

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Créer un modèle pour résoudre un cas d'utilisation commercial semble être une excellente idée pour nous tous. Il semble évident que si nous pouvons augmenter l'engagement de 5 % grâce à la personnalisation d'un site Web en utilisant le machine learning, cela augmentera les revenus d'un certain pourcentage.
Cependant, ce qui est souvent négligé, ce sont deux facteurs qui peuvent mettre en péril ce projet :
Eh bien, ne devrait-il pas être simple de tester les 2 choses ? Voyons en détail ce qu'il faut faire pour passer de l'idée de créer un modèle à sa mise en production et à l'évaluation de son impact commercial. Prenons le cas où, dans une application de livraison de nourriture, vous souhaitez afficher l'heure de livraison prévue une fois qu'un client passe une commande sur l'application. Comme nous ne connaissons pas le délai de livraison à l'avance, nous devrons créer un modèle ML capable de faire des prévisions en fonction de certains facteurs tels que la ville, le restaurant, l'heure de la journée, la distance entre le client et le restaurant, etc.
Afficher le délai de livraison estimé à l'utilisateur pour une application de livraison de nourriture
Le flux de travail pour la sortie de ce modèle impliquera les équipes suivantes :
Le chef de produit proposera le projet pour estimer le délai de livraison. On s'attend à ce que si le délai de livraison est suffisamment précis, il offrira une meilleure expérience aux utilisateurs. Les clients poseront moins de questions concernant les délais de livraison et le score global de satisfaction des clients devrait augmenter. L'équipe commerciale demandera ensuite à l'équipe de science des données de proposer ce modèle.
Les data scientists commencent à collecter les données historiques de toutes les commandes passées et de leurs délais de livraison.
Le data scientist va ensuite analyser les données pour voir si tout semble correct - pas de valeurs nulles ou fausses et si toutes les données requises sont présentes. La plupart du temps, le DS détectera quelques bogues dans l'ensemble de données, ou peut-être qu'il y a quelques jours de mauvaises données en raison de bogues transitoires. Nous devrons éliminer les fausses données, car nous sommes les seuls à pouvoir construire un bon modèle. Cela peut entraîner quelques itérations avec l'équipe d'ingénierie des produits et des données.
Une fois que les données sont correctes, dans certains cas, les data scientists souhaiteront disposer d'un pipeline pour calculer les caractéristiques et les stocker afin qu'il n'y ait pas de biais au service de l'entraînement et qu'il soit plus facile d'obtenir les valeurs des caractéristiques lors de l'inférence.
Il s'agit toutefois d'une étape facultative qui est ignorée lorsque les données ou le nombre de modèles créés sur le même jeu de données sont faibles. Au cas où une équipe déciderait de faire de l'ingénierie des fonctionnalités, nous aurons besoin d'un système d'orchestration de pipeline comme Airflow, Prefect et d'une base de données/cache pour stocker les fonctionnalités à récupérer (par exemple, Feast). La construction d'un magasin spécialisé est en soi une entreprise de grande envergure qui nécessite des efforts importants.
Une fois les données prêtes, le data scientist va maintenant expérimenter différents algorithmes, fonctionnalités et modèles pour déterminer lequel fonctionne le mieux. Ils voudraient enregistrer toutes les métriques, paramètres et modèles afin de pouvoir s'y référer ultérieurement ou les partager avec d'autres membres de l'équipe. C'est là qu'un suivi des expériences et un magasin de métadonnées de modèles entrent en jeu..
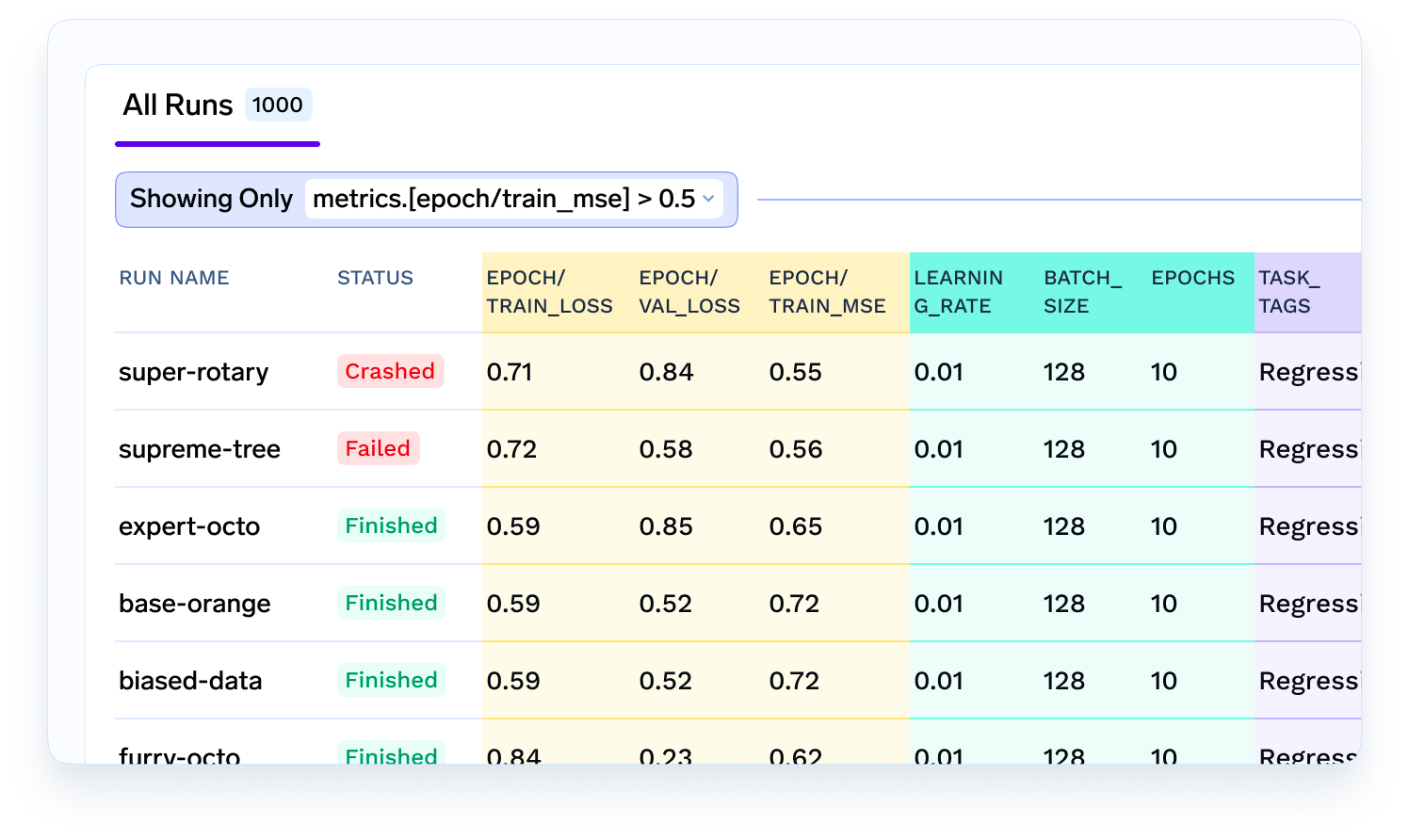
Une fois le modèle créé, il doit être hébergé en tant que microservice ou en tant que tâche d'inférence par lots. Dans notre cas de prévision des délais de livraison, il doit s'agir d'un service en ligne en temps réel. Il est donc probablement judicieux de le déployer en tant que service de dimensionnement automatique. Dans ce cas, un ingénieur ML intervient pour déterminer qui prend le modèle, l'enveloppe dans un service Flask ou FastAPI et crée l'image Docker. Ensuite, l'ingénieur ML, avec l'aide de l'équipe Devops, le déploiera en tant que microservice sur l'infrastructure.
Une fois l'API du modèle hébergée, l'équipe chargée du produit ou du backend devra appeler l'API dans son code pour utiliser le délai de livraison prévu et l'afficher sur l'application. Cela nécessitera une collaboration entre les équipes de data scientist, d'ingénierie des produits et de ML Engineering. Pendant ce temps, le chef de produit voudra peut-être tester les prévisions et ce serait formidable s'il pouvait tester rapidement le modèle sur certains échantillons d'entrées. Cela peut nécessiter une démonstration rapide du modèle pour être construit.
Une fois le modèle déployé et utilisé dans le produit, nous aurons besoin de métriques sur le modèle déployé.
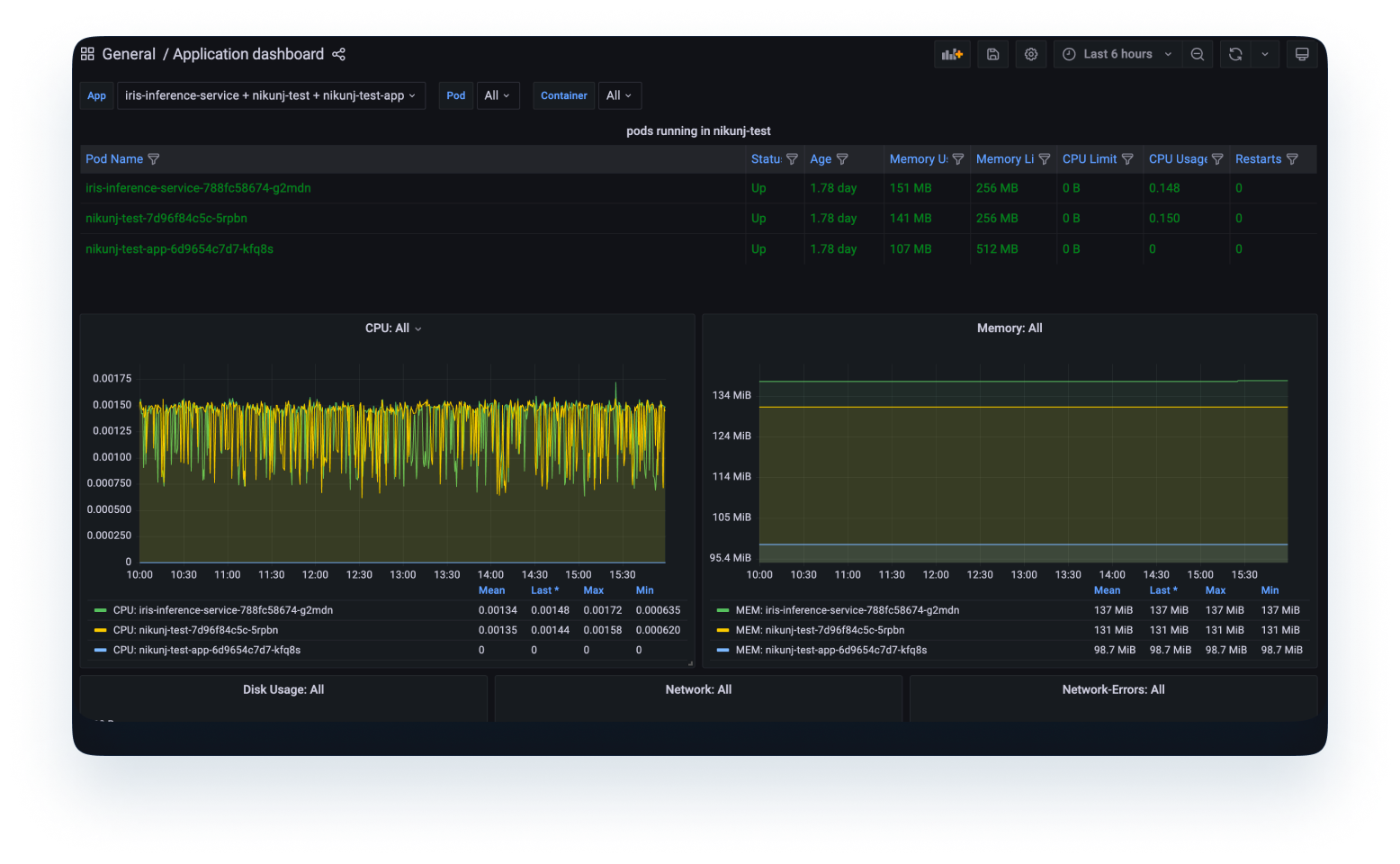
2. Surveillance du modèle : Cela inclut les métriques liées à la prédiction du modèle sur les données de production entrantes. Il s'agit de données qui intéresseront principalement le data scientist et qui incluent des paramètres tels que la précision du modèle, la dérive des caractéristiques, la dérive des prévisions, etc. Cela permet au data scientist de décider si le modèle se comporte de la même manière que lors de la formation, si les distributions des données d'entrée externes n'ont pas changé et s'il n'y a aucun bogue ailleurs dans le système.

Pour assurer une surveillance complète du modèle, des efforts importants seront nécessaires de la part des équipes Datascience, Engineering et Devops.
Une fois que toute la surveillance aura été triée, le data cientist souhaitera idéalement automatiser l'ensemble de la boucle de reconversion. Cela nécessitera un framework d'orchestration des pipelines tel que Kubeflow ou Airflow.
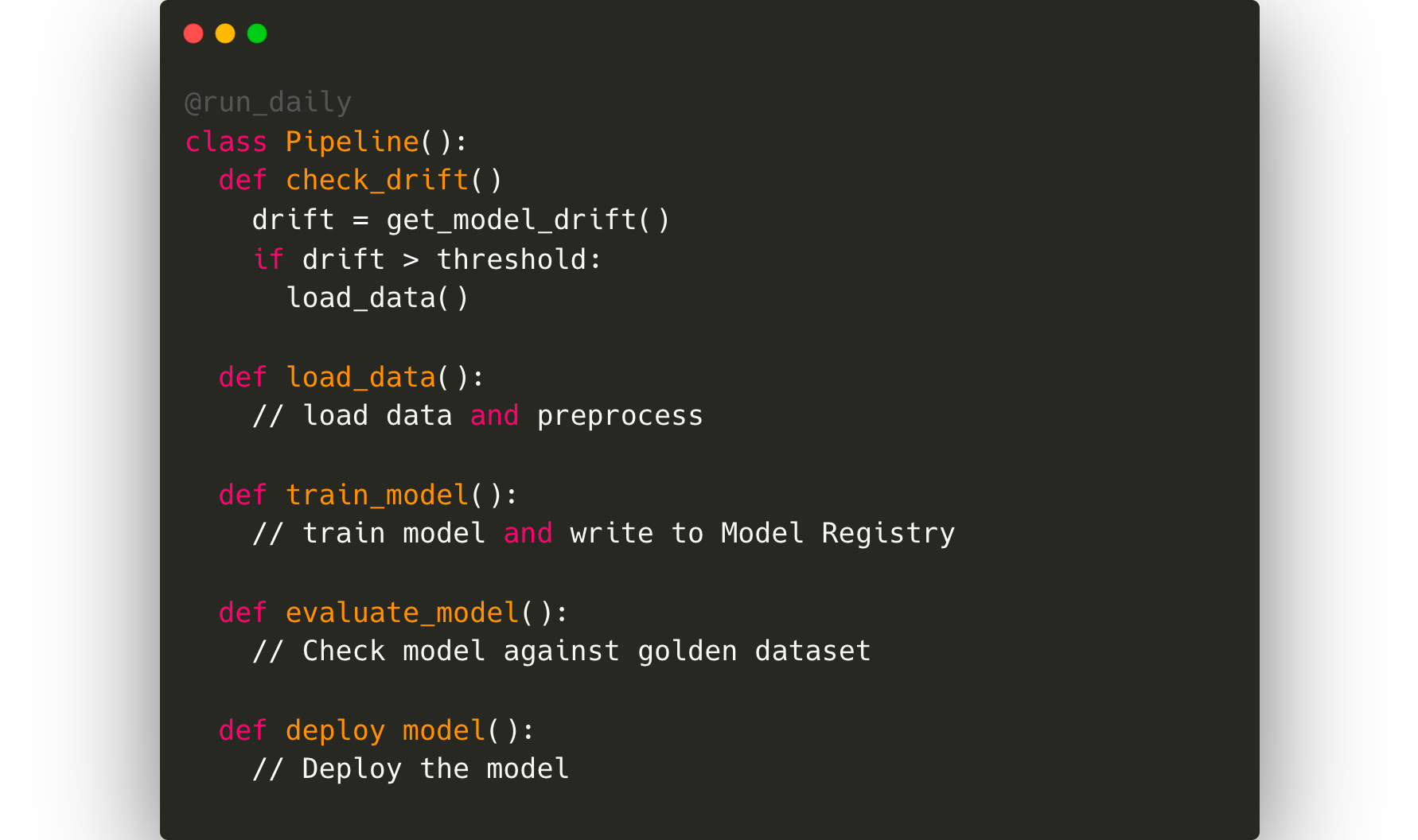
Nous devons ensuite également estimer l'impact de ce modèle sur les indicateurs de satisfaction réels des utilisateurs. Dans ce cas, quelques indicateurs indirects seront le nombre de requêtes des clients liées aux délais de livraison, le score de satisfaction global des clients pour une commande. Les mesures commerciales devront être associées aux mesures du modèle et l'équipe d'ingénierie des données écrira probablement un pipeline ETL pour obtenir ces données et les tracer sur un outil de tableau de bord interne que les chefs d'entreprise pourront observer.
En résumé, cela implique 5 parties prenantes :

L'ensemble du processus prend facilement plus de 2 à 3 mois dans n'importe quelle entreprise et peut parfois aller jusqu'à 6 mois pour les premiers modèles. C'est en raison des multiples parties prenantes impliquées et des multiples compétences impliquées que rendre le ML efficace demande beaucoup de temps et un investissement initial initial.
Nous n'avons pas encore parlé de certains aspects liés à l'évolutivité et à la fiabilité du processus. Nous espérons aborder certains des aspects ci-dessous dans un prochain article.
La solution consiste ici à automatiser les parties qui peuvent être automatisées et à donner l'autonomie au data scientist/ingénieur ML pour effectuer la plupart des étapes sans avoir à apprendre tous les outils nécessaires. Beaucoup de travail est en cours dans ce domaine et j'espère que dans quelques années, créer un modèle de machine learning percutant deviendra aussi simple que la création d'une page de destination aujourd'hui !
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


