

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 23, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les blocs-notes Jupyter sont un outil puissant et populaire qui fournit un environnement informatique interactif, combinant code, visualisation des données et texte explicatif, facilitant ainsi le travail avec les données et le partage d'informations. Les data scientists utilisent les blocs-notes Jupyter pour diverses tâches tout au long du cycle de vie de l'analyse des données et de l'apprentissage automatique, telles que l'analyse exploratoire des données (EDA), le prétraitement des données, la visualisation, le développement de modèles, l'évaluation et la validation, etc. Pour la plupart de ces cas d'utilisation, il suffit installation de Jupyter Notebook sur votre ordinateur portable suffit pour commencer. Cependant, pour de nombreuses entreprises et organisations, ce n'est pas une option et nous avons besoin de blocs-notes Jupyter hébergés.
Voici les options dont dispose une entreprise aujourd'hui pour donner accès à Jupyter Notebook à ses ingénieurs :
Les DS/MLES peuvent configurer l'environnement et exécuter un serveur jupyter sur une machine virtuelle qui peut être utilisé pour exécuter les charges de travail. Voici un guide simple sur la façon dont vous pouvez exécutez jupyterlab sur une instance ec2.
👍 Avantages :
- Donne le contrôle total de la machine entre les mains d'une DS
- L'ensemble de l'environnement est persistant. La machine virtuelle peut être arrêtée et redémarrée dans le même état.
👎 Inconvénients :
- Coût élevé du cloud computing - Il n'y aura pas de fonction d'arrêt automatique. DS peut démarrer une machine virtuelle et rester inutilisée pendant une grande partie du temps, ce qui augmente les coûts.
- Difficile de gérer et de suivre un grand nombre de machines virtuelles de manière centralisée.
- DS doit configurer de nombreux éléments pour configurer le plan de travail permettant de démarrer l'expérimentation.
- Difficulté de reproductibilité - DS a peut-être installé un tas de packages qui ne sont plus suivis et la production du code qui s'exécute sur cette machine virtuelle prend beaucoup de temps.
Une autre option consiste à utiliser une solution gérée telle qu'AWS Sagemaker, Vertex AI Notebooks ou Azure ML Notebooks. Bien que chacune de ces méthodes présente des avantages, voici quelques avantages et inconvénients en général.
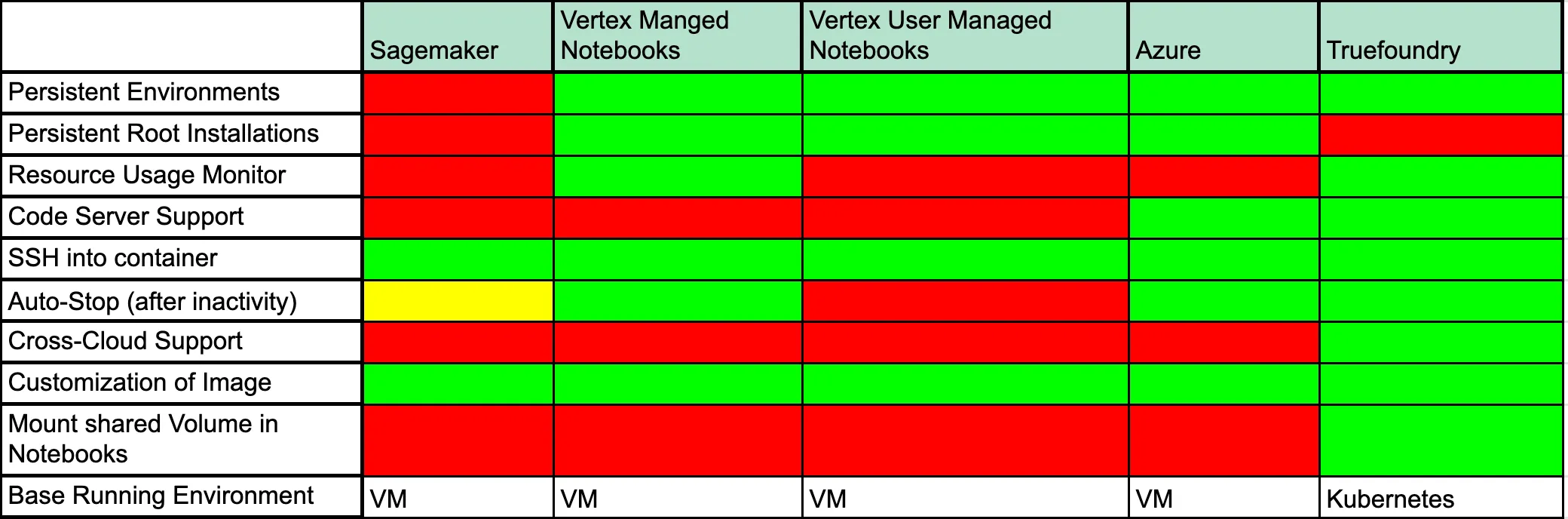
Discutons de la signification de chacun de ces champs :
Une autre option consiste à héberger des blocs-notes sur Kubernetes, mais elle comporte ses propres défis, car les data scientists ne peuvent pas interagir directement avec Kubernetes et ont besoin d'un logiciel intermédiaire fournissant une interface simple pour lancer les blocs-notes Jupyter. Voyons quelles sont les options disponibles dans ce domaine :
Opérateur de bloc-notes Kubeflow :
Kubeflow contribue à rendre les déploiements de flux de travail d'apprentissage automatique (ML) sur Kubernetes simples, portables et évolutifs. Il dispose d'un ordinateur portable fonctionnalité qui permet de gérer et d'exécuter facilement les blocs-notes.
Bien que Kubeflow soit un grand projet open source qui fournit de nombreuses fonctionnalités pour les cas d'utilisation de l'apprentissage automatique, il est très difficile d'installer et de gérer Kubeflow par vous-même.
👍 Avantages :
- Des ordinateurs portables pour DS faciles à lancer et à gérer
- Répertoire personnel persistant sauvegardé par un disque
- Option pour des images prédéfinies pour sklearn, pytorch et tensorflow, fournie avec toutes les dépendances installées.
- Base de code open source
- Bénéficiez d'une fonction d'élimination qui arrête les blocs-notes après un certain temps d'inactivité.
👎 Inconvénients :
- Difficile de configurer Kubeflow sur Kubernetes. L'installation et la maintenance de Kubeflow prennent beaucoup de temps
- Pour fournir des blocs-notes dans plusieurs régions, différents clusters Kubernetes doivent être créés et Kubeflow doit être installé sur chaque cluster - ce qui entraîne des coûts d'infrastructure et de maintenance élevés.
- Les packages Python ne sont pas persistants par défaut, ce qui signifie que vous devez installer des packages à chaque redémarrage
- Aucun moyen direct d'obtenir un accès root vers le conteneur [peut être utile pour plusieurs cas d'utilisation]
- L'arrêt des blocs-notes ne peut pas être configuré au niveau de chaque bloc-notes et constitue un cadre mondial.
Hébergez JupyterHub sur Kubernetes :
JupyterHub est une excellente configuration pour les cas d'utilisation multi-utilisateurs, ce qui permet une utilisation optimale des ressources. Le déploiement de JupyterHub sur Kubernetes peut être effectué à l'aide d'un projet open source appelé De zéro à JupyterHub avec Kubernetes :
👍 Avantages :
- Plusieurs utilisateurs peuvent facilement travailler ensemble grâce à la prise en charge de l'authentification
- Configurez facilement l'arrêt automatique pour les ordinateurs portables
- Gestion facile des environnements
👎 Inconvénients :
- Difficile à configurer et à gérer. Nous devons configurer la mise en réseau, les volumes persistants, la mise à l'échelle et l'équilibrage de charge pour que JupyterHub fonctionne correctement.
- Difficile d'exécuter des charges de travail GPU sur différents types de GPU sur Jupyterhub. Par exemple, lisez ce.
- Les environnements ne sont pas persistants
Bien qu'il existe actuellement de nombreuses solutions, chaque solution comporte ses propres limites. Chez Truefoundry, nous avons essayé de combler cette lacune et avons essayé de créer une solution pour ordinateurs portables qui réponde à tous les besoins d'une DS tout en maîtrisant les coûts. Dans la section suivante, nous décrirons notre approche pour créer la solution pour ordinateurs portables et les défis auxquels nous avons été confrontés pour la créer.
Véritable fonderie est une plateforme de développement pour les équipes de machine learning qui permet de déployer des modèles, des services, des jobs et maintenant des blocs-notes sur Kubernetes. Vous pouvez en savoir plus sur ce que nous faisons ici. Notre motivation pour créer une solution pour ordinateurs portables était simplement de permettre l'expérimentation et le développement sur notre plateforme. Après avoir étudié toutes les solutions disponibles, nous avons décidé de résoudre les problèmes et les fonctionnalités manquantes des autres plateformes afin que les data scientists puissent bénéficier de la meilleure expérience possible sans encourir de coûts importants. Voici quelques-unes des choses que nous voulions activer :
Kubeflow prend en charge l'exécution de blocs-notes sur Kubernetes. Il fournit un certain nombre de fonctionnalités prêtes à l'emploi sur les ordinateurs portables. Cependant, nous voulions résoudre les problèmes que nous avons soulignés ci-dessus dans Kubeflow Notebooks et offrir une expérience fluide aux data cientists et aux développeurs.
Nous avons donc dû apporter des modifications au contrôleur de l'ordinateur portable, l'intégrer au backend de Truefoundry et faire apparaître les blocs-notes sur notre interface utilisateur.
Nous avons installé le contrôleur de bloc-notes mais nous avons rencontré quelques problèmes, à cause desquels nous avons dû apporter des modifications au contrôleur kubeflow-notebook-controller :
Nous avons résolu les deux problèmes ci-dessus et lancé le contrôleur pour ordinateur portable TFY
et l'a publié en tant que référentiel public de cartes Truefoundry sous forme de helm-chart. Vous pouvez trouver le tableau ici.
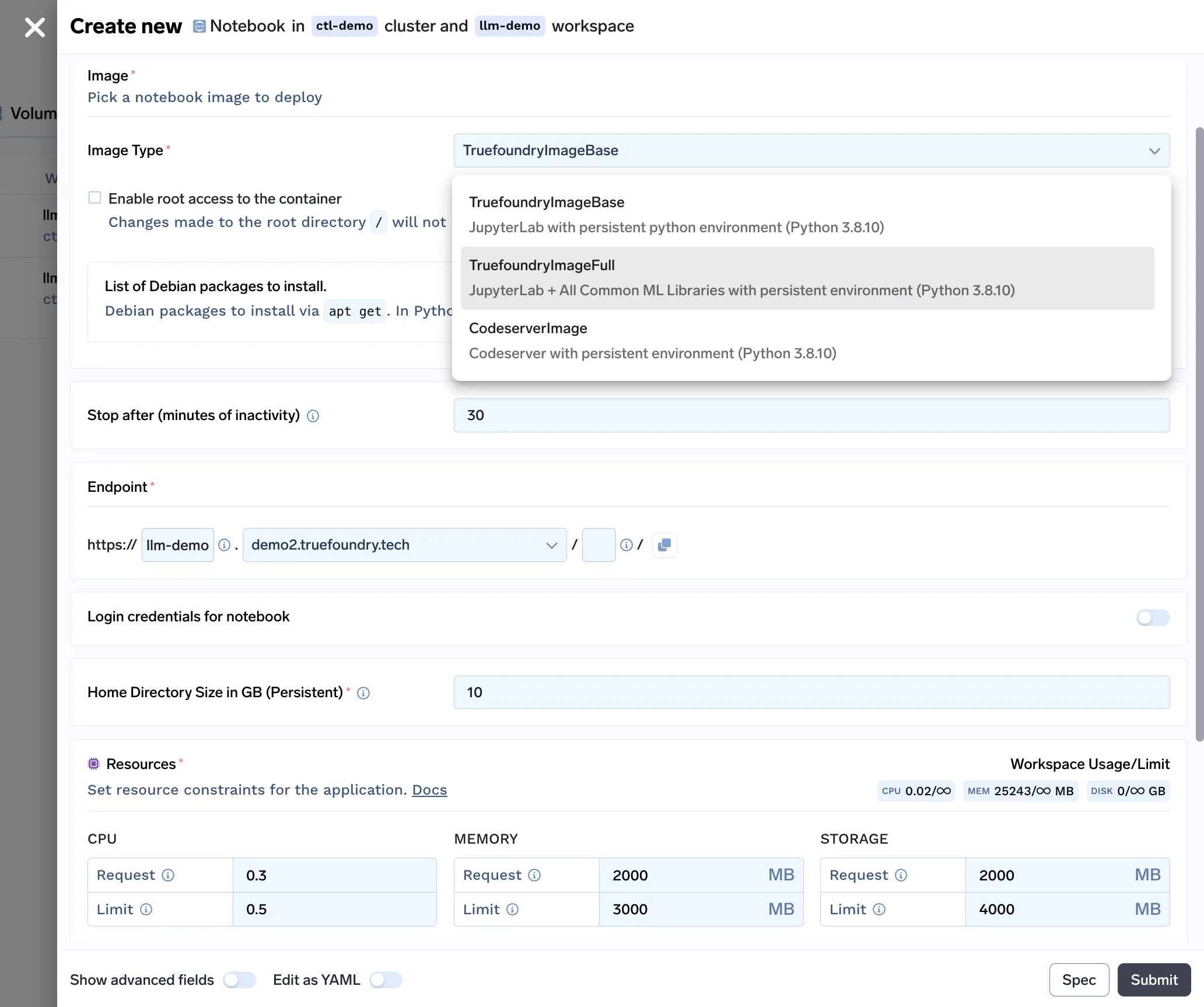
Nous avons créé une interface utilisateur facile à comprendre pour permettre aux data scientists de démarrer des blocs-notes. L'utilisateur peut personnaliser le délai d'inactivité (durée d'inactivité après laquelle le bloc-notes sera arrêté), la taille du volume persistant (taille du disque qui stocke l'ensemble de données et les fichiers de code), les ressources (exigences en matière de processeur, de mémoire et de GPU) et faire tourner le bloc-notes !
Avec tous ces changements, nous avons lancé le v0 de nos carnets.
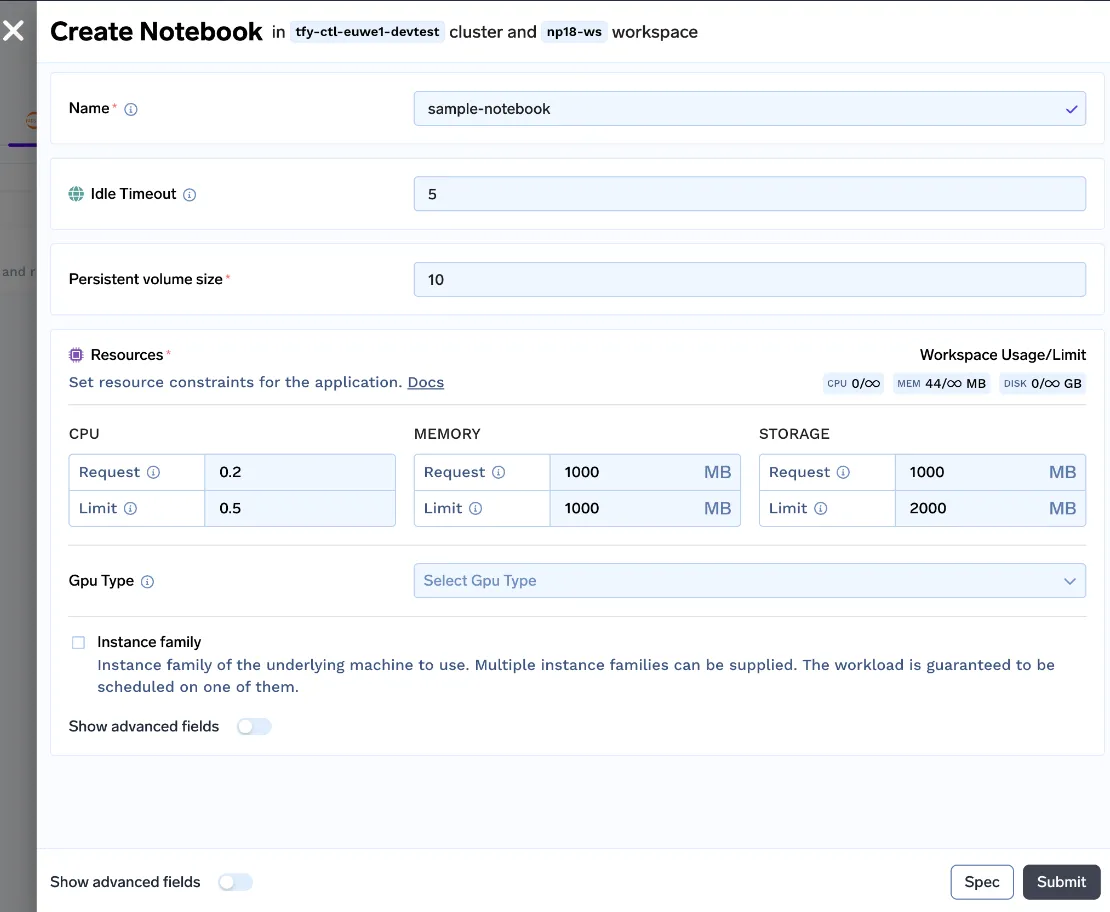
Mais nous sommes encore loin d'une bonne expérience utilisateur, voyons les avantages et les inconvénients de cette approche :
👍 Avantages :
- Répertoire personnel persistant [tous les fichiers et packages seront conservés]
- Le délai d'inactivité (Cull Timeout) par ordinateur portable peut être configuré
- Lancez le bloc-notes en quelques clics
- Lancez facilement un ordinateur portable avec des GPU
👎 Limites :
- L'environnement Python n'est pas persistant (tous les paquets installés disparaissent au redémarrage du pod)
- Aucun moyen d'installer des packages nécessitant un accès root
- Aucune méthode appropriée pour gérer plusieurs environnements à des fins d'expérimentation
- Impossible de configurer un point de terminaison pour le bloc-notes [ajouté dans la prochaine version]
Il est désormais essentiel de résoudre ces limites, car elles bloquent de nombreux flux de travail des Data Scientists, ce qui peut être aussi simple que d'installer des « apt-packages » tels que ffmpeg.
Jusqu'à présent, nous utilisions le images prédéfinies pour Jupyterlab fourni par Kubeflow. Mais puisque nous devons résoudre le problème des environnements non persistants, en autorisant l'accès root et en installant des apt-packages. Nous avons besoin de notre propre ensemble d'images Docker.
Voyons donc comment nous avons résolu ces problèmes !
- A modifié le script d'initialisation de l'image docker et a cloné l'environnement conda de base dans le répertoire personnel et l'a nommé base de Jupiter
- Ajoutez un fichier .condarc et définissez $ MAISON répertoire comme chemin d'environnement par défaut
- Modifiez le fichier .bashrc pour activer le base de Jupiter environnement par défaut
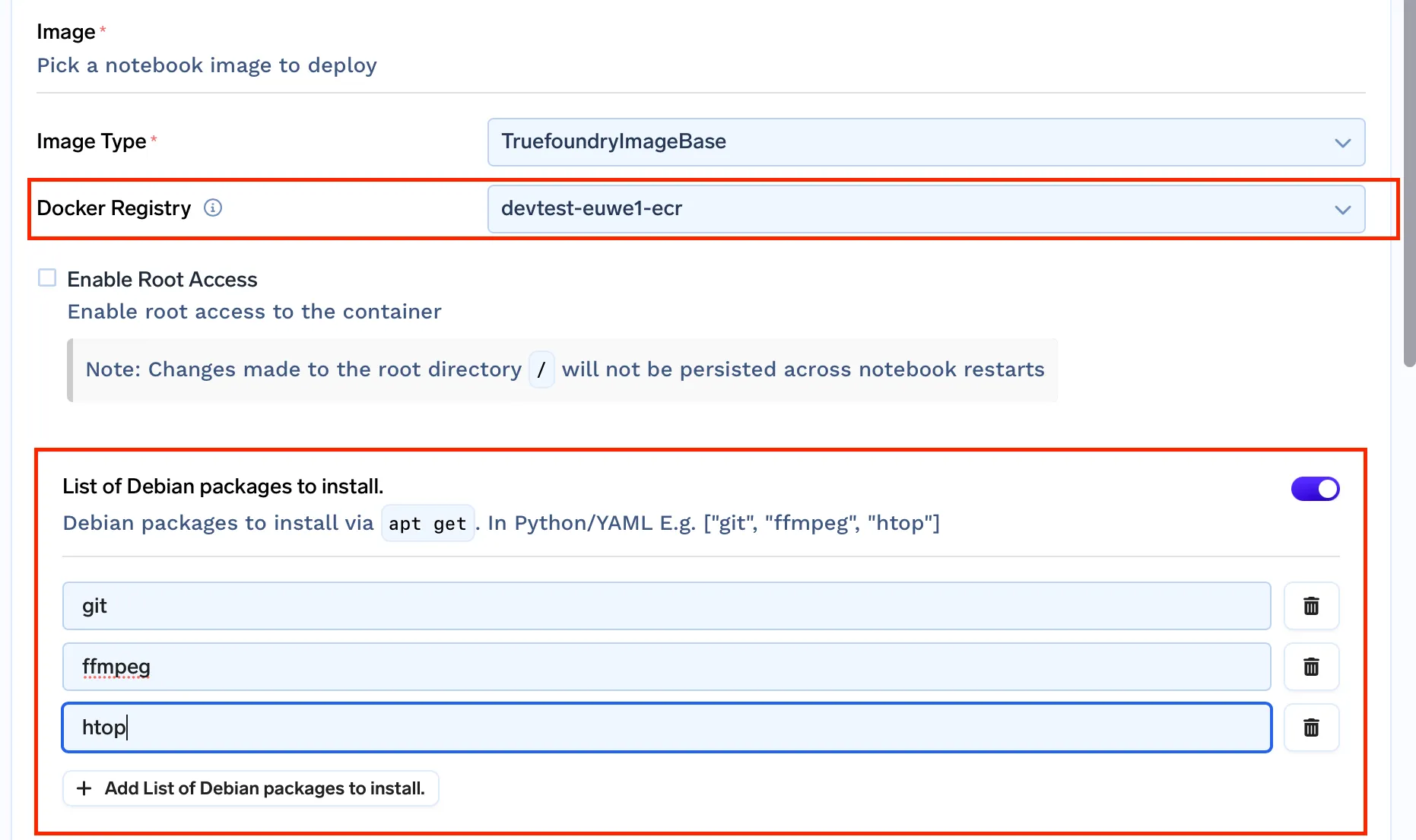
truefoundrycloud/jupyter : dernière version et truefoundrycloud/jupyter : dernier-sudo. Où les images avec sudo fournissent à l'utilisateur un accès sudo à n0 mot de passe.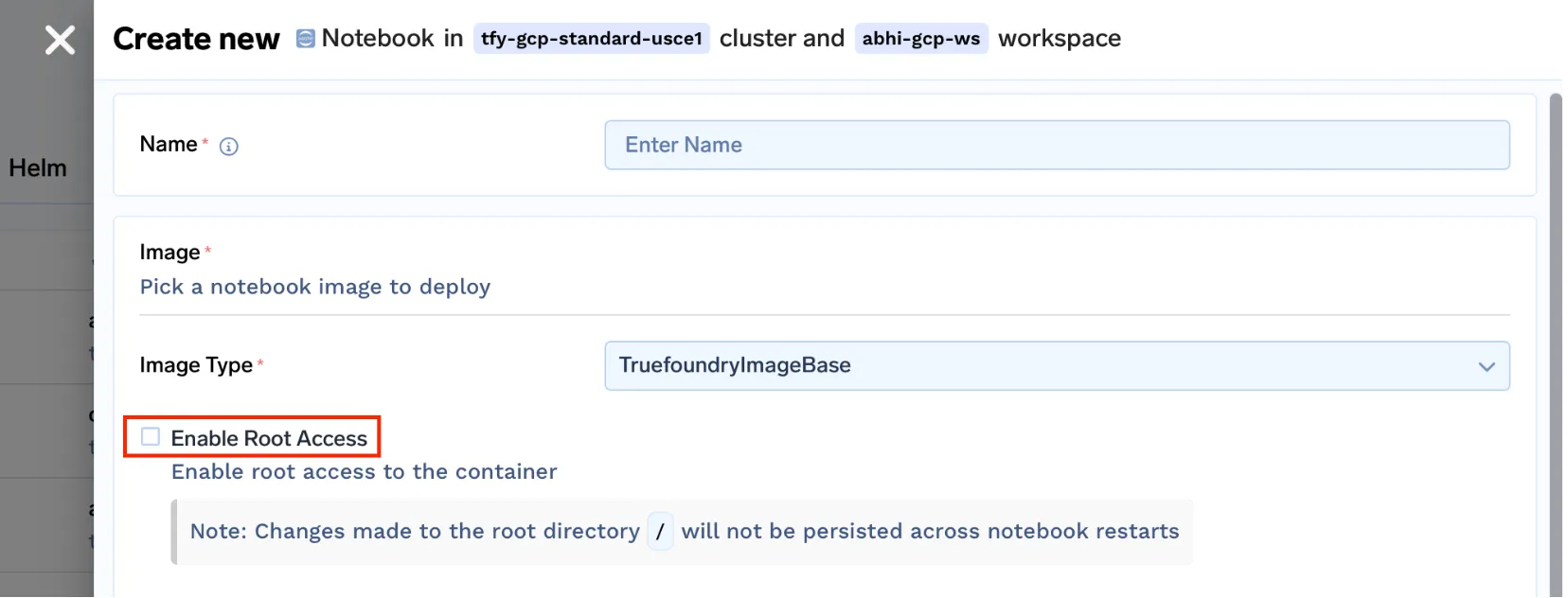
Remarque : étant donné que nous exécutons des blocs-notes sur Kubernetes avec le répertoire personnel monté, seul le répertoire personnel sera persistant. Les installations des packages racine ne seront pas persistantes lors des redémarrages des pods. Veuillez lire ce pour mieux comprendre la même chose.
En résolvant ces problèmes, nous avons résolu la plupart des problèmes rencontrés par les utilisateurs et avons fourni une expérience décente sur les ordinateurs portables. Mais avec le temps, nous avons constaté que les utilisateurs étaient confrontés à quelques défis que nous décrirons dans la section suivante.
jupyterlab le colis. L'environnement étant persistant, le bloc-notes ne démarre pas (une fois que le bloc-notes actuel est arrêté)spécification du noyau et assurez-vous que spécification du noyau est configuré correctement, ce qui peut poser problème.
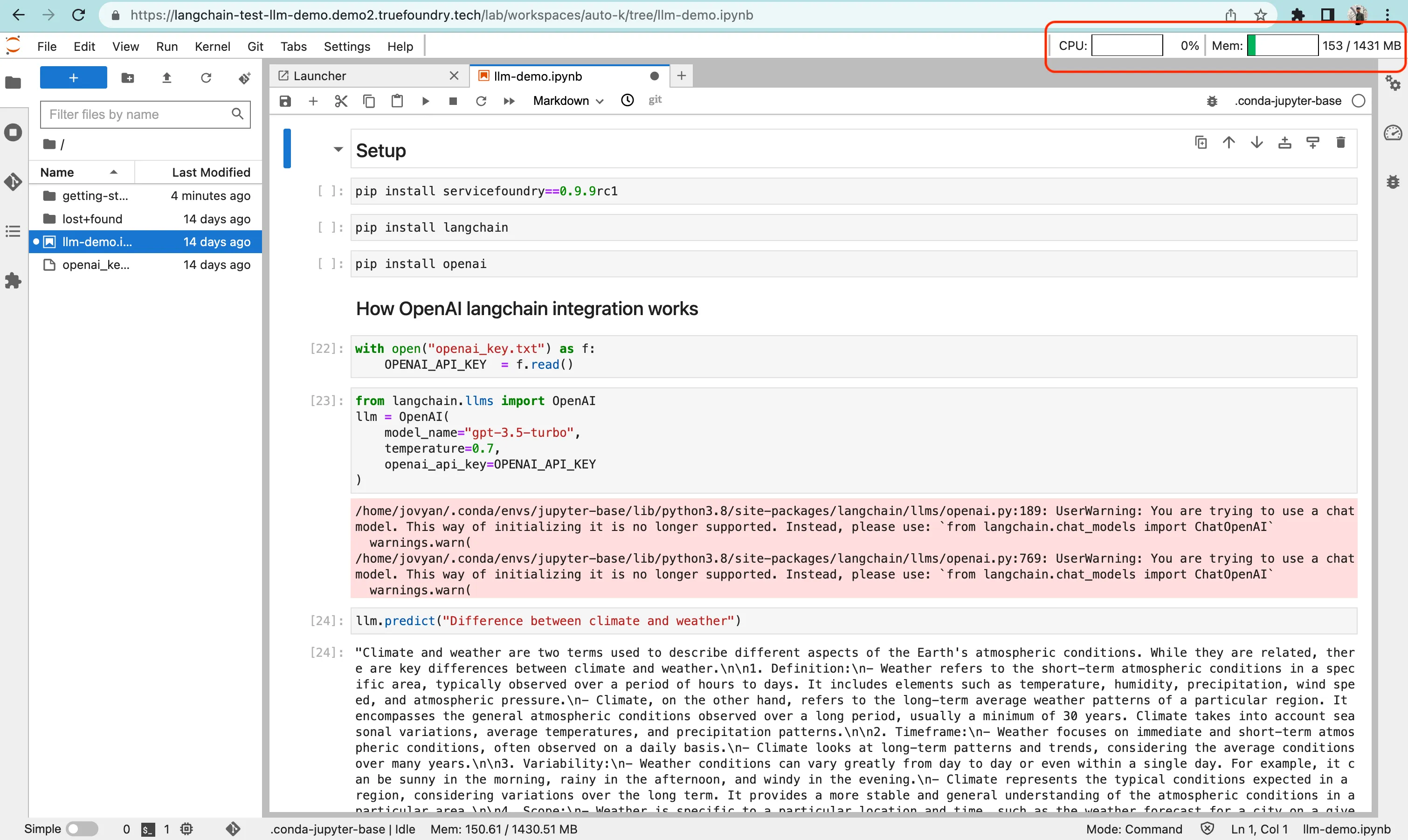
Ajout de mesures d'utilisation des ressources au bloc-notes :
Nous avons ajouté les mesures d'utilisation des ressources au bloc-notes en installant l'extension moniteur du système jupyterlab = 0.8.0 et a configuré ses paramètres dans le script d'initialisation en passant des arguments lors du démarrage du serveur Jupyterlab.
...
laboratoire Jupyter \
...
--resourceUseDisplay.mem_limit=$ {mem_limit} \
--resourceUseDisplay.cpu_limit=$ {cpu_limit} \
--resourceUseDisplay.TRACK_CPU_PERCENT=True \
--ResourceUseDisplay.MEM_WARNING_THRESHOLD=0,8
Voici à quoi cela ressemble sur l'interface utilisateur :
Séparer le noyau qui exécute le serveur Jupyterlab du noyau d'exécution
Nous devons nous assurer que, quelles que soient les modifications apportées par l'utilisateur dans le répertoire personnel, le portable redémarre toujours sans problème. Pour cela, nous avons utilisé l'environnement anaconda « de base » de /opt/conda le répertoire dans lequel démarrer le serveur Jupyterlab.
Parallèlement, nous avons créé un environnement distinct dans $ MAISON répertoire, mais cela ajoute un noyau du base environnement conda aux listes de noyaux.
Pour résoudre ce problème, nous avons installé nb_conda_kernels pour gérer les noyaux Jupyter. Nous avons configuré le script d'initialisation pour nous assurer que seuls les environnements Python persistants apparaissent dans la liste du noyau.
laboratoire Jupyter \
...
--CondaKernelSpecManager.conda_only=Vrai \
--CondaKernelSpecManager.Name_Format= {environnement} \
--CondaKernelSpecManager.env_filter=/opt/conda/* »
Ainsi, nous avons la garantie que le serveur de l'ordinateur portable démarrera toujours avec les modifications apportées par un utilisateur à l'intérieur du bloc-notes.
Cela facilite également la gestion de plusieurs noyaux. Il vous suffit de créer un nouvel environnement conda à l'aide de la commande conda create -n myenv et il commence à apparaître dans la liste des noyaux.
Alors que les ordinateurs portables Jupyter résolvent un certain nombre de problèmes. Il cesse d'aider pour un certain nombre de tâches :
Compte tenu de ces limites, nous avons décidé de résoudre le problème. Nous avons ajouté la prise en charge du serveur de code afin de fournir une expérience IDE complète aux utilisateurs dans le navigateur.
En ajoutant la prise en charge de VS Code, nous permettons aux utilisateurs d'effectuer les opérations suivantes :
hôte local : 8000 peut être mis à disposition sur $ {URL_BLOC-NOTES} /proxy/8000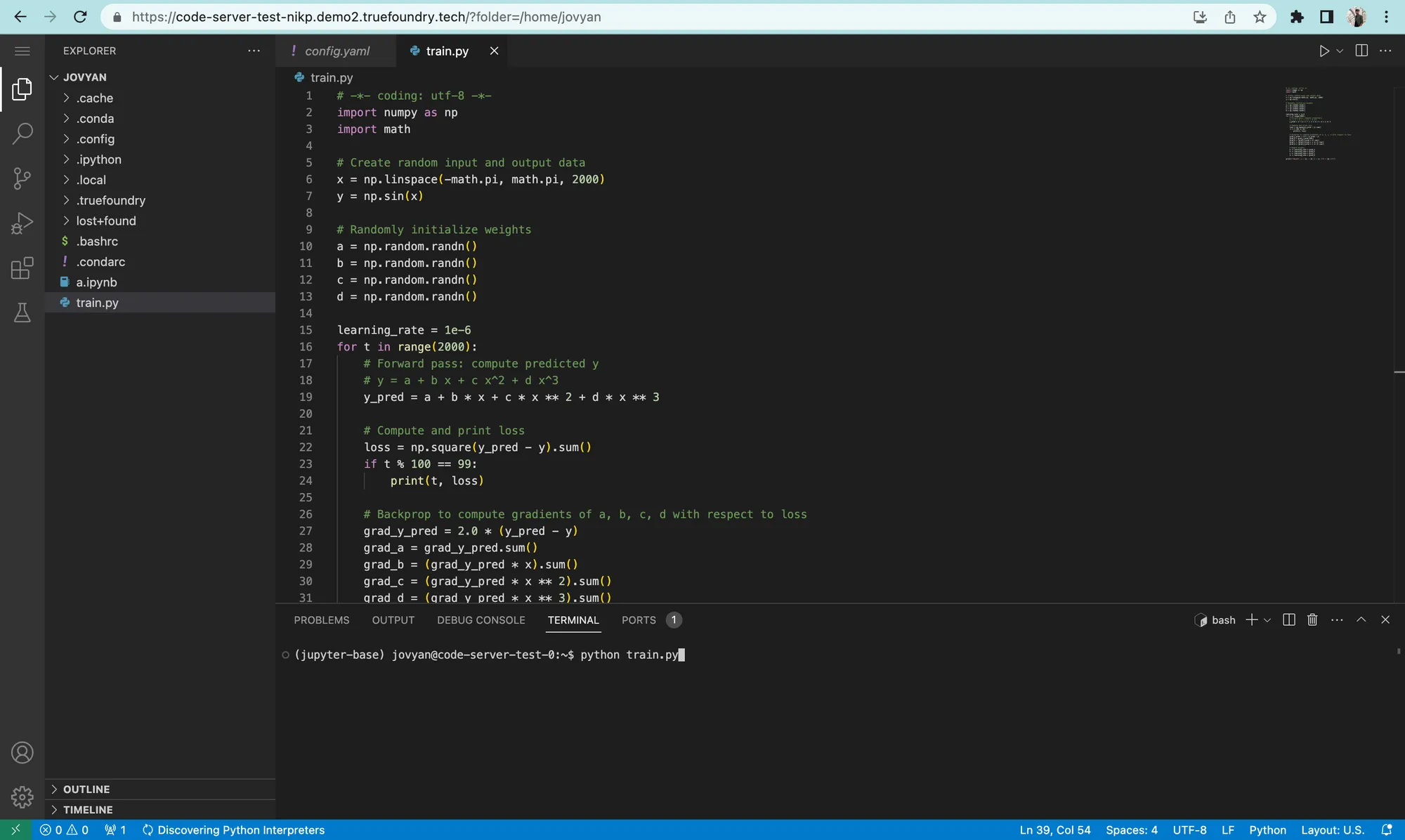
Cela a été fait en ajoutant une autre image Docker. Voici un schéma qui montre les images Docker de Truefoundry.
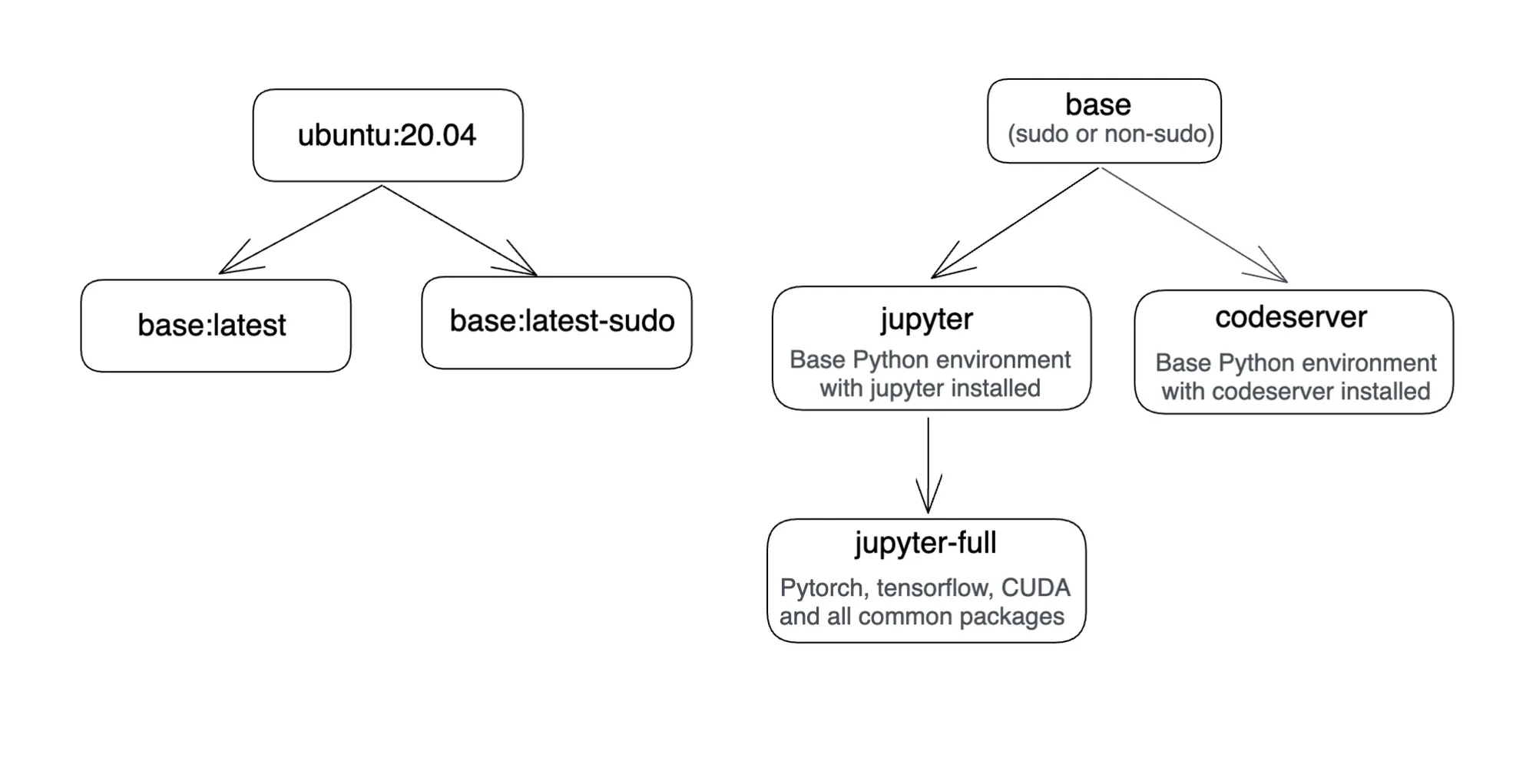
Accès SSH à votre ordinateur portable/VSCode :
Dans la plupart des cas, Hosted VS Code peut résoudre le problème. Mais il peut arriver (en particulier pour les ordinateurs portables Jupyter) que l'utilisateur soit bloqué et ait besoin d'un accès direct au conteneur qui exécute son serveur Jupyter Notebook/VS Code.
Nous avons donc simplifié les choses en installant un serveur SSH dans chacun des blocs-notes et pour vous connecter à votre conteneur, vous devez exécuter une commande simple et saisir votre mot de passe :
ssh -p 2222 jovyan@test-notebook.ctl.truefoundry.tech

La puissance de cet outil peut être améliorée avec votre extension VS Code appelée Explorateur à distance où vous pouvez ouvrir directement tous les fichiers de votre VS Code !
Cliquez ici pour en savoir plus
Avec toutes les fonctionnalités intégrées à notre solution pour ordinateurs portables, voici à quoi ressemble notre formulaire de déploiement d'ordinateurs portables :
Enfin, comparons les prix de chacune des solutions gérées avec Truefoundry.
Comme Truefoundry fonctionne en déployant sur le cloud du client en connectant son cluster Kubernetes, voici la tarification de Truefoundry exécutée sur différents fournisseurs de cloud.
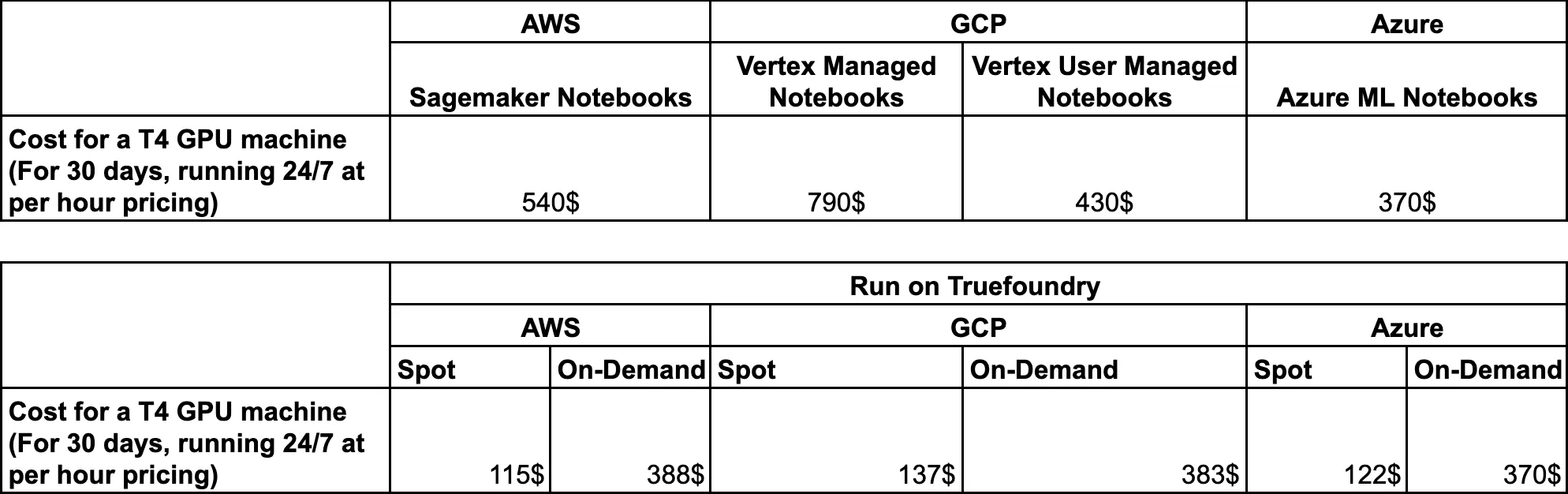
Dans le cas de Truefoundry, vous pouvez réellement économiser beaucoup d'argent car :
Il s'agissait d'une brève description de nos efforts pour créer la solution pour ordinateurs portables. Vous pouvez rejoindre notre Les amis de Truefoundry Canal Slack si vous souhaitez discuter en profondeur de notre approche ou si vous avez des suggestions.
Si vous souhaitez essayer notre plateforme, vous pouvez vous inscrire ici !
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


