

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Il n'est pas faux de dire que chaque entreprise doit gérer plus de trafic, traiter plus de données et prendre en charge un plus grand nombre de clients au fur et à mesure de sa croissance. Ils ont souvent besoin de faire évoluer leur infrastructure pour répondre à la demande croissante. Cela est également vrai si votre entreprise est saisonnière. Imaginez un site Web de commerce électronique qui enregistre beaucoup de trafic pendant les fêtes, comme le Black Friday ou le Cyber Monday. Le trafic du site Web peut augmenter considérablement pendant ces périodes de pointe. Le site Web peut avoir des problèmes de chargement des pages retardé et irriter les utilisateurs s'il ne peut pas gérer la demande accrue. En conséquence, l'entreprise peut subir des pertes de ventes et une détérioration de sa réputation.
L'un des moyens de résoudre ce problème consiste à augmenter manuellement le nombre de serveurs de l'infrastructure pour gérer l'augmentation du trafic. Cependant, la mise à l'échelle manuelle vers le haut et vers le bas peut prendre beaucoup de temps, être source d'erreurs et difficile à gérer. C'est là qu'intervient la mise à l'échelle automatique des clusters. La mise à l'échelle automatique du cluster ajuste automatiquement le nombre de serveurs de l'infrastructure en fonction de certaines conditions, telles que l'utilisation du processeur, l'utilisation de la mémoire ou les demandes entrantes. Cela signifie que l'infrastructure peut être agrandie ou réduite en fonction de la demande actuelle sans intervention manuelle.
Cet article de blog explique ce qu'est la mise à l'échelle automatique des clusters, pourquoi elle est nécessaire et comment elle peut être mise en œuvre chez différents fournisseurs de cloud.
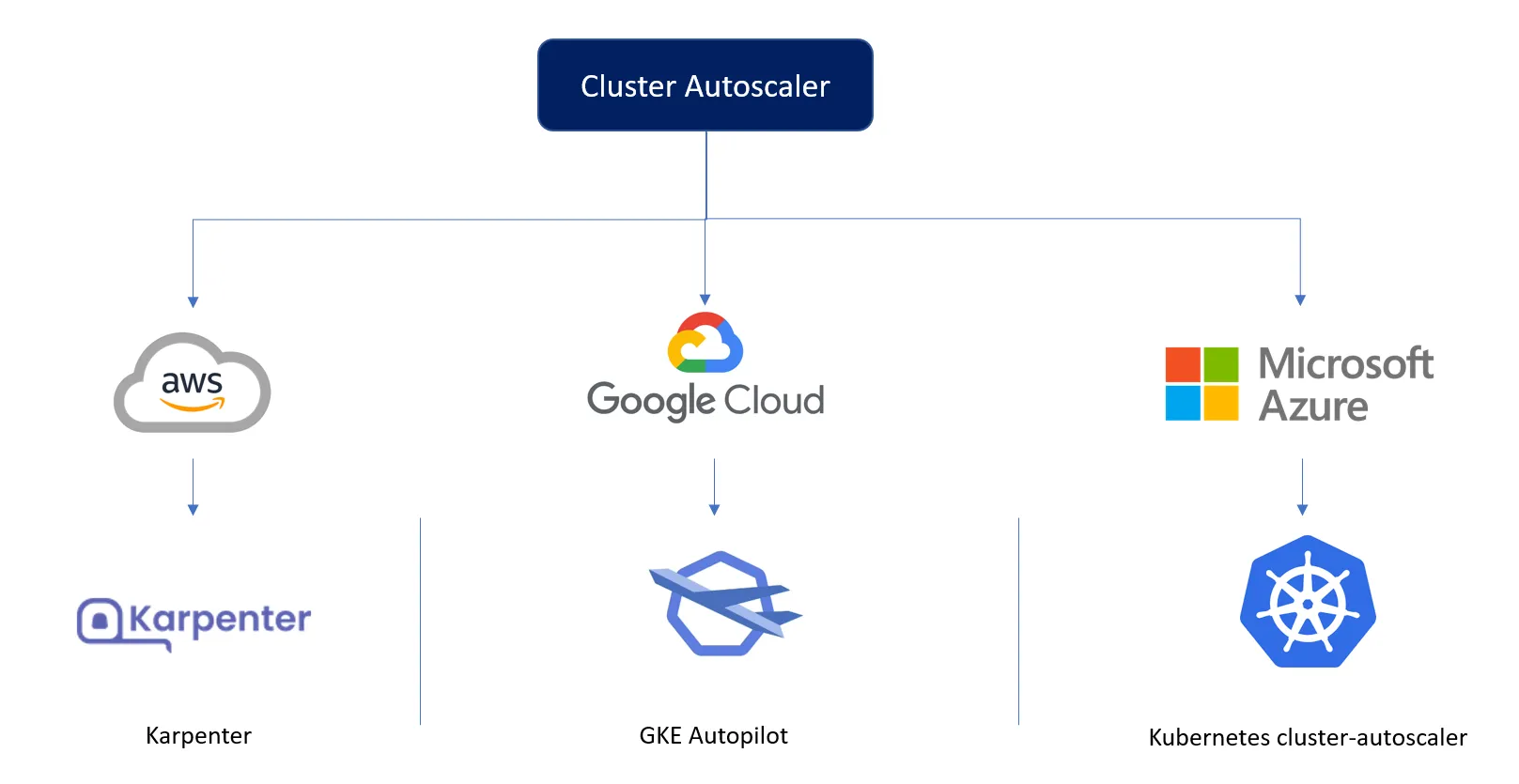
Pour que notre cluster fonctionne correctement sur tous les principaux fournisseurs de cloud, nous devons adapter la manière dont nous dimensionnons les nœuds du cluster.
💡
Sur AWS, nous utilisons Karpenter, qui, avec une configuration minimale, peut choisir le nœud le moins cher et le plus efficace pour les demandes de pod entrantes.
💡
Sur GCP, nous nous appuyons sur GKE Autopilot, qui nous fournit un cluster géré capable d'évoluer vers le haut et vers le bas en fonction des demandes.
💡
Il n'existe aucune solution ad hoc sur Azure et nous utilisons le cluster-autoscaler Kubernetes, qui est moins optimisé que Karpenter et nécessite plus de configuration que le pilote automatique.
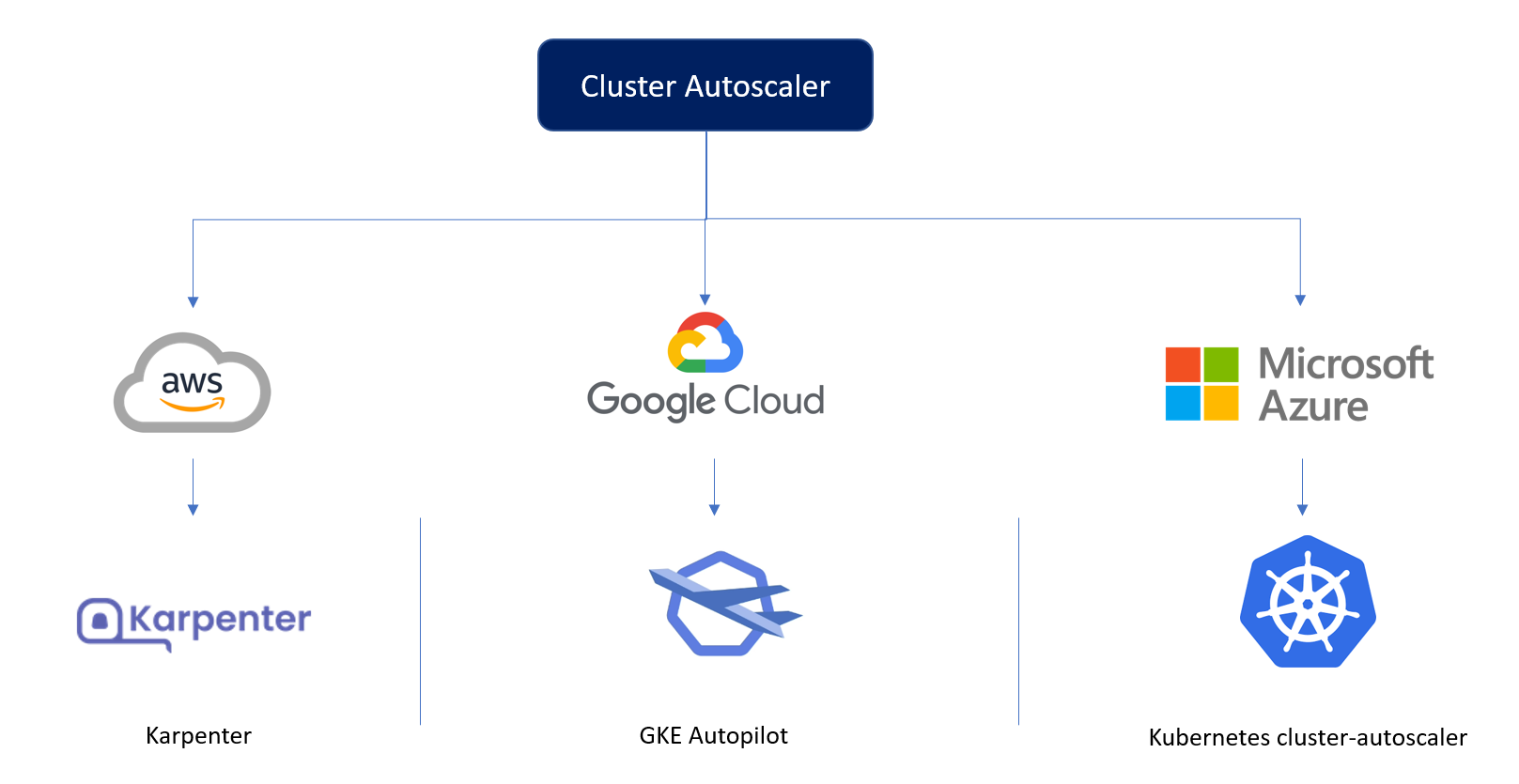
Karpenter observe les demandes de ressources agrégées des pods non planifiés et prend la décision de lancer et de terminer les nœuds afin de minimiser les latences de planification et les coûts d'infrastructure.
Mais malheureusement, Karpenter ne fonctionne que sur AWS.
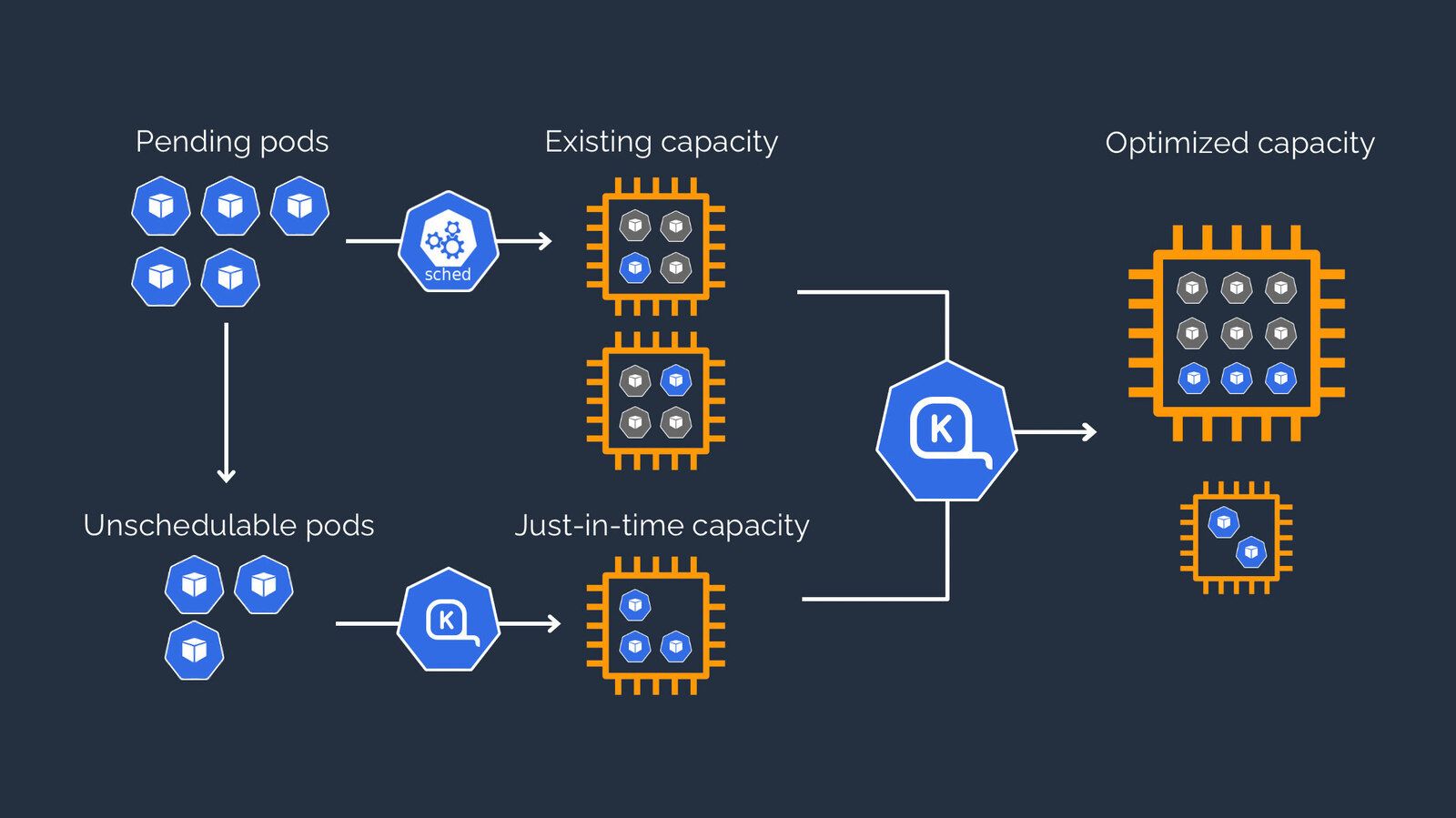
Le pilote automatique est un service géré qui utilise des algorithmes d'apprentissage automatique pour déterminer le nombre optimal de nœuds pour le cluster en fonction de la charge de travail actuelle. Il fournit également des fonctionnalités telles que des mises à niveau et des correctifs automatiques, ce qui facilite la mise à jour et la sécurité du cluster.
Outre la mise à l'échelle automatique, Cluster Autopilot offre également d'autres avantages, tels qu'une meilleure utilisation des ressources et des économies de coûts en évitant le surprovisionnement des ressources. Il propose également une approche plus directe de la gestion des clusters, car toutes les opérations de dimensionnement automatique sont gérées par le service.
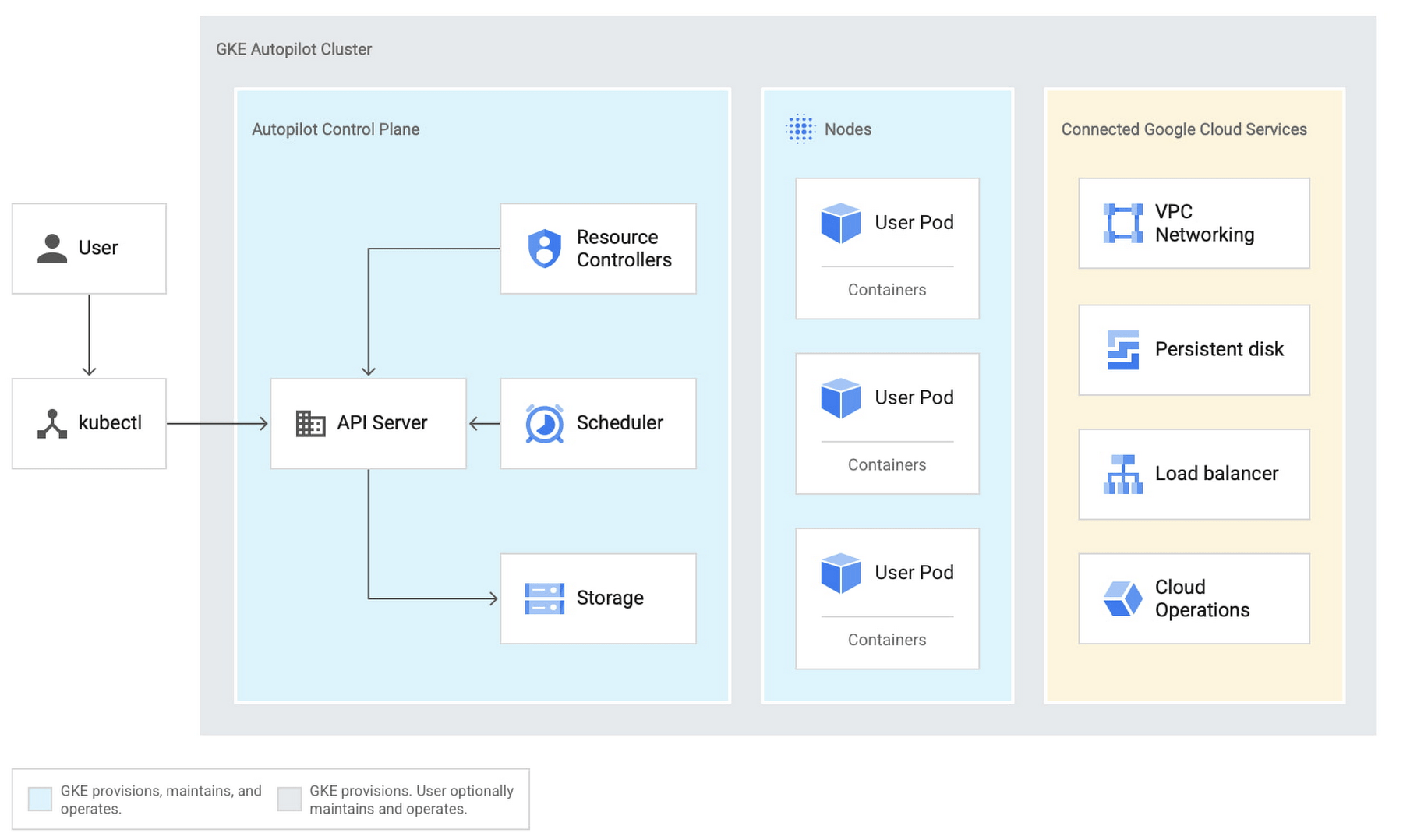
Il n'existe pas d'offre gérée sur le cloud Azure, comme GKE Autopilot, ni d'approche personnalisée de la mise à l'échelle automatique comme Karpenter ; c'est pourquoi nous nous appuyons sur Cluster-Autoscaler.
Kubernetes Cluster Autoscaler est un outil open source qui permet la mise à l'échelle automatique des clusters Kubernetes. Il s'exécute en tant que module au sein du cluster et surveille l'utilisation des ressources du cluster, en ajustant le nombre de nœuds nécessaires pour répondre aux besoins des applications qui y sont exécutées. Cela permet d'optimiser l'utilisation des ressources et de réduire les coûts en évitant le surapprovisionnement des ressources lorsque la demande est faible. Cluster Autoscaler nécessite une configuration manuelle des groupes et des types de nœuds.
Ce Ce blog fournit des informations sur Kubernetes Autoscaling.
True Foundry est un PaaS de déploiement de machine learning sur Kubernetes destiné à accélérer les flux de travail des développeurs tout en leur offrant une flexibilité totale dans les tests et le déploiement de modèles, tout en garantissant une sécurité et un contrôle complets à l'équipe Infra. Grâce à notre plateforme, nous permettons aux équipes de machine learning de déployer et surveiller des modèles en 15 minutes avec une fiabilité à 100 %, une évolutivité et la possibilité de revenir en arrière en quelques secondes, ce qui leur permet de réduire les coûts et de mettre les modèles en production plus rapidement, ce qui permet de réaliser une véritable valeur commerciale.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


