

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans le monde de l'apprentissage automatique (ML), la création efficace d'images Docker n'est pas qu'un luxe, c'est une nécessité. La plupart des entreprises disposent d'un pipeline Devops pour créer et diffuser des images Docker, soit sur un ordinateur portable local, soit via des pipelines CI/CD. Cependant, à mesure que les projets de machine learning gagnent en complexité, avec des dépendances de plus en plus importantes et des itérations plus fréquentes, le processus de création traditionnel de Docker peut devenir un goulot d'étranglement important.
.webp)
Cet article explique comment nous avons réduit le temps de construction dans Truefoundry de 5 à 15 fois par rapport aux pipelines CI standard.
Les projets de machine learning impliquent généralement de nombreuses dépendances importantes : frameworks d'apprentissage en profondeur (PyTorch, TensorFlow), bibliothèques de calcul scientifique (NumPy, SciPy), pilotes GPU et boîtes à outils CUDA. Ces dépendances peuvent entraîner la taille des images Docker de plusieurs gigaoctets, ce qui entraîne des temps de génération longs.
Le développement du machine learning implique de fréquentes modifications de code qui doivent être déployées afin de les tester. Les spécialistes des données ne disposent souvent pas du matériel nécessaire pour exécuter leur code sur leurs ordinateurs portables locaux, ce qui signifie que le code doit être exécuté sur le cluster distant, ce qui implique souvent la création d'images.
Chez Truefoundry, notre objectif est de permettre aux développeurs d'évoluer à un rythme d'itération rapide et pour cela, nous voulions rendre nos versions Docker très rapides. Pour comprendre ce que nous avons fait pour optimiser les temps de génération, voyons d'abord comment nous avions l'habitude de créer des images plus tôt sur Truefoundry.
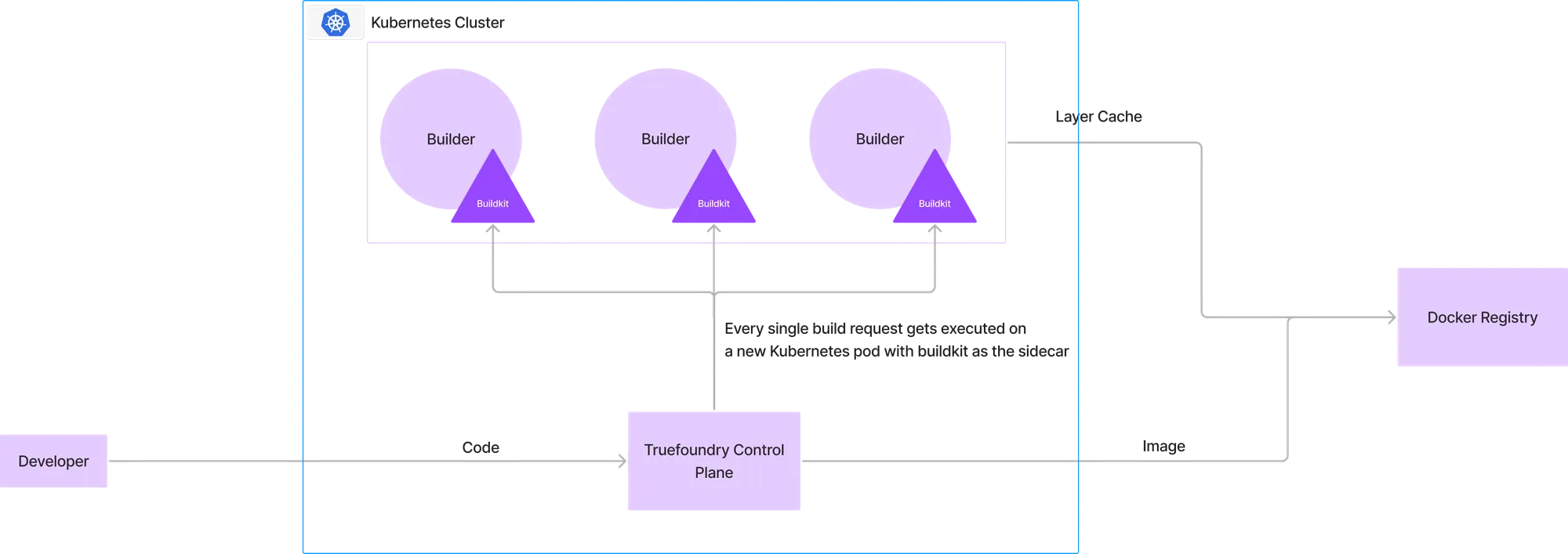
Chaque fois qu'un développeur souhaitait créer une image, le code était chargé sur le plan de contrôle, dans lequel un nouveau module commençait à créer l'image avec buildkit exécuté dans le sidecar. Le registre Docker de destination servira de couche de mise en cache et l'image finale sera transmise au registre Docker.
Cette configuration est identique à la plupart des constructeurs de CI et présente les mêmes avantages et inconvénients que les configurations CI actuelles
Cela présentait les avantages suivants :
Cette approche présentait toutefois quelques inconvénients :
1. Le pod buildkit nécessite un grand nombre de ressources, ce qui entraîne un temps de démarrage élevé pour le build runner.
2. Le téléchargement du cache à partir du registre Docker prend beaucoup de temps, ce qui ralentit les temps de construction.
3. Il n'est pas possible de réutiliser le cache entre les versions de différentes charges de travail.
Nous voulions offrir la même expérience (et peut-être meilleure) en matière d'images de bâtiments à distance par rapport aux constructions locales
Nous avons décidé d'héberger d'abord le pod buildkit en tant que service sur Kubernetes qui peut être partagé entre plusieurs constructeurs et qui peut fournir une mise en cache sur disque locale afin que les builds de Docker puissent être très rapides.
Cette approche présente toutefois quelques contraintes :
1. Buildkit a une contrainte fondamentale selon laquelle le système de fichiers cache ne peut être utilisé que par une seule instance de Buildkit. Cela signifie que si nous exécutons plusieurs instances du buildkit pour traiter plusieurs versions en parallèle, chacune d'elles aura son propre cache et celui-ci ne pourra pas être partagé.
2. Si nous exécutons plusieurs instances de buildkit, chacune ayant son propre cache, la même charge de travail doit être acheminée vers la même machine afin que le cache puisse être utilisé efficacement. Cela nécessite une logique de routage personnalisée.
3. La mise à l'échelle automatique des pods buildkit en fonction du nombre de builds en cours d'exécution n'est pas triviale. Nous ne pouvons pas utiliser l'utilisation du processeur des pods buildkit comme métrique de mise à l'échelle automatique, car il est possible que Kubernetes mette fin à une petite version en cours d'exécution en supposant que rien ne fonctionne sur cette machine.
Le fait d'avoir un nombre dynamique de pods buildkit dont les charges de travail sont acheminées vers la même instance de cache est un problème non négligeable. L'attachement et la suppression de volumes entre les pods sont assez lents dans Kubernetes, ce qui entraîne des délais de démarrage très longs.
Pour surmonter les contraintes ci-dessus, nous avons mis au point une approche hybride qui permet de terminer la plupart des builds très rapidement, tandis que dans de rares cas de forte simultanéité de builds parallèles, nous avons recours à notre méthode précédente qui consistait à exécuter buildkit dans un sidecar.
Dans l'architecture décrite dans l'image ci-dessous, nous configurons une certaine simultanéité de construction en dessous de laquelle toutes les versions seront envoyées au service buildkit. Pour illustrer cela, considérons que nous allouons une machine avec 4 processeurs et 16 Go de RAM au service buildkit. À partir des données de construction historiques, nous pouvons déterminer que cette machine peut gérer 2 versions simultanées. Donc, s'il y a une version déjà en cours d'exécution et qu'une nouvelle arrive, elle est acheminée vers le service buildkit. Cependant, si une autre version arrive, nous l'acheminerons vers le modèle précédent qui utilise le cache de couches stocké dans le registre Docker et exécute buildkit en tant que sidecar.
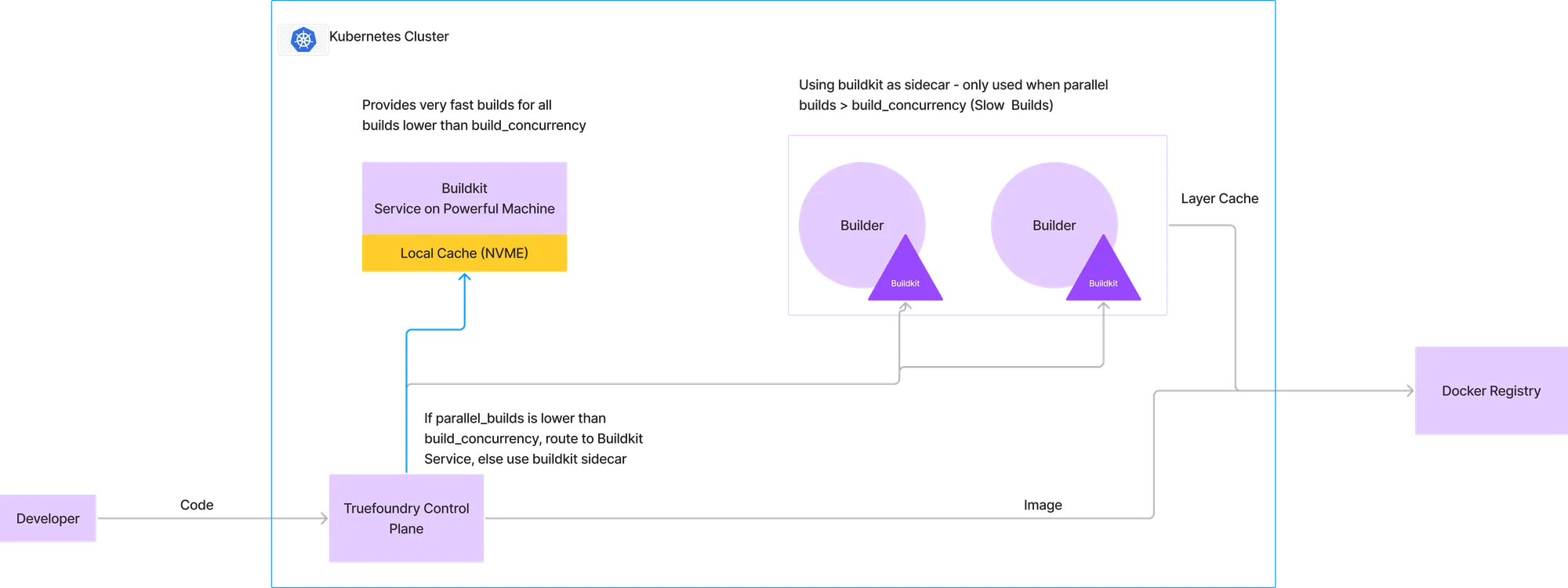
Cela nous permet de fournir des builds ultra-rapides pour 99 % des charges de travail, alors que dans de très rares cas, la construction finit par prendre le temps qu'il faut habituellement dans les pipelines CI standard.
Nous avons apporté quelques autres améliorations au processus de création pour le rendre plus rapide. Quelques-uns d'entre eux sont les suivants :
Pour comparer nos expériences, nous avons prélevé un échantillon de Dockerfile qui représente le scénario le plus courant pour les charges de travail de machine learning.
DEPUIS tfy.jfrog.io/tfy-mirror/python:3.10.2-slim
WORKDIR/app
RUN echo « Démarrage de la construction »
COPIE. /requirements.txt /app/requirements.txt
EXÉCUTEZ pip install -r requirements.txt
COPIE. /application/
EXPOSER 8000
CMD ["uvicorn », « app : app », « --host », « 0.0.0.0", « --port », « 8000 »]
Le fichier requirements.txt est le suivant :
fastapi [standard] ==0.109.1
Huggingfacehub = 0.24.6
vllm=0,5.4
transformateurs ==4.43.3
Nous avons comparé la version pour 3 scénarios :
Les chronométrages incluent le temps nécessaire pour créer et envoyer l'image vers le registre et l'unité est exprimée en secondes.
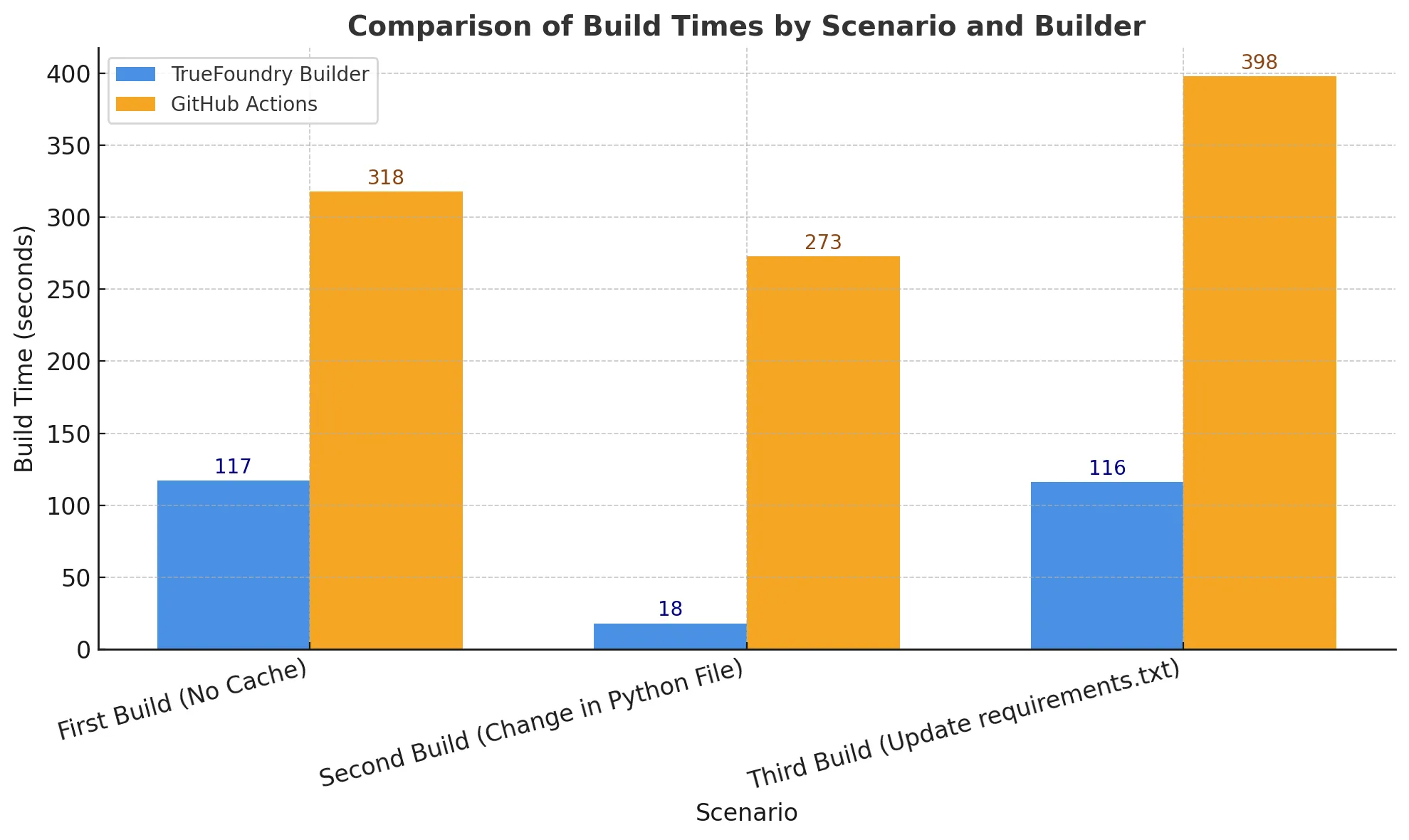
Le deuxième scénario avec uniquement des modifications de code est le scénario le plus courant rencontré par les développeurs et, comme nous pouvons le voir, il s'agit d'une amélioration de près de 15 fois des temps de construction.
Nous avons également comparé un scénario avec un fichier docker contenant du triton comme image de base, qui est une image de base beaucoup plus grande.
DEPUIS nvcr.io/nvidia/tritonserver:24.09-py3
WORKDIR/app
RUN echo « Démarrage de la construction »
COPIE. /requirements2.txt /app/requirements.txt
EXÉCUTEZ pip install -r requirements.txt
RUN echo « La construction est terminée »
Les résultats sont les suivants :
.webp)
Dans ce cas, nous constatons une amélioration du temps de construction multipliée par 3 pour la première version et une amélioration par 9 pour les versions suivantes.
Les changements mentionnés ci-dessus ont considérablement amélioré l'expérience des développeurs et leur ont permis d'itérer très rapidement leurs idées tout en maintenant la même chose avec la manière dont les choses seront finalement déployées en production.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


