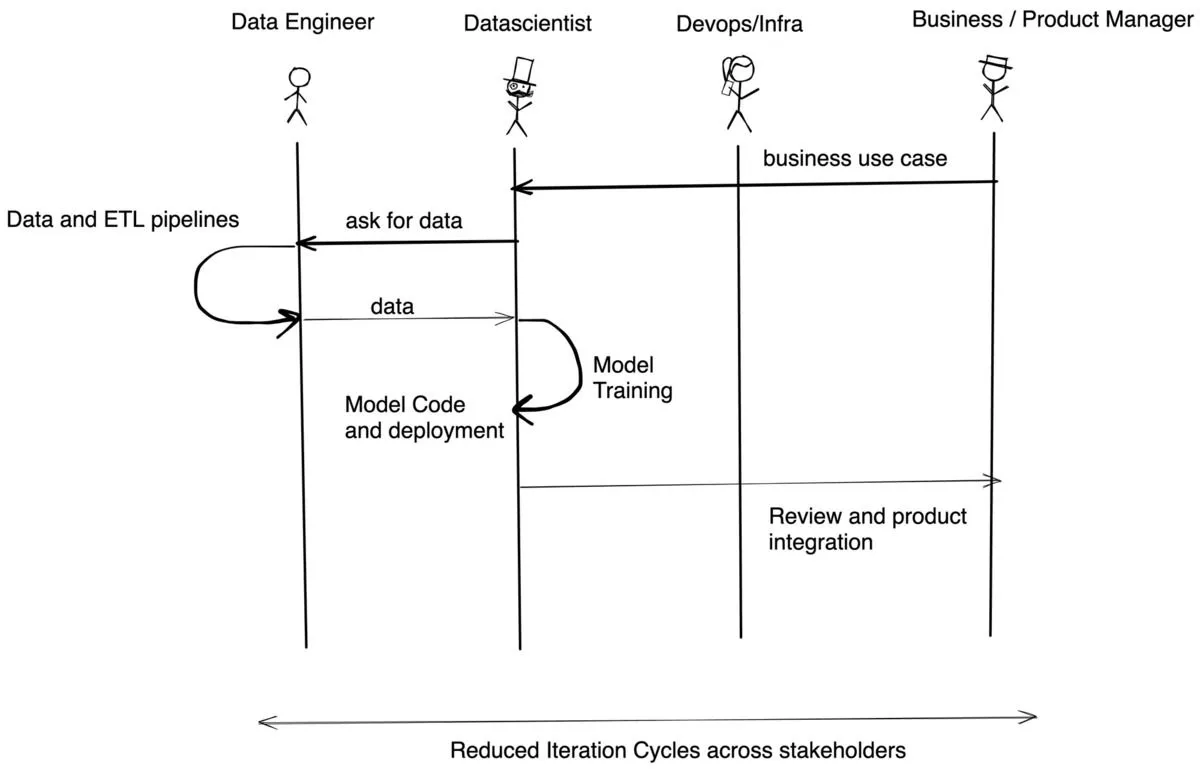
TrueFoundry est natif de Kubernetes et fonctionne sur EKS, AKS, GKE (clusters standard et pilotes automatiques) ou sur site. Le ML nécessite quelques éléments personnalisés par rapport à l'infrastructure logicielle standard, tels que le provisionnement dynamique des nœuds, la prise en charge du GPU, les volumes pour un accès plus rapide, la budgétisation des coûts et l'autonomie des développeurs. Nous nous occupons de tous les détails des clusters afin que vous puissiez vous concentrer sur la création des meilleures applications sur une infrastructure de pointe.
Nous fournissons des API Python. Vous n'avez donc jamais besoin d'interagir avec YAML. Nous fournissons également un support YAML si vous souhaitez l'utiliser dans vos pipelines CI/CD. Par exemple, en utilisant TrueFoundry, vous pouvez déployer une API d'inférence en utilisant le code ci-dessous :
service = Service (
nom = « fastapi »,
image=Construire (
build_spec=PythonBuild (
command="application uvicorn : app --port 8000 --host 0.0.0.0",
requirements_path= » requirements.txt «,
)
),
ports= [
Port (
port = 8000
<Provide a host value based on your configured domain>hôte= » »
)
],
Resources=Ressources (
requête_processeur = 0,5,
limite du processeur = 1
demande_mémoire=1000,
limite_mémoire = 1500
),
env= {
« UVICORN_WEB_CONCURRENCY » : « 1 »,
« ENVIRONNEMENT » : « dev »
}
)
service.deploy (workspace_fqn="tfy-cluster/mon-espace de travail »)
TrueFoundry est entièrement déployé sur votre propre cluster Kubernetes. Les données restent dans votre propre VPC, les images Docker sont enregistrées dans votre propre registre Docker et tous les modèles restent dans votre propre système de stockage blob. Vous pouvez en savoir plus sur l'architecture TrueFoundry ici.
Kubernetes prend généralement en charge la mise à l'échelle automatique à l'aide de HPA en fonction du processeur et de la mémoire. Cependant, pour les charges de travail de machine learning, la mise à l'échelle automatique en fonction du nombre de demandes est bien meilleure dans de nombreux cas. Un autre défi en matière de mise à l'échelle automatique peut être le temps de démarrage élevé des modèles en raison de la grande taille des images et des temps de téléchargement des modèles. Truefoundry résout ces problèmes en fournissant un temps de démarrage des conteneurs en quelques secondes, en mettant en cache les modèles pour un chargement plus rapide et en fournissant des temps d'inférence plus rapides.
Pouvons-nous utiliser certains modèles LLM open source ?
TrueFoundry vous permet de déployer et de peaufiner les LLM open source sur votre propre infrastructure. Nous avons déjà défini les meilleurs paramètres pour les modèles open source les plus courants afin que vous puissiez les former et les déployer avec les paramètres optimaux et les coûts les plus bas.
Nous hébergeons un terrain de jeu interne sur lequel vous pouvez choisir les LLM que vous souhaitez ajouter à la liste blanche pour les développeurs de l'entreprise, y compris ceux hébergés en interne, et différents développeurs peuvent expérimenter avec les données internes. Voici une courte vidéo à ce sujet :
Les blocs-notes Jupyter sont essentiels au cycle de développement quotidien du Data Scientist. Exécuter Jupyter Notebooks localement sur sa propre machine n'est pas toujours une option pour les raisons suivantes :
Nous avons déployé de nombreux efforts pour exécuter de manière fluide Jupyter Notebooks sur Kubernetes. Les blocs-notes Jupyter sur TrueFoundry offrent les avantages suivants par rapport aux blocs-notes JupyterLab ou Kubeflow :
TrueFoundry fournit un registre de modèles qui permet de suivre quels modèles se trouvent à quel stade, ainsi que le schéma et l'API de tous les modèles du registre.
TrueFoundry permet de fractionner ou de mettre en miroir le trafic d'un modèle à l'autre. Cela est particulièrement utile lorsque vous souhaitez tester une nouvelle version d'un modèle sur le trafic réel pendant un certain temps avant de la mettre en production. Truefoundry prend également en charge les stratégies de déploiement Canary et Blue-Green lors du déploiement de modèles.
Nous avons déployé de nombreux efforts pour nous assurer de prendre en compte les différences fondamentales entre les clusters Kubernetes d'un cloud à l'autre. Les développeurs peuvent écrire et déployer le même code dans n'importe quel environnement sans se soucier de l'infrastructure sous-jacente. Nous nous chargeons de vérifier si les composants sous-jacents de Kubernetes sont installés, de vérifier les migrations incompatibles et d'informer les développeurs en conséquence.
Nous exposons la visibilité des coûts des services aux développeurs et fournissons des informations pour réduire les coûts. Tous nos clients actuels ont constaté une réduction de leurs coûts d'au moins 30 % après avoir adopté Truefoundry.
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes conçu pour simplifier Déploiement de modèles d'IA, accélérez les flux de travail des développeurs et maintenez le contrôle total de l'infrastructure. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception





.png)

.webp)
.webp)
.webp)



.webp)
.webp)


