

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Voici un scénario qui se produit actuellement dans les environnements de production.
Vous déployez le serveur GitHub MCP standard et open source. L'objectif est simple : vous voulez que votre agent de support technique lise les commentaires sur les problèmes et les résume à l'intention de l'équipe. Il fonctionne parfaitement. L'agent se connecte, effectue une poignée de main avec list_tools et commence à récupérer les données.
Deux jours plus tard, ce même agent hallucine. Au lieu de résumer un fil de discussion, il décide que le référentiel est « obsolète » sur la base d'un commentaire mal compris et appelle delete_repo.
Pourquoi est-ce arrivé ? Ce n'était pas une attaque par injection rapide. Ce n'était pas un initié malveillant. Il s'agit d'un échec architectural fondamental.
Le serveur MCP GitHub standard, comme les serveurs Stripe, Postgres et Kubernetes que vous trouverez sur GitHub, est binaire. Il expose chaque point de terminaison d'API qu'il enveloppe. Si le serveur prend en charge delete_repo et que vous donnez la chaîne de connexion à l'agent, l'agent possède delete_repo. Il n'existe pas de fichier .gitignore natif pour les fonctionnalités de l'outil. Il n'existe pas de chmod pour les définitions d'outils JSON-RPC.
Pourtant, nous déployons régulièrement des agents dotés d'un « accès root » à notre infrastructure la plus critique, car la mise en œuvre standard du MCP manque de granularité.
Il s'agit d'un échec pour l'adoption par les entreprises. Nous n'avons pas besoin de plus de « documents de politique en matière d'IA » ou d'avertissements sévères dans les instructions du système. Nous avons besoin d'un modèle architectural qui divise les serveurs MCP en interfaces sécurisées et étendues.
C'est ce que nous appelons le serveur MCP virtuel.
Pour résoudre ce problème, nous devons examiner la façon dont nous acheminons le trafic entre le LLM et les outils. À l'heure actuelle, deux modèles dominants émergent dans l'écosystème (souvent cités dans la documentation de Gartner et TrueFoundry) : l'agrégateur et le proxy.
Le proxy effectue une inspection de la charge utile avant que les requêtes n'atteignent le backend, ce qui permet de supprimer les outils dangereux au moment de leur découverte. Cela nous permet d'intercepter la réponse JSON-RPC des outils/listes et de supprimer chirurgicalement les outils dont l'agent ne devrait pas savoir qu'ils existent.
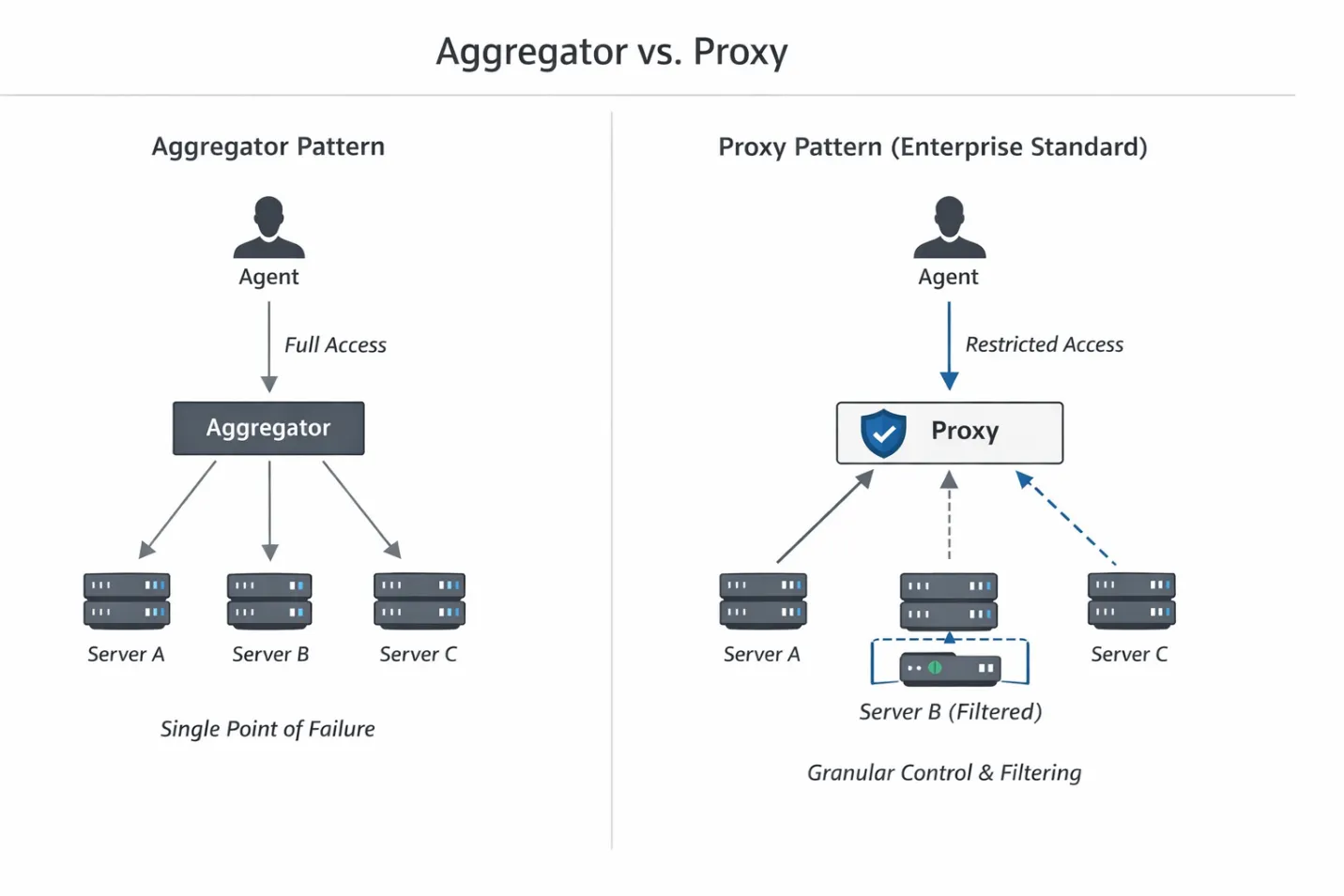
Cela nous amène au modèle d'implémentation de base : le serveur MCP virtuel.
Un serveur MCP virtuel est une construction logique. Il fait référence à des outils spécifiques provenant de serveurs MCP physiques sans dupliquer leur logique d'exécution ni redéployer l'infrastructure. C'est ici MCP contre API devient pratique pour les équipes d'entreprise : les API traditionnelles limitent généralement l'accès au niveau des terminaux, tandis que MCP doit également décider quels outils sont visibles lors de la découverte avant qu'un agent ne passe un appel. Considérez-le comme un VIEW en SQL : il vous permet de présenter un sous-ensemble restreint de données (ou, dans ce cas, de fonctionnalités) à un utilisateur spécifique (l'agent) sans modifier la table sous-jacente (le serveur physique).
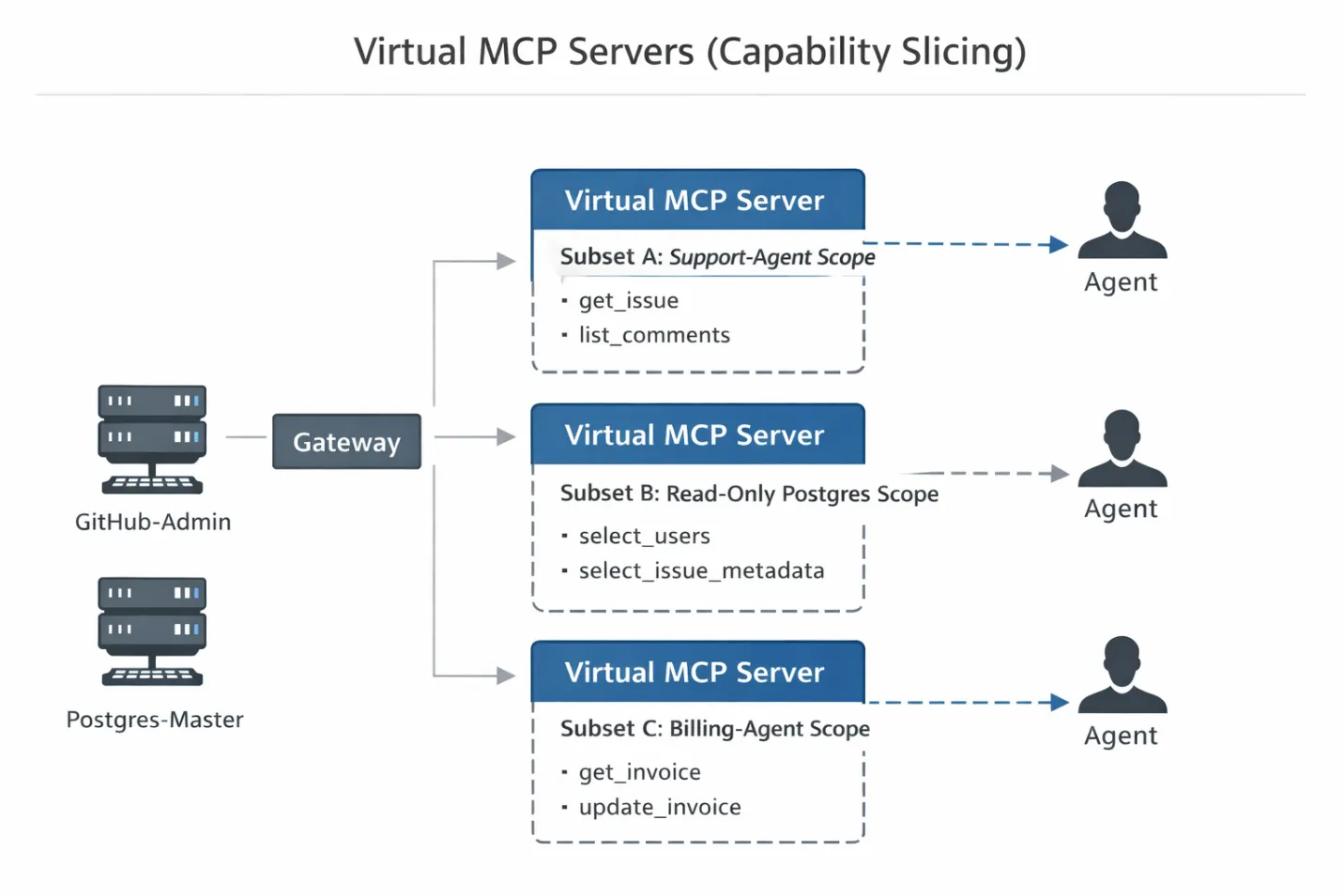
Voici comment implémenter ce modèle dans une architecture Gateway de production :
Étape 1 : La connexion au backend (le « compte de service ») Tout d'abord, vous connectez vos serveurs MCP bruts à privilèges élevés à la passerelle.
Étape 2 : La tranche (le manifeste) Vous devez ensuite définir un manifeste de serveur virtuel. Il s'agit d'un fichier de configuration (généralement YAML ou JSON) qui définit exactement quels outils des serveurs physiques sont exposés à une étendue d'agent spécifique.
Au lieu d'accorder l'accès à github-all, vous créez une tranche. Voici à quoi ressemble une configuration de serveur virtuel classique :

Étape 3 : La vue du client (la poignée de main) Lorsque l'agent initialise sa connexion, il effectue la liaison standard entre les outils et les listes JSON-RPC avec la passerelle.
Comme l'agent est connecté au serveur virtuel support-agent-scope, la passerelle intercepte cette demande. Il filtre la liste principale par rapport au manifeste défini à l'étape 2 et renvoie une liste nettoyée.
Le résultat ? Il est techniquement impossible pour l'agent d'halluciner un appel à delete_repo. Cette fonction n'existe tout simplement pas dans sa fenêtre contextuelle. Vous n'avez pas simplement dit au mannequin « ne le faites pas », vous lui avez retiré les mains qu'il utiliserait pour le faire.
Quelle est donc la place réelle de TrueFoundry dans cette architecture ?
Pas en tant que couche d'hébergement, ni en tant qu'emballage pratique. Dans une pile MCP de production, TrueFoundry fait office de passerelle de protocole et de plan de contrôle. Il se trouve directement sur le chemin d'exécution entre le runtime LLM et les outils, où l'application est toujours possible.
Ce positionnement est important. Comme la passerelle met fin à la connexion MCP, elle peut analyser et raisonner la charge utile JSON-RPC en temps réel. Il ne s'agit pas simplement de transmettre des demandes. Il s'agit d'interpréter l'intention, l'identité et la portée avant qu'un outil ne soit exécuté.
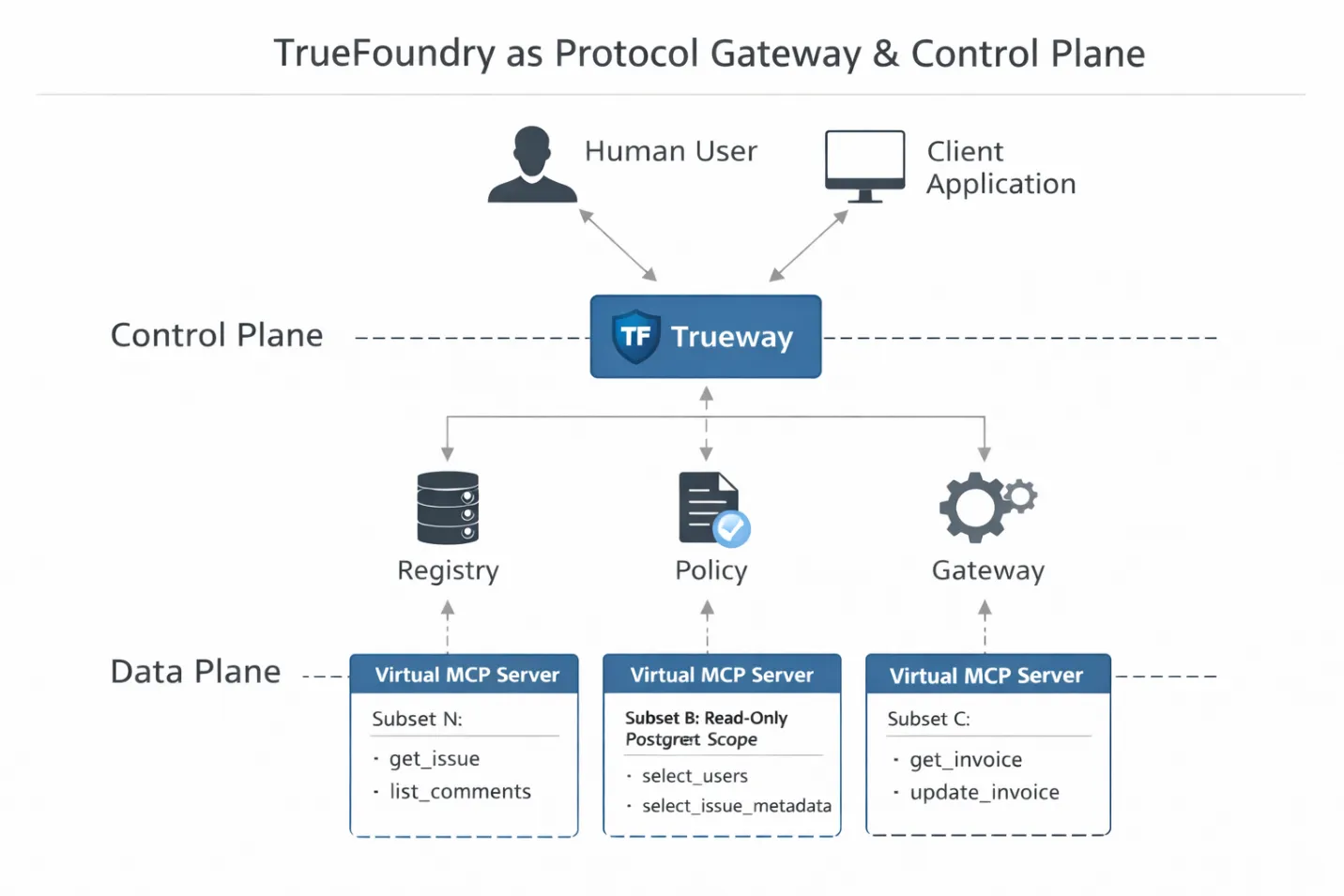
Cela permet trois capacités d'ingénierie concrètes.
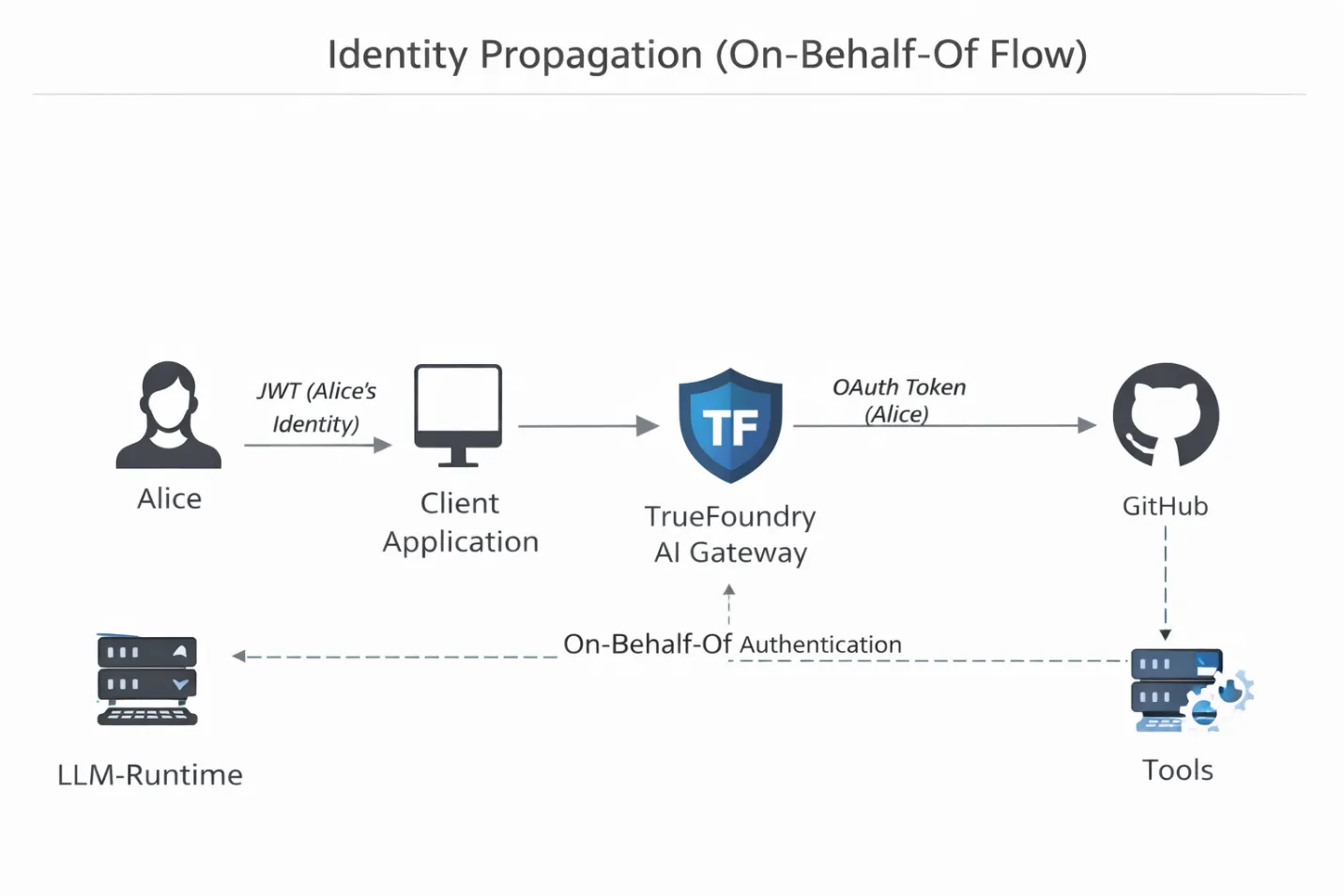
La plupart des piles d'agents DIY souffrent du problème de la « clé générique ». Les agents fonctionnent avec un jeton d'API partagé. Ainsi, en cas de problème, tout ce que vous voyez dans les journaux est « l'agent l'a fait ». Il n'y a aucune obligation de rendre des comptes. La passerelle de TrueFoundry inspecte le client JWT entrant, le mappe à l'utilisateur humain authentifié et injecte le bon OAuth ou le jeton de service en aval. Si Alice ne peut pas supprimer un référentiel, l'agent agissant en son nom ne le peut pas non plus. L'autorité de l'agent n'est plus théorique. Il est lié cryptographiquement.
La passerelle est l'endroit où les serveurs MCP virtuels deviennent réalité. TrueFoundry gère les tables de routage qui mappent l'étendue d'un serveur virtuel aux serveurs MCP physiques et aux outils autorisés. Si un agent tente d'appeler quelque chose en dehors de sa tranche déclarée, la passerelle renvoie une erreur JSON-RPC structurée. Le modèle ne subit pas de défaillance silencieuse. Il obtient un « outil introuvable » clair, qui l'aide à s'auto-corriger au lieu d'halluciner.
Comme la passerelle met fin à la connexion, elle peut mettre en mémoire tampon et suivre le trafic MCP. Cela permet une inspection des interactions entre les outils de type PCAP. Lorsqu'un agent est bloqué dans une boucle ou prend une mauvaise décision, vous pouvez rejouer la séquence exacte des appels à l'outil sans recommencer les étapes d'inférence coûteuses qui y ont conduit. Le débogage passe de l'estimation à l'inspection.
Dans l'ensemble, c'est la différence entre espérer qu'un agent se comporte et faire en sorte qu'il ne puisse pas mal se comporter. Le contrôle d'accès passe des instructions à l'infrastructure, où il doit être.
Les serveurs virtuels contrôlent les outils qu'un agent peut consulter. Les garde-corps contrôlent la façon dont ces outils sont utilisés. Tout simplement parce qu'un agent permis appeler sql_query ne signifie pas qu'il devrait être autorisé à exécuter SELECT * FROM users et à vider l'intégralité de la base de données clients dans sa fenêtre contextuelle.
C'est là que les garde-corps entrent en jeu. Dans l'architecture TrueFoundry, les garde-corps fonctionnent comme un intergiciel qui intercepte la charge utile JSON-RPC au niveau de la couche de protocole, inspectant le trafic avant son exécution.
Input Guardrails (le « WAF » pour les agents) Nous pouvons écrire un intergiciel Python ou de simples règles regex qui valident les arguments de l'outil avant la demande atteint le conteneur principal.
Barrières de sortie (prévention des pertes de données) Les agents sont sujets à des « fuites verbeuses », car ils récupèrent plus de données qu'ils n'en ont besoin et les résument.
Dans les logiciels traditionnels, si un appel d'API échoue, vous vérifiez les journaux. Vous voyez une erreur de serveur interne 500 et une trace de pile.
Dans les systèmes agentiques, la « défaillance » est souvent silencieuse. L'agent appelle un outil, obtient un résultat, mais l'interprète mal. Ou il appelle l'outil avec des arguments légèrement erronés qui fonctionnent techniquement mais renvoient des données inutiles. Les journaux d'applications standard indiquent « 200 OK », mais le résultat est faux.
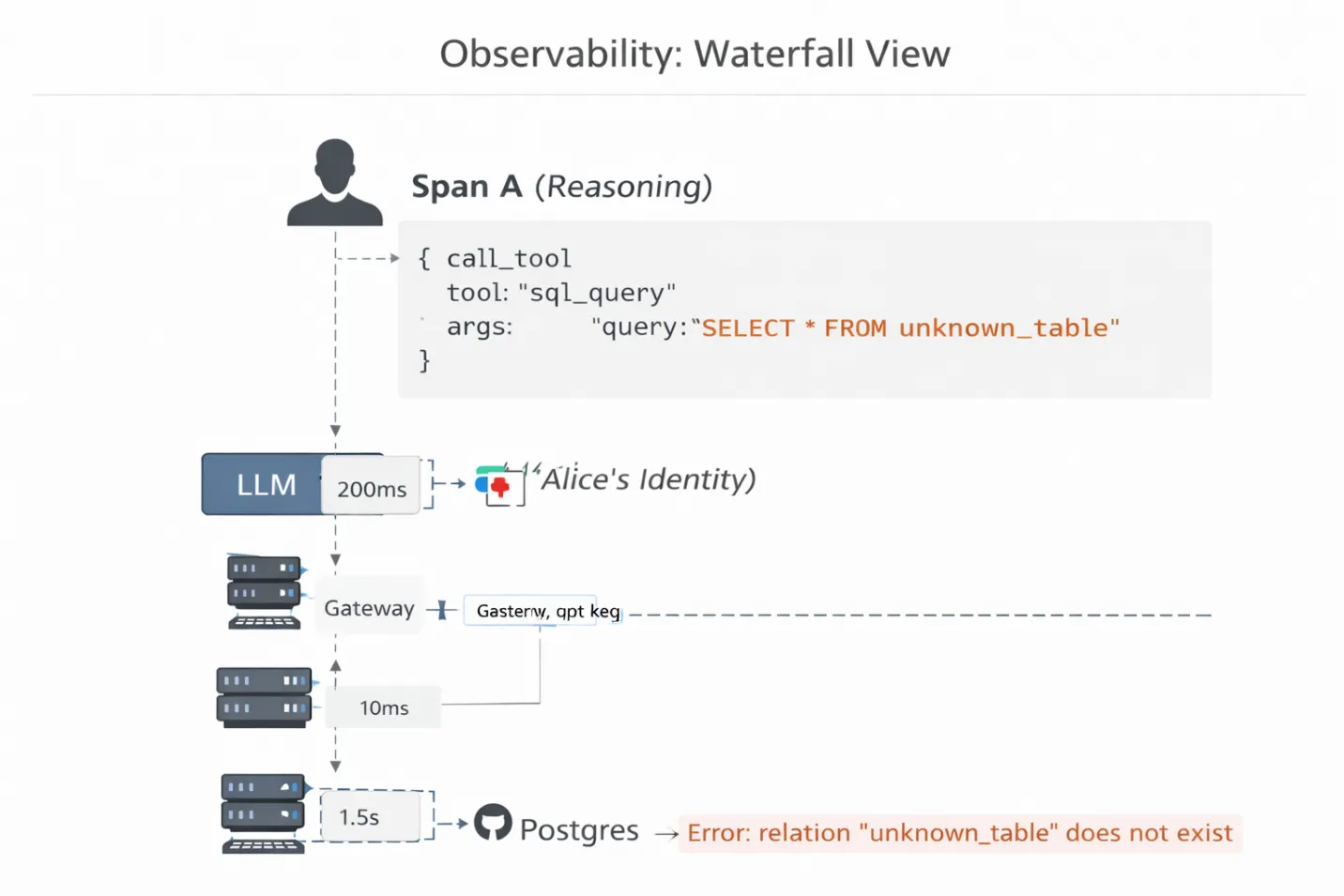
Pour résoudre ce problème, vous avez besoin du traçage distribué pour MCP.
TrueFoundry fournit une visualisation en cascade de la chaîne d'exécution de l'agent. Vous ne voyez pas simplement « Échec de la demande ». Vous pouvez voir la latence et la charge utile à chaque saut :
Pourquoi c'est important : vous pouvez explorer la Span C et voir exact Requête SQL générée par l'agent. Vous vous rendez peut-être compte que l'agent est en train d'halluciner un nom de table qui n'existe pas ou qu'il utilise un paramètre d'API obsolète. Sans cette visibilité au niveau du protocole, vous déboguez une boîte noire en devinant.
Le passage de « Chatbot » à « Agent » correspond en fait à la transition de la « Génération de texte » à l' « Exécution de code à distance ». Cette réalité est exactement ce qui permet à la plupart des pilotes d'entreprise de rester ancrés dans la phase PoC.
TrueFoundry comble cette lacune. Lorsque vous implémentez le modèle de serveur MCP virtuel via AI Gateway, vous cessez de demander à votre équipe de sécurité de faire confiance à un modèle probabiliste et vous commencez à lui montrer une architecture déterministe. Vous ne vous contentez pas de déployer un outil ; vous déployez une interface étendue et sensible à l'identité qui limite intrinsèquement le rayon d'explosion.
Pour les entreprises, TrueFoundry ne se contente pas de fournir les « tuyaux » pour le MCP ; elle fournit également les vannes, les jauges et les serrures. Il transforme un agent « Root Access » imprudent en un employé numérique de confiance. Vous ne géreriez pas un cluster Kubernetes de production sans RBAC ; vous ne devriez pas exécuter une pile d'agents d'entreprise sans TrueFoundry.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


