

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans mon dernier emploi, nous avions l'habitude de créer des systèmes de recommandation de produits pour les entreprises de commerce électronique, ce qui signifie que nos API étaient disponibles sur chaque page de leur site Web. Nous avons eu un nouveau client, notre première offre à 7 chiffres et nous étions si prudents à son égard que nous l'avons initialement intégré en mars avec des recommandations basées sur des règles. Nous ne voulions pas risquer une mauvaise expérience utilisateur avec nos nouveaux modèles d'apprentissage automatique.
Plus tard en avril, nous avons élaboré des modèles d'apprentissage automatique et effectué de nombreux tests hors ligne et effectué de nombreux tests d'assurance qualité manuels. Enfin, nous étions convaincus que notre modèle fonctionnerait bien. Nous l'avons ensuite lancé et deux choses se sont produites :
Dans l'ensemble, cela s'est traduit par de nombreux efforts de lutte contre les incendies, une perte de crédibilité importante et une quasi-perte de client. Lors de notre rétrospective interne ultérieure, nous avons réalisé que si #1 n'était qu'un échec manuel, il était presque impossible de détecter des problèmes tels que #2 hors ligne. Depuis, nous sommes passés au bon côté des lancements dans l'obscurité !
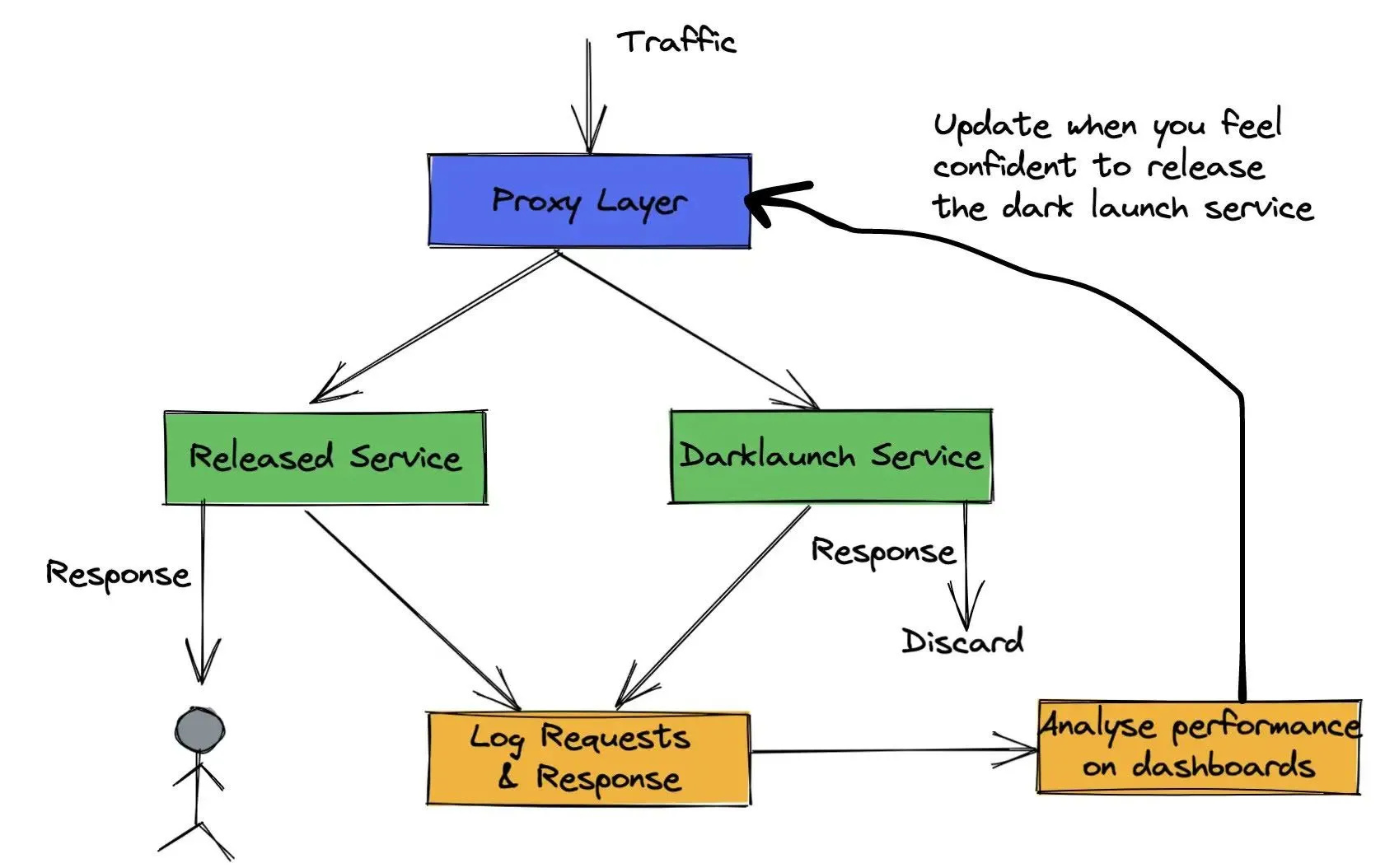
Dark Launch est une stratégie de déploiement qui vous permet de retransmettre votre trafic de production réel à votre service nouvellement déployé et d'ignorer la réponse avant de la renvoyer à l'utilisateur. Il se comporte comme si le service était réellement actif mais n'affecte en rien les utilisateurs. Cela vous permet de vérifier que votre nouveau service ne comporte aucune erreur, qu'il présente des performances comparables ou supérieures à celles de votre ancien service et qu'il peut gérer la charge de production. Une fois que tout cela est vérifié, il est presque facile de passer progressivement à votre nouveau service. Donc, d'une certaine manière,
Dark Launch est un moyen léger de lancer vos services.
avec des inconvénients très minimes et un énorme potentiel de hausse.
Le lancement de vos services dans le noir est l'un des moyens réalistes de tester vos services et modèles sur un système similaire à celui de la production. Mais l'exécution de Dark Launch peut nécessiter beaucoup de configuration et de maturité au sein de l'organisation du point de vue du développement, de la surveillance et de l'infrastructure.
Les tests hors ligne vous permettent de vérifier comportement de votre système, généralement de manière isolée. Cela vous permettrait rarement de tester le système de bout en bout ainsi que l'état de système environnant avec un trafic réaliste et des paramètres réseau tels que la production? Vous pouvez atteindre 70 % de tout cela grâce à une journalisation méticuleuse et à des tests hors ligne très compliqués, mais Dark Launch s'avère être un système beaucoup plus simple. En effet, vous finissez de toute façon par effectuer la plupart des étapes ci-dessus pour lancer et surveiller un service normalement. Une fois que vous avez effectué un lancement réussi dans le dark, la sortie effective du nouveau service est presque insignifiante, donc le ratio effort-récompense en vaut la peine.
Dans certains cas, cela peut être difficile à justifier dans la pratique. Par exemple, si votre service est dynamique ou s'il modifie réellement la base de données alors faire un lancement dans le noir est beaucoup plus compliqué. D'après mon expérience personnelle, il est si difficile de s'assurer de l'exactitude du système qu'il est Il vaut mieux se contenter de tests hors ligne plutôt que Dark Launch !
Si vous êtes plus curieux de découvrir les lancements dans le noir ou si vous souhaitez partager certaines de vos expériences, contactez-moi à l'adresse nikunj@truefoundry.com !
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


