Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Gemini 3 contre Kimi-K2 Thinking contre Grok-4.1 contre GPT-5.1 : qui gagne réellement le dernier examen de l'humanité ?
Published: April 22, 2026
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Gère plus de 350 RPS sur un seul processeur virtuel, aucun réglage n'est nécessaire
Prêt pour la production avec un support complet pour les entreprises
Quand Google dit « Planifiez n'importe quoi » avec Gemini 3, Moonshot affirme que Kimi-K2 Thinking est le nouveau raisonnement SOTA, XiAI qualifie Grok-4 de « modèle le plus intelligent au monde », et OpenAI continue de faire avancer GPT-5.1. Il est difficile de savoir ce qui est réel et ce qui n'est que des vibrations.
Au lieu d'un autre mur de graphiques de référence, voici une question plus précise :
Que se passe-t-il si vous soumettez Gemini 3, Kimi-K2 Thinking, Grok-4.1 et GPT-5.1 à la même série de problèmes de style Humanity's Last Exam, et que vous regardez comment Ils pensent ?
Dans ce billet :
Pourquoi Le dernier examen de l'humanité (HLE) est devenu le « patron final » des benchmarks académiques.
Petit tour d'horizon de Gemini 3, Kimi-K2 Thinking, Grok-4.1 et GPT-5.1 en tant que modèles « pensants ».
Cinq études de cas concrètes de style HLE dans les domaines des mathématiques, de la physique multimodale, de la science du contexte long, de la théorie des jeux et de la planification.
Comment faites vous-même les mêmes expériences via la passerelle TrueFoundry AI.
1. Le dernier examen de l'humanité en 2 minutes
Les benchmarks tels que MMLU sont essentiellement « réalisés » à la frontière. De nombreux modèles haut de gamme y ont un taux supérieur à 90 %, donc un autre modèle avec +1 ou − 1 % ne vous dit pas grand-chose sur ce que c'est que de travailler avec.
Le dernier examen de l'humanité (HLE) est différent :
Il s'agit d'un examen organisé par des experts mathématiques, sciences naturelles, ingénierie, économie, sciences humaines, droit, etc..
Il mélange choix multiples et correspondance exacte questions, dont beaucoup nécessitent plusieurs étapes de raisonnement non évidentes.
Une partie des questions sont plurimodale, obligeant les modèles à raisonner conjointement sur du texte et des images.
Surtout, même les meilleurs modèles actuels sont toujours loin du niveau d'expert humain sur HLE, et leur confiance est souvent mal calibrée.
Les auteurs demandent explicitement aux gens ne pas republier les questions brutes, car ils souhaitent que HLE reste une référence utile à long terme. Donc dans ce post :
Nous ne pas afficher le libellé original de toute question.
Au lieu de cela, nous décrivons cinq tâches représentatives de type HLE et comment les modèles se comportent sur eux.
Vous pouvez reproduire ces modèles vous-même à l'aide de l'ensemble de données HLE public ou de problèmes similaires provenant de votre propre domaine.
2. Quatre modèles « pensants » en 2025
Nous ne comparons pas des « chatbots » ici, nous examinons des modèles présentés explicitement comme raisonneurs: chaîne de pensée approfondie, outils, contexte long, planification.
Gemini 3 (Pro + Deep Think)
Google présente Gémeaux 3 comme son modèle le plus performant à ce jour :
Plus fort raisonnement et compréhension multimodale que la génération Gemini 2.5.
Des scores compétitifs sur HLE sans outils, ainsi que d'excellentes performances sur GPQA, MMMU-Pro, Video-MMMU et d'autres benchmarks de raisonnement.
L'accent est mis sur les agents qui utilisent des outils à long terme : l'histoire de « tout planifier », y compris les meilleurs résultats sur des critères de planification tels que Vending-Bench.
Gemini 3 expose également un Penser profondément mode qui dépense plus de calcul et de jetons sur des problèmes difficiles afin d'obtenir un peu plus de précision.
La pensée Kimi-K2
Moonshot La pensée Kimi-K2 est un modèle de « réflexion » ouvert :
Architecture mixte d'experts avec un budget total de paramètres énorme mais un sous-ensemble actif plus petit par jeton.
Contexte long (des centaines de milliers de jetons) et chaîne de pensée très lourde par conception.
Les analyses publiques montrent souvent que Kimi-K2 Thinking et sa variante « lourde » se situent en tête ou presque du haut du classement HLE et d'autres critères de raisonnement.
Si vous avez déjà vu un mannequin déborder pages de monologue interne pour un problème mathématique : c'est l'esthétique du style Kimi.
Grok-4/Grok-4.1
Les AxI Grok-4 la ligne est présentée comme suit :
Une personne très compétente raisonnement modèle avec utilisation d'outils natifs et recherche sur Internet.
Solide pour les tâches HLE, GPQA et à long terme où les agents doivent maintenir un comportement cohérent sur de nombreuses étapes.
Grok-4.1 met davantage l'accent sur l'intelligence « émotionnelle » et créative, tout en conservant la force de raisonnement de base.
Considérez GROK-4.x comme le modèle qui veut vraiment être un agent: planifiez, recherchez, agissez, réfléchissez, répétez.
GPT-5.1 (famille GPT-5)
OpenAI GPT-5 la famille est la base de référence que la plupart des gens atteignent pour :
Très solide sur de larges suites de critères de référence : codage, raisonnement, multimodal, contexte long.
Lorsqu'il est exécuté dans un mode « effort de raisonnement »/« réflexion » élevé, il alloue plus de jetons et résout les problèmes difficiles et tend à combler l'écart par rapport aux benchmarks avancés tels que HLE et GPQA.
Nous ferons référence à GPT-5.1 Réflexion en tant que variante GPT-5 fonctionnant dans ce profil d'effort élevé.
3. Comment nous les avons comparés (sans fuite de HLE)
L'objectif n'était pas de créer un autre classement, mais de voir comment ces modèles se comportent sur des tâches de style HLE.
À un niveau élevé :
Nous avons sélectionné un ensemble de questions HLE représentatives (mathématiques, physique multimodale, longs passages scientifiques, théorie des jeux, planification).
Pour chaque question, nous avons utilisé un invite « exam-mode »:
« Raisonnez étape par étape. »
« Expliquez votre façon de penser. »
« Terminez avec la réponse finale :... et la confiance :... »
Nous avons posé exactement la même question et le même échafaudage :
La pensée Kimi-K2
Grok-4.1
GPT-5.1 Réflexion
Gémeaux 3 Pro (et le cas échéant, Gemini 3 Deep Think)
Tout cela a été câblé via Passerelle TrueFoundry AI:
Un terminal sur lequel nous connectons OpenAI, Google, xAI, Moonshot et plus de 1000 autres modèles.
Un seul endroit pour enregistrer les réponses, les jetons, la latence et le coût par appel.
Un ensemble d'autorisations, de quotas et de garanties pour tous les fournisseurs.
Nous y reviendrons plus tard. Pour l'instant, examinons les cinq études de cas.
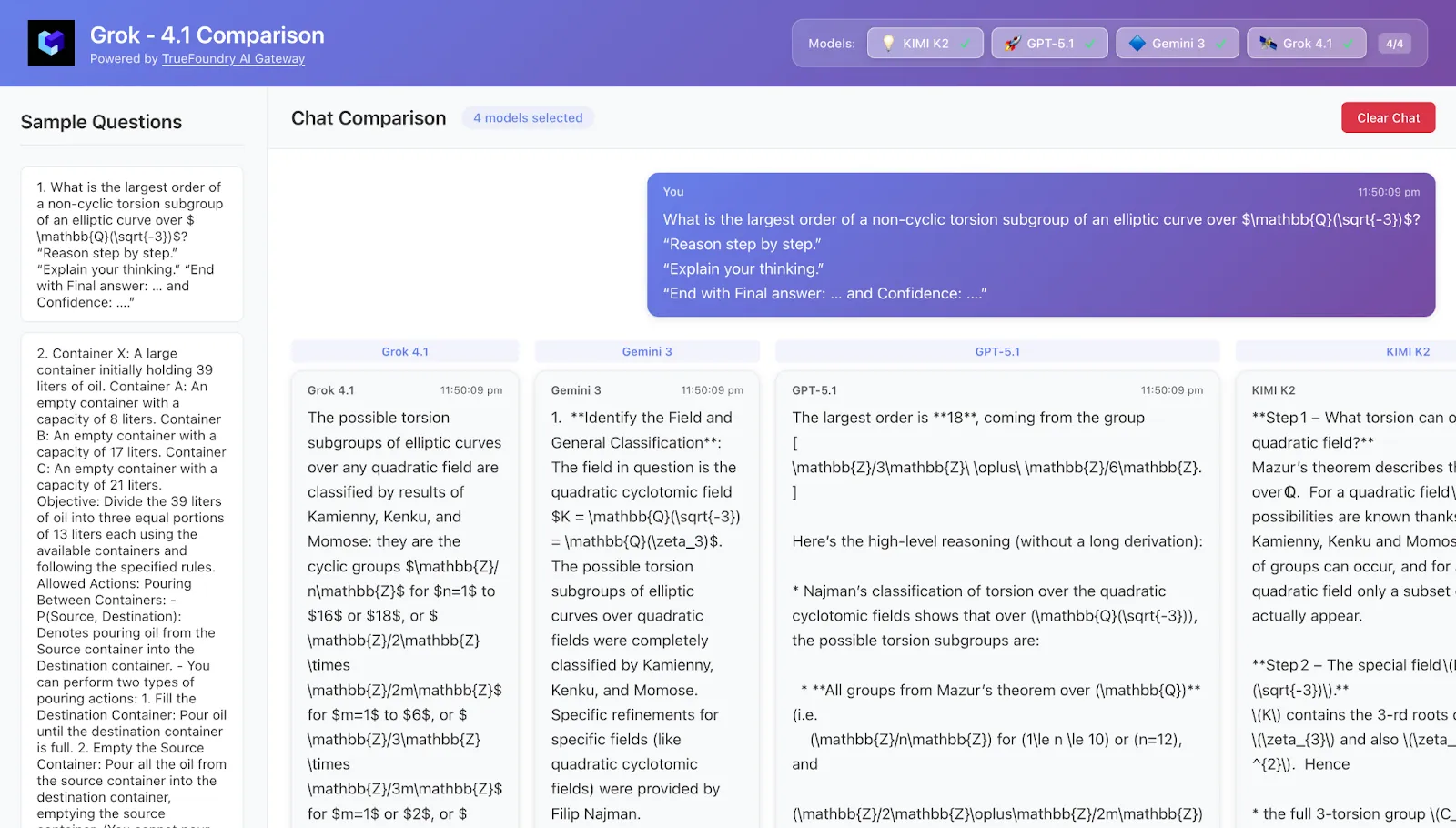
4. Étude de cas 1 — Mathématiques approfondies : précision contre réflexion avide de jetons
Tâche Un problème de mathématiques de niveau supérieur (pensez à la théorie des nombres ou à la combinatoire) :
Réponse courte unique (un entier ou une expression simple).
Nécessite environ 4 à 6 étapes de raisonnement non évidentes.
Il est très difficile de deviner correctement sans vraiment le résoudre.
Ce que nous examinons
Est-ce que le modèle mettre en place la structure correctement (par exemple, bon théorème/classification) ?
Est-ce qu'il poursuit le raisonnement jusqu'au bout sans perdre de signe négatif ?
Combien jetons est-ce que ça brûle pour y arriver ?
Comment calibré est-ce que c'est de la confiance ?
Schémas typiques observés
La pensée Kimi-K2
Une chaîne de pensée extrêmement longue : rappelle des théorèmes pertinents, explore de multiples approches candidates, se ramifie et revient souvent en arrière.
Très précis, surtout en mode « Heavy », mais dépense souvent beaucoup plus de jetons que les autres.
La confiance autodéclarée se situe souvent entre 90 et 100 %, même pour des problèmes assez délicats.
Grok-4.1
Audacieux et exploratoire : esquisse rapidement une réponse intuitive, puis tente de la justifier.
Quand c'est bien, ça a l'air génial ; quand c'est faux, ça peut l'être très confiant.
GPT-5.1 Réflexion
Bonne structure : énumère clairement les cas, les étiquette et renvoie clairement.
Ses estimations de confiance sont souvent légèrement plus modestes, en particulier lorsque le problème nécessite de multiples faits approfondis.
Gemini 3 (Pro/Deep Think)
Raisonnement en plusieurs étapes, mais visiblement plus concis que les murs de texte de Kimi-K2.
Le mode Deep Think comble une grande partie de l'écart entre HLE et Kimi/Grok, tout en restant un peu plus mesuré dans ses explications.
Plats à emporter Si vous poursuivez chaque point supplémentaire sur les mathématiques de style HLE, Kimi-K2 Thinking et Grok-4.x semblent être les leaders, suivis de près par Gemini 3 Deep Think. Si vous vous souciez de coût et rapidité En ce qui concerne la précision brute, Gemini 3 et GPT-5.1 Thinking sont attrayants car ils permettent d'obtenir des résultats similaires tout en étant moins gourmands en jetons.
5. Étude de cas 2 — Physique multimodale : « regardez réellement le schéma »
Tâche Une question de physique/ingénierie lourde de diagrammes :
Un schéma de circuit, un schéma de corps libre ou une configuration optique est intégré sous forme d'image.
La question demande une réponse numérique (par exemple, courant, angle, temps).
Vous ne pouvez pas répondre correctement sans analyse de la figure correctement.
Ce que nous examinons
Est-ce que le modèle décrire le schéma d'une manière qui correspond à l'image ?
Est-ce que ça fait hypothèses non présentes dans l'image ?
Dans quelle mesure combine-t-il l'image et le texte pour obtenir une dérivation cohérente ?
Schémas typiques observés
Gémeaux 3
L'image elle-même est très réfléchie : « la flèche pointe vers la gauche », « il y a trois résistances en série », « la masse est attachée par deux ressorts ».
Moins d'hallucinations quant au contenu du schéma.
Dans l'ensemble, je pense que c'est le plus mis à la terre dans son raisonnement multimodal.
GPT-5.1 Réflexion
Compréhension multimodale solide, mais souvent moins explicite : elle utilise correctement le diagramme, mais ne le décrit pas toujours en détail.
En cas d'échec, c'est généralement dû à une mauvaise lecture du texte plutôt que de l'image.
La pensée Kimi-K2
Une fois que les données sont correctes, la physique est solide.
Mais sous pression, il peut mal compter les éléments du diagramme (par exemple, le nombre de composants), puis propager cette erreur par une dérivation très longue.
Grok-4.1
Style similaire à celui de GPT-5.1 : intuitif, souvent juste, mais parfois trop confiant sur une ligne ou une étiquette mal interprétée.
Plats à emporter Si une grande partie de votre charge de travail de type HLE implique des diagrammes, des schémas ou des énigmes visuelles, la solution multimodale de Gemini 3 se démarque. GPT-5.1, Kimi-K2 et Grok-4.1 sont tous performants, mais plus enclins à « voir » des détails qui ne sont pas tout à fait là.
6. Étude de cas 3 — Science contextuelle à long terme : lire, pas seulement résoudre
Tâche Un passage scientifique long et dense (biologie/médecine/chimie) :
Plusieurs paragraphes décrivant une expérience, les méthodes, les résultats et les mises en garde.
Ensuite, une question qui nécessite intégrer les informations tout au long du passage, et pas seulement le dernier paragraphe.
Ce que nous examinons
Est-ce que le modèle résumer le passage avec précision ?
Est-ce qu'il assure le suivi de variables, conditions et exceptions à travers les paragraphes ?
Identifie-t-il correctement quels détails compte vraiment pour répondre à la question ?
Schémas typiques observés
Gémeaux 3
Bon pour comprimer de longs passages dans puces focalisées au laser.
A tendance à reformuler les principaux faits, puis à raisonner « à partir des notes » pour trouver la réponse.
Se contredit rarement lorsqu'il fait référence aux parties précédentes du passage.
GPT-5.1 Réflexion
Excellent pour le suivi des variables et des configurations expérimentales ; cela ressemble à un AT prudent.
Souvent, le pipeline « lire → résumer → déduire » le plus propre.
La pensée Kimi-K2
Hyper-détaillé : reprend une grande partie du passage et en reprend parfois la théorie de base.
Cette profondeur est utile, mais en raison de sa longueur, une dérive occasionnelle ou une contradiction interne peuvent s'infiltrer.
Grok-4.1
Très bon pour extraire implications pratiques (« cela suggère que le traitement A est préférable lorsque... »).
Parfois, des gloses recouvrent les rares cas marginaux mentionnés dans le texte.
Plats à emporter Pour le style HLE « lis ceci et comprends-le réellement » Les questions, Gemini 3 et GPT-5.1 Thinking sont particulièrement efficaces : elles résument de manière précise, préservent les détails importants et maintiennent la logique. Kimi-K2 et Grok-4.1 sont également performants, mais leurs récits plus longs peuvent présenter davantage de possibilités de dérive.
7. Étude de cas 4 — Théorie des jeux et microéconomie : qui raisonne comme un assistant technique ?
Tâche Une question de microéconomie et de théorie des jeux :
Plusieurs joueurs, un petit set d'action et des descriptions des gains.
On vous demande de trouver des équilibres, de caractériser des stratégies ou de comparer les résultats en matière de bien-être.
Ce que nous examinons
Est-ce que le modèle énumérer tous les cas pertinents?
Est-ce que cela permet de maintenir la cohérence de la logique entre l'analyse de cas et la réponse finale ?
Est-il conscient de subtilités telles que les stratégies mixtes, la dominance ou la symétrie ?
Schémas typiques observés
La pensée Kimi-K2
Il se lit comme un assistant technique d'étudiant diplômé : de nombreuses analyses au cas par cas, construction explicite de contre-exemples, examen attentif des cas extrêmes.
Très fort quand on veut voir l'arbre de raisonnement complet.
Grok-4.1
Intuitivement excellent pour raisonnement incitatif (« si le joueur A dévie, il gagne X, donc cela ne peut pas être un équilibre »).
Il parvient parfois très tôt à un équilibre intuitif et a besoin d'être incité à reconsidérer.
GPT-5.1 Réflexion
Systématique : étiquette les cas (cas 1, cas 2,...), résume les résultats et les relie facilement.
Bon équilibre entre profondeur et brièveté.
Gémeaux 3
Structure similaire à celle de GPT-5.1, avec une tendance un peu plus à revenir en arrière de manière explicite (« reconsidérons l'hypothèse que... »), en particulier dans un mode de style Deep Think.
Plats à emporter En ce qui concerne les questions HLE relatives à la théorie des jeux, La pensée Kimi-K2 et Grok-4.1 se sentir le plus proche d'un assistant d'enseignement humain : beaucoup de cas explicites et une discussion intuitive. Gémeaux 3 et GPT-5.1 trouvez la réponse avec moins d'errances, ce qui peut être préférable lorsque vous redirigez les sorties directement vers du code ou des pipelines de décision.
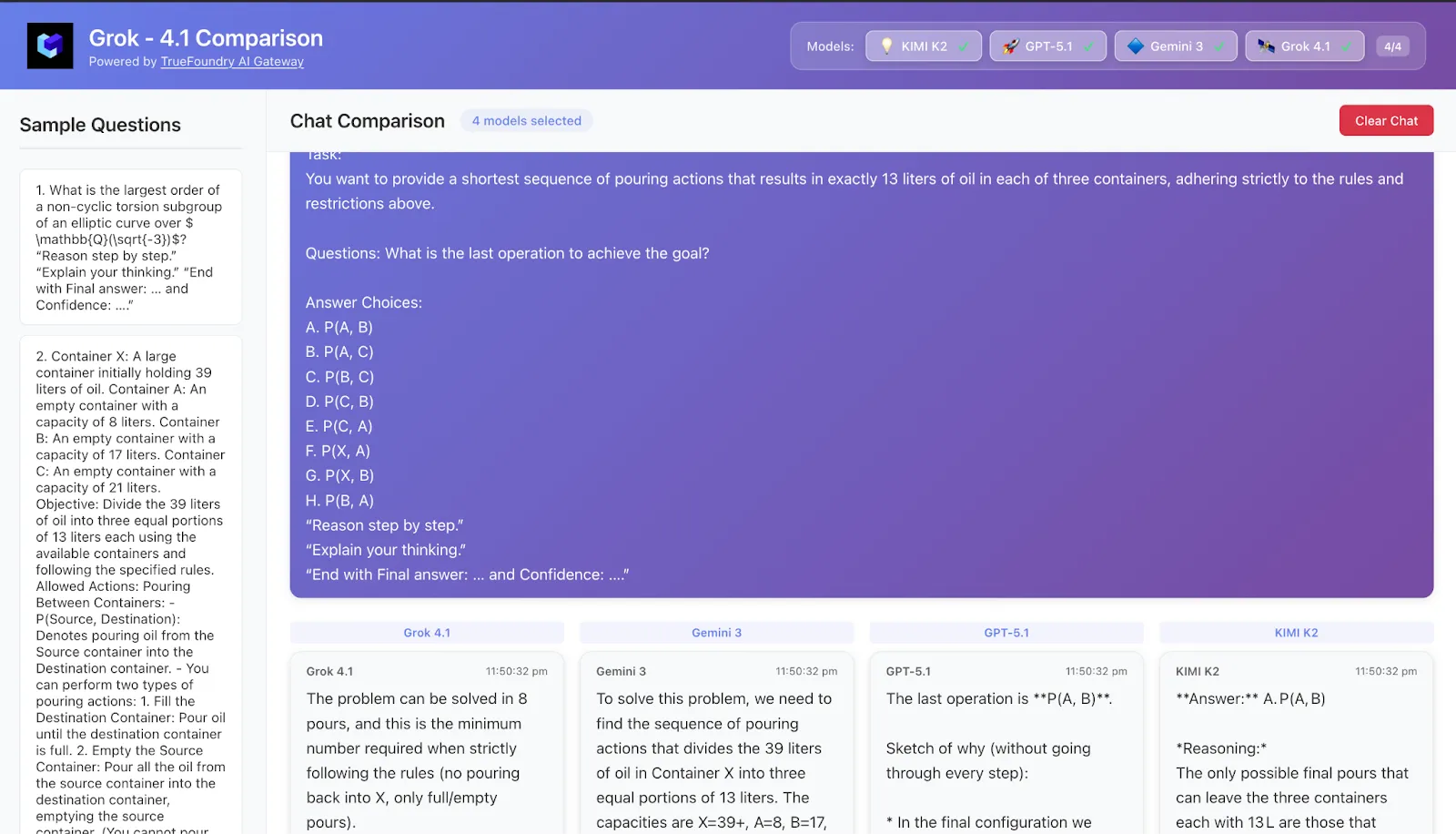
8. Étude de cas 5 — Problèmes de planification : des mini-agents au cœur d'une invite
Tâche Un casse-tête semblable à la planification et à la recherche opérationnelle :
Plusieurs conteneurs, capacités et règles de versement, ou une configuration de planification et de gestion des stocks.
Vous devez choisir une politique ou une séquence d'actions qui permet d'atteindre un objectif dans étapes minimales soumis à des contraintes.
Ce que nous examinons
Est-ce que le modèle configurer l'espace d'état clairement ?
Est-ce qu'il simule correctement les séquences sans oublier les actions précédentes ?
S'en tient-il aux contraintes qu'il a lui-même énoncées ?
Schémas typiques observés
Grok-4.1
Très semblable à un agent : écrit explicitement les états (« après l'étape 3 : l'inventaire est X, Y, Z »), compare chacun d'eux par rapport à l'objectif et corrige le cap si nécessaire.
Cela ressemble le plus à l'utilisation d'un véritable agent de planification au sein d'une seule invite.
Gémeaux 3
Style de planification similaire : redéfinit l'objectif et les contraintes, propose une politique, puis simule plusieurs étapes.
Particulièrement doué pour ne pas perdre le fil d'état sur des séquences plus longues, ce qui correspond bien à son inclinaison à long horizon/Vending-Bench.
GPT-5.1 Réflexion
Bonne planification conceptuelle, mais plus sujette à de petites erreurs arithmétiques ou comptables à de nombreuses étapes.
Lorsqu'on lui demande de garantir la « séquence la plus courte », il faut parfois faire un deuxième essai.
La pensée Kimi-K2
Fournit de nombreuses simulations détaillées, mais la combinaison d'un CoT long et d'un état complexe entraîne parfois de petites incohérences (par exemple, une quantité qui change silencieusement entre les étapes).
Plats à emporter À propos des tâches HLE liées à la planification, Grok-4.1 et Gémeaux 3 sentez-vous comme les mini-agents les plus fiables. Kimi-K2 et GPT-5.1 sont très performants, mais leurs longues traces de raisonnement peuvent parfois leur être défavorables lorsque le suivi de l'état est essentiel.
9. Alors... qui « gagne » le dernier examen de l'humanité ?
Si vous ne regardez que pourcentages HLE principaux, Kimi-K2 Thinking (en particulier les variantes Heavy) et certaines configurations Grok-4 se situent actuellement au sommet ou presque, avec Gemini 3 Deep Think tout près derrière et GPT-5 Pro un peu plus bas.
Mais HLE est compliqué de la meilleure façon possible :
La précision est encore bien inférieure à celle des experts humains.
La confiance est souvent mal calibrée : les modèles peuvent être très sûr et très faux.
Meilleur quand vous le souhaitez profondeur maximale et sont à l'aise de payer en jetons et en temps de latence pour optimiser leurs performances.
Grok-4.1
Brille planification et raisonnement semblable à celui d'un agent; si vos tâches ressemblent à des simulations ou à des décisions commerciales en plusieurs étapes, Grok se sent tout à fait naturel.
GPT-5.1 Réflexion
Une valeur par défaut robuste et sûre : excellente lecture du contexte long, structure généralement propre et intégration très facile dans les systèmes existants.
Gemini 3 (Pro + Deep Think)
Particulièrement convaincant sur raisonnement multimodal, compréhension structurée de la lecture, et planification — et l'argumentaire « Planifiez n'importe quoi » n'est pas qu'une question de marketing ; il se reflète dans la façon dont il gère des problèmes longs et complexes.
Il n'y a pas de gagnant unique pour le dernier examen de l'humanité. Le « meilleur » modèle est celui qui échoue le moins mal sur vos tâches réelles, en fonction de vos contraintes réelles.
10. Comment nous l'avons géré via TrueFoundry AI Gateway
Sous le capot, nous n'avons pas créé quatre intégrations distinctes. Tout est passé par Passerelle TrueFoundry AI (truefoundry.com/ai-gateway) :
Un seul point final pour OpenAI (GPT-5.1), Google (Gemini 3), xAI (GROK-4.x), Moonshot (Kimi-K2) et des centaines d'autres modèles.
Centralisé observabilité: enregistre les invites, les réponses, les jetons, la latence et les erreurs entre les fournisseurs.
Intégré gouvernance et sécurité: RBAC, journaux d'audit et options de déploiement qui conservent les données dans votre cloud ou sur site.
Sur le plan de l'expérimentation, cela signifiait :
Nous avons connecté notre harnais d'évaluation une fois au Gateway.
Nous avons enregistré gpt-5.1-thinking, kimi-k2-thinking, grok-4.1, gemini-3-pro et gemini-3-deep-think comme juste différents numéros de modèle.
L'échange entre les deux était un changement de configuration en une ligne, et non une nouvelle intégration du SDK.
11. Essayez Gemini 3 (et les autres) lors de votre « dernier examen »
Si vous souhaitez reproduire (ou défier) les modèles de cet article :
Choisissez votre examen.
Utilisez HLE ou un « dernier examen » interne créé à partir de votre propre domaine : questions de recherche, tickets d'assistance, révisions de code, analyses d'incidents.
Exécutez-le sur plusieurs modèles.
Dirigez votre harnais d'évaluation vers la passerelle TrueFoundry AI et exécutez les mêmes instructions sur Gemini 3, Kimi-K2 Thinking, Grok-4.1 et GPT-5.1 Thinking.
Comparez en un seul endroit.
Examinez côte à côte l'exactitude, la qualité du raisonnement, l'utilisation des jetons, la latence et les coûts.
Décidez sur quel modèle de « pensée » mérite réellement sa note votre tâches.
Parce qu'en 2025, le seul critère qui compte vraiment n'est pas le HLE, le MMLU ou le GPQA, mais l'examen qui ressemble à votre propre travail. Et vous n'avez pas à choisir un seul modèle sur la foi quand vous pouvez en câbler quatre derrière un gateway et laissez les résultats parler d'eux-mêmes.
Questions fréquemment posées
Quelle est la différence entre Kimi K2 et Gemini 3 ?
Gemini 3 de Google met l'accent sur la compréhension multimodale et de solides capacités d'appel d'outils grâce à un mode Deep Think. La pensée Kimi-K2, un modèle à poids ouvert, est connue pour son contexte long et étendu et son raisonnement détaillé en chaîne de pensée. Comprendre Kimi K2 par rapport à Gemini 3 révèle des approches distinctes pour la résolution avancée de problèmes liés à l'IA.
À quoi pense le mieux Kimi K2 ?
La méthode Kimi-K2 Thinking est idéale pour les raisonnements complexes et les tâches de résolution de problèmes en profondeur. Grâce à son long contexte et à sa conception complexe, **kimi k2** excelle dans les défis nécessitant un monologue interne approfondi, tels que des problèmes mathématiques avancés et des critères de référence tels que Humanity's Last Exam, qui se classe souvent parmi les meilleurs modèles.
Gemini 3 contre GPT-5 : quel est le meilleur ?
Notre blog explore Gemini 3 par rapport à GPT-5.1 en évaluant leurs performances au dernier examen de l'humanité. Nous avons constaté que le terme « meilleur » dépend de la tâche de raisonnement spécifique et du comportement du modèle. L'analyse de TrueFoundry, menée via notre passerelle IA, met en évidence ses approches uniques de résolution de problèmes, vous aidant à déterminer la solution optimale pour vos solutions d'IA.
Gemini 3 contre Grok-4 : quel modèle est le plus performant ?
Lorsque l'on compare Gemini 3 et Grok-4, les deux excellent en tant que puissants agents de raisonnement, démontrant de solides performances sur des tâches complexes comme le dernier examen de l'humanité. Gemini 3 propose une compréhension multimodale avancée et un mode Deep Think, tandis que Grok-4 se concentre sur l'utilisation d'outils natifs et les capacités agentiques. Les performances optimales dépendent souvent des exigences spécifiques de la tâche.
Quel modèle d'IA convient le mieux aux tâches de raisonnement ?
Pour les tâches de raisonnement complexes, des modèles tels que Gemini 3, Kimi-K2 Thinking et GPT-5.1 démontrent de solides capacités. Notre blog évalue les performances de chacun face à différents défis, vous aidant à comprendre leurs points forts spécifiques. Le choix optimal lorsque vous comparez Gemini 3 à Kimi K2 Thinking à GPT 5 dépend en fin de compte des exigences uniques de votre projet et du type de raisonnement requis.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge





























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


