Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
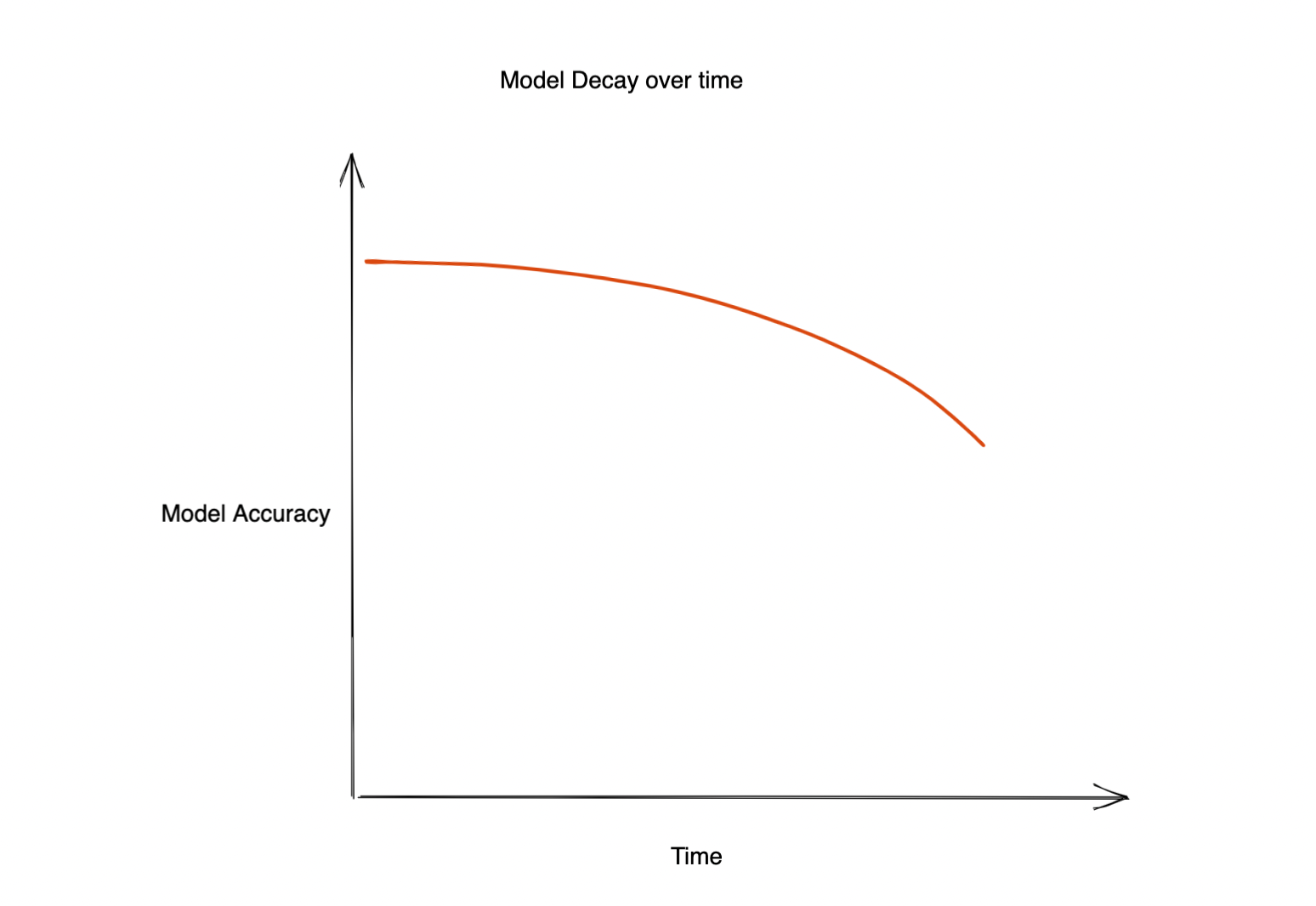
L'apprentissage automatique a un impact significatif sur presque tous les aspects de l'entreprise. Mais souvent, la précision du modèle déployé commence à se dégrader, ce qui entraîne une mauvaise expérience client et a un impact négatif sur l'entreprise. La question est donc la suivante : pourquoi la précision de ce modèle diminue-t-elle ? Cela peut être dû à plusieurs raisons. Par exemple :
Un modèle de détection du spam n'est pas en mesure de détecter correctement les spams après un certain temps, car les « spammeurs » mettent à jour les mots et leurs modèles d'e-mail qui sont « inconnus » du modèle.
Un modèle de recommandation pour les achats peut être affecté de manière significative par des événements mondiaux majeurs tels que l'épidémie de covid-19, qui modifie les préférences des clients.
Un modèle de prévision du taux de désabonnement se dégradera au fil du temps à mesure que les comportements des clients et les habitudes de dépenses évoluent lentement au fil du temps.
Dégradation du modèle au fil du temps
Alors, comment pouvons-nous nous assurer que les performances de notre modèle ne diminuent pas au fil du temps ? Comment savoir quand réentraîner notre modèle pour éviter une baisse de précision ?
La réponse est « dérive ». Il faut détecter la « dérive » en temps opportun et « avec précision » et prendre les mesures appropriées en conséquence.
Qu'est-ce que Model Drift ?
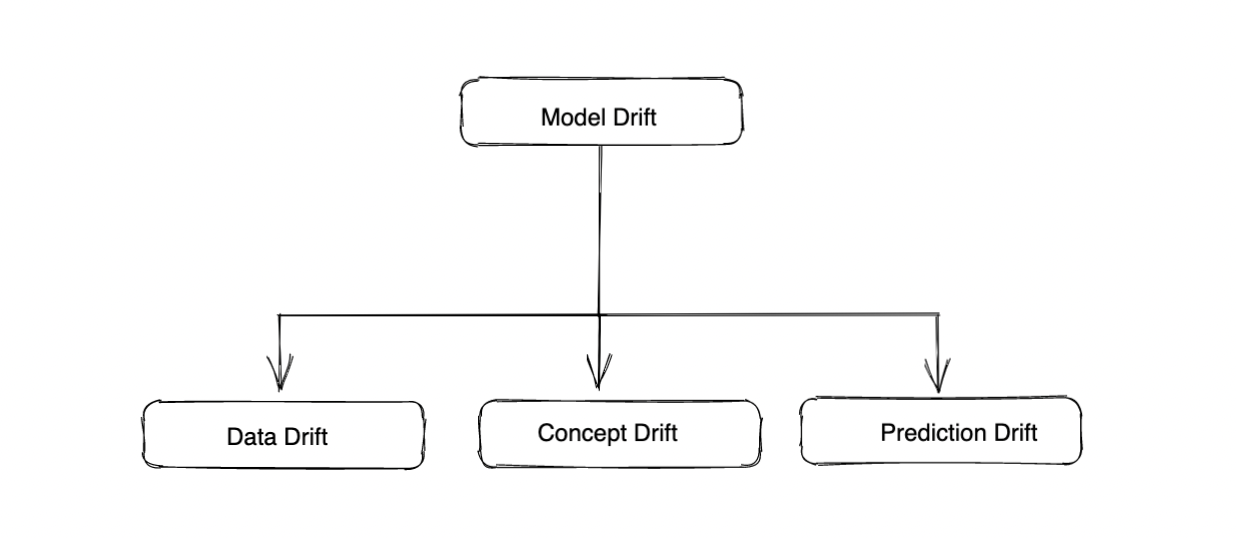
La dérive du modèle fait référence à l'évolution de la distribution des données sur une période donnée. Dans le contexte de l'apprentissage automatique, nous faisons généralement référence aux dérives des caractéristiques des modèles, des prévisions ou des données réelles par rapport à une base de référence donnée.
Plusieurs méthodes sont utilisées pour suivre la dérive, notamment la statistique de Kolmogorov-Smirnov, la distance de Wasserstein et la divergence de Kullback-Leibler. Ces mesures sont souvent utilisées dans des scénarios d'apprentissage en ligne, où le système cible évolue continuellement et où le modèle doit s'adapter en temps réel pour maintenir sa précision. Par exemple, un modèle de recommandation pour les films peut évoluer au fil du temps en fonction de l'évolution du comportement des clients, et un modèle de prévision du taux de désabonnement peut évoluer en fonction de l'évolution de la conjoncture économique.
Différents types de dérive de modèle :
Dérive des données : Cela fait référence à l'évolution de la distribution des différentes caractéristiques ou à l'évolution des relations entre les différentes caractéristiques au fil du temps. Cela peut être dû à des modifications des entrées elles-mêmes. Par exemple, pour un modèle de détermination de la solvabilité basé sur les données d'une année, le revenu moyen évoluerait en raison des changements économiques ou de la récession.
Concept Drift: La dérive conceptuelle fait référence à la dérive des valeurs de vérité du terrain du modèle. Cela indique un changement dans la distribution des valeurs réelles pour lesquelles le modèle est utilisé. La dérive conceptuelle ne dépend pas du modèle mais uniquement des valeurs de vérité sur le terrain. La dérive des valeurs réelles indique qu'il peut y avoir un changement dans la relation entre les caractéristiques et les valeurs réelles (par rapport à l'ensemble de données d'apprentissage ou aux périodes précédentes), ce qui souligne la nécessité de réentraîner le modèle.
Dérive de prédiction: La dérive de prévision fait référence à la dérive de la distribution des valeurs prédites par rapport aux valeurs prévues des données d'entraînement ou des données d'une période passée. La dérive des prévisions indique généralement une dérive sous-jacente des données, car les prédictions sont fonction du modèle et des caractéristiques, et le modèle reste inchangé. La dérive des prévisions peut nous aider à détecter la dérive des données et la diminution de la précision du modèle.
Modèle Drift
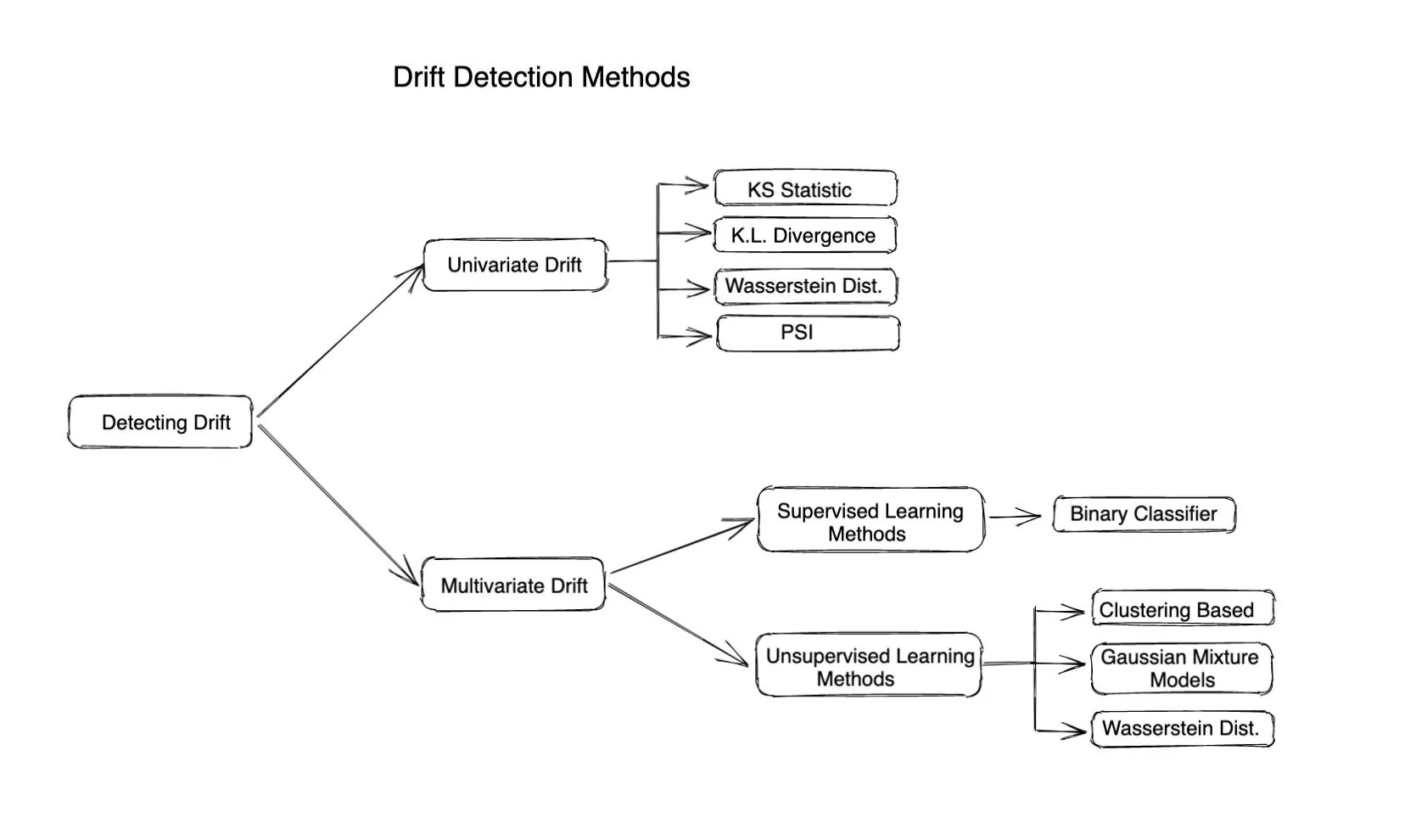
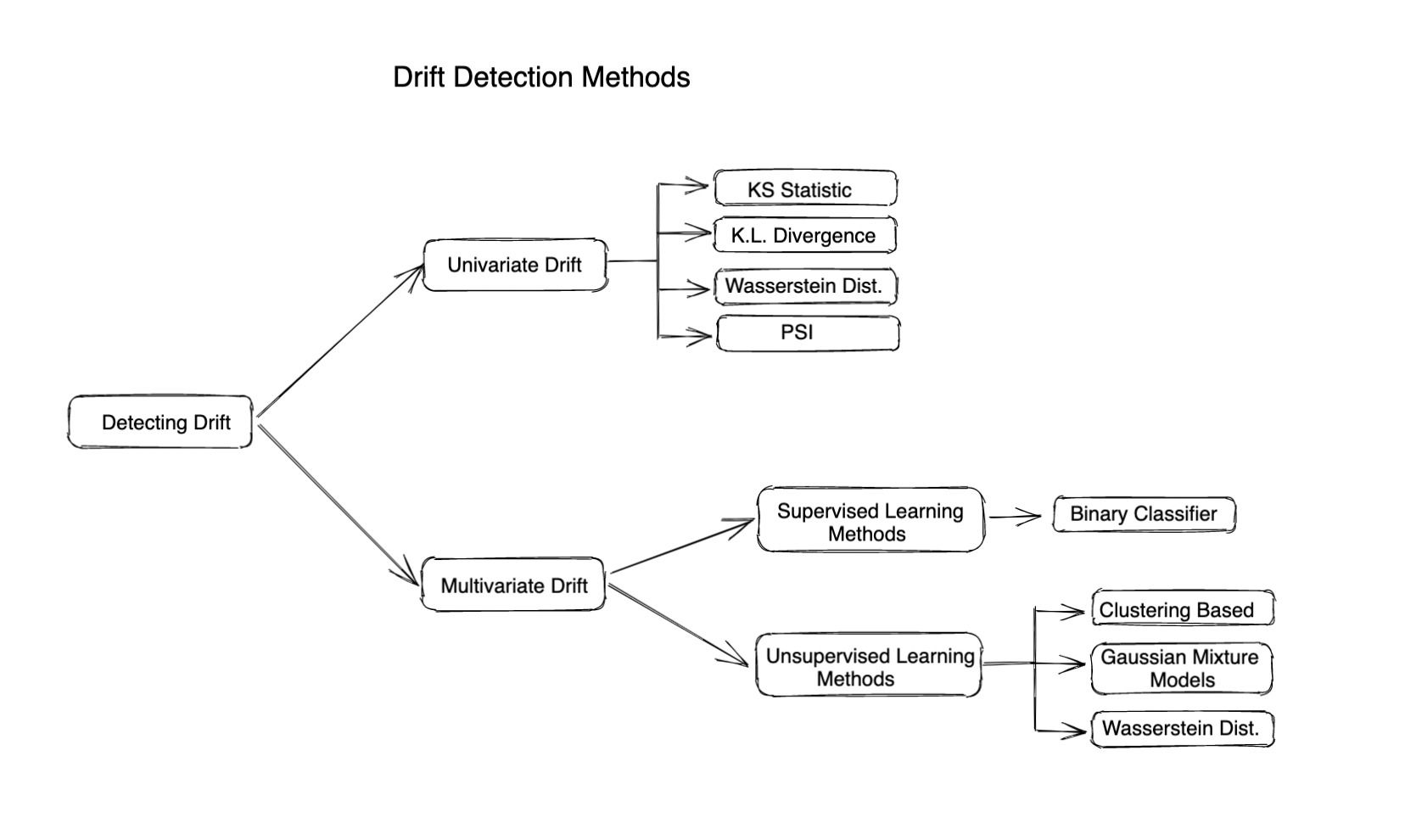
Différentes méthodes de surveillance de la dérive
Méthodes statistiques
Des méthodes statistiques sont utilisées pour mesurer la différence entre la distribution donnée et la distribution de référence. Les métriques ou la divergence basées sur la distance sont souvent utilisées pour calculer la dérive d'une caractéristique ou d'une valeur réelle. Les méthodes statistiques peuvent être efficaces pour détecter les valeurs aberrantes ou les changements dans la distribution des entrées et sont très simples à calculer et à interpréter. Ils ne tiennent pas compte de l'évolution de la corrélation entre les différentes caractéristiques. Ils ne décrivent donc l'histoire complète de la dérive que lorsque les caractéristiques en entrée sont indépendantes.
Voici quelques mesures célèbres basées sur la distance pour calculer la dérive
Statistiques de Kolmogorov-Smirnov : Il mesure la différence maximale entre deux fonctions de distribution cumulées. Il s'agit d'un test non paramétrique qui ne suppose pas de distribution spécifique pour les données. Il est largement utilisé dans la détection de dérive en raison de sa capacité à détecter les changements dans la distribution des données.
Distance de Wasserstein : Elle est également connue sous le nom de distance du moteur-terrestre (EMD). Il mesure la quantité de « travail » nécessaire pour transformer une distribution en une autre. Il a la capacité de capturer des changements subtils dans la distribution des données qui peuvent ne pas être capturés par d'autres mesures de distance.
La distance de Wasserstein a récemment gagné en popularité en raison de sa capacité à gérer des données de grande dimension et bruyantes.
Divergence entre Kullback et Leibler : Il s'agit d'une mesure de la différence entre deux distributions de probabilité, également appelée entropie relative ou divergence d'informations. Il s'agit d'une métrique non symétrique, ce qui signifie que la divergence KL de la distribution A à la distribution B n'est pas égale à la divergence KL de la distribution B à la distribution A.
C'est l'une des métriques les plus utilisées pour le suivi de la dérive, mais la cardinalité de la caractéristique/prédiction suivie ne devrait pas être très élevée.
PSI (Indice de stabilité de la population) : Le PSI mesure l'évolution d'une population au fil du temps ou entre deux échantillons différents d'une population en un seul chiffre. Pour ce faire, il regroupe les deux distributions et compare les pourcentages d'éléments dans chacune des catégories, ce qui donne un chiffre unique que vous pouvez utiliser pour comprendre les différences entre les populations. Les interprétations courantes du résultat du PSI sont les suivantes :
Ainsi, il est possible de configurer des moniteurs sur la valeur de dérive des caractéristiques qui ont un impact sur la précision du modèle et de prendre des mesures pertinentes en fonction de cela.
Dérive au niveau du modèle (détection de dérive multivariée)
La détection de dérive multivariée permet de détecter les changements ou les dérives de plusieurs variables ou caractéristiques en même temps. Contrairement à la détection de dérive univariée, qui se concentre uniquement sur la détection des changements dans une seule variable, la détection de dérive multivariée prend en compte la relation entre plusieurs caractéristiques et ne suppose pas que toutes les caractéristiques sont indépendantes les unes des autres.
Ainsi, les méthodes de détection de dérive multivariée peuvent détecter des changements dans la distribution des données, des changements dans la relation entre les variables et des changements dans la relation fonctionnelle entre les variables. Ces méthodes sont particulièrement utiles dans les systèmes complexes où les modifications d'une variable peuvent avoir un impact significatif sur le comportement d'autres variables. La dérive multivariée aide donc les utilisateurs à mieux comprendre les modifications des données d'inférence. Il est également plus facile à surveiller car une seule métrique doit être suivie au lieu de suivre chaque caractéristique séparément. Mais en même temps, son calcul est fastidieux et peut être excessif pour des systèmes plus simples.
Les algorithmes de détection de dérive multivariés dépendent généralement d'un modèle d'apprentissage automatique pour calculer la dérive. Ces algorithmes peuvent donc être classés comme suit :
Utilisation de méthodes supervisées: Celles-ci reposent généralement sur l'entraînement d'un modèle de classification binaire pour deviner si un point de données provient de la base de données de référence. Une valeur plus élevée de la précision du modèle indique une dérive plus importante.
Pour déterminer quelles caractéristiques ont dérivé, l'importance des caractéristiques de ce modèle de classification binaire est utilisée.
Méthodes d'apprentissage non supervisées : Voici quelques méthodes : Regroupement: utilisez K-means, DBSCAN ou tout autre algorithme de clustering pour rechercher des clusters dans le jeu de données de référence et le jeu de données actuel, puis recherchez les différences entre les clusters afin de déterminer si les données ont dérivé ou non.
Modèles de mélange gaussien (GMM): GMM représente nos données sous la forme d'un mélange de distributions gaussiennes. Le GMM peut être utilisé pour détecter une dérive multivariée en comparant les paramètres des distributions gaussiennes de l'ensemble de données actuel avec ceux de l'ensemble de données de référence.
Analyse en composantes principales (PCA): utilisez le PCA pour réduire les dimensions de l'ensemble de données, puis utilisez des algorithmes de détection de dérive univariés réguliers en considérant que les caractéristiques sont uniques.
En résumé, la détection de dérive multivariée est utile dans les systèmes complexes et est plus facile à surveiller car il n'y a qu'un seul KPI à surveiller.
Détection de la dérive du modèle
Conclusion :
Les performances d'un modèle déployé en production finiront par diminuer. Le temps nécessaire à cette dégradation dépendra du cas d'utilisation. Dans certains cas, les modèles peuvent ne pas dériver avant un an, tandis que certains modèles peuvent nécessiter une nouvelle formation toutes les heures ! Il est donc extrêmement important de comprendre la cause de cette dégradation et de la détecter. C'est là que la « détection précoce de la dérive » peut être utile.
En conclusion, les modèles en production devraient disposer de mécanismes appropriés de suivi ou de surveillance de la dérive et de pipelines de recyclage mis en place pour tirer le meilleur parti d'un modèle d'apprentissage automatique !
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


