

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: July 12, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
L'IA évolue rapidement en 2026. Trop vite. Les modèles s'accélèrent chaque trimestre. De nouveaux fournisseurs apparaissent chaque semaine. Les prix fluctuent comme les cryptomonnaies. Et si vous ne faites pas attention, votre pile d'IA se transforme en un gâchis fragile et coûteux.
C'est pourquoi les équipes les plus intelligentes ne se connectent plus directement aux modèles ; elles gèrent tout via une passerelle LLM. Considérez-le comme votre centre de commande IA : une couche qui unifie les fournisseurs, réduit la latence, assure la conformité et vous offre l'observabilité dont vous avez besoin pour dormir la nuit.
Voici la vérité : la passerelle que vous choisirez décidera de la rapidité avec laquelle vous pouvez expédier, de la fiabilité de vos systèmes et du montant que vous allez payer. Faites le bon choix et vous vous déplacez à la vitesse de la frontière. Choisissez le mauvais choix et vous serez coincé à combattre les incendies.
La vraie question n'est donc pas « Ai-je besoin d'une passerelle LLM ? » C'est « Lequel me portera jusqu'en 2026 ? »
Construire avec l'IA en 2026 ne consiste plus à choisir le meilleur modèle. La réalité est confuse : différents fournisseurs excellent dans différents domaines, les modèles de tarification changent constamment et aucun LLM ne domine tous les cas d'utilisation. Ce qui fonctionne pour le chat aujourd'hui pourrait ne pas être adapté à la génération de code demain. C'est là qu'un Passerelle LLM fait toute la différence.
Une passerelle LLM agit comme une couche intermédiaire intelligente entre vos applications et le monde en évolution rapide des fournisseurs de modèles. Au lieu de connecter votre système directement à chaque API et de faire face à des intégrations personnalisées, à des problèmes de performances ou à des problèmes de dépendance vis-à-vis d'un fournisseur, vous vous connectez à une seule passerelle. À partir de là, vous gagnez en flexibilité, en fiabilité et en contrôle.
Les performances s'améliorent car la passerelle peut automatiquement acheminer les demandes vers l'option la plus rapide ou la plus rentable. L'observabilité est intégrée à des informations en temps réel sur les coûts, la latence et la qualité, souvent alimentées par des Outils d'observabilité LLM. La conformité devient plus facile puisque les normes de gouvernance et de sécurité des données sont appliquées de manière cohérente. Et surtout, les passerelles offrent une garantie d'avenir. Lorsqu'un nouveau modèle ou un nouveau fournisseur arrive, vous pouvez l'adopter instantanément sans avoir à reconstruire votre stack.
En bref, une passerelle LLM permet à votre stratégie d'IA de rester agile. Il vous permet d'expérimenter sans friction, d'évoluer sans problèmes et d'optimiser les coûts sans compromettre les performances.
À mesure que l'adoption de l'IA s'accélère, les véritables gagnants ne seront pas seulement ceux qui utilisent les LLM, mais aussi ceux qui les gèrent avec sagesse. La porte d'entrée est l'endroit où réside cette sagesse.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Toutes les passerelles ne sont pas créées de la même manière. Choisir la bonne solution dépend moins de fonctionnalités sophistiquées que de sa capacité à répondre aux objectifs, à la taille et au flux de travail de votre équipe. Imaginez qu'il s'agit de jeter les bases de votre stack d'IA : le mauvais choix vous ralentira, tandis que le bon alimentera discrètement tout ce que vous construisez.
La première chose à prendre en compte est la performance. Une bonne passerelle doit être capable d'acheminer les demandes de manière intelligente, en équilibrant vitesse, fiabilité et coût sans vous obliger à effectuer une microgestion. La latence et la disponibilité sont importantes, en particulier lorsque vos utilisateurs attendent des réponses en temps réel.
Viennent ensuite l'intégration et la flexibilité. Votre passerelle doit prendre en charge plusieurs fournisseurs, des API ouvertes et une commutation facile. Si cela vous enferme dans un écosystème, vous revenez à votre point de départ : la dépendance vis-à-vis des fournisseurs.
L'observabilité et la surveillance sont tout aussi essentielles. Recherchez des tableaux de bord, un suivi des coûts et des informations sur l'utilisation. Sans eux, vous volerez à l'aveugle et vous aurez du mal à optimiser ou à justifier vos dépenses.
La sécurité et la conformité ne peuvent être considérées comme secondaires. Qu'il s'agisse d'un chiffrement SOC2, du RGPD ou de niveau professionnel, la passerelle doit appliquer des politiques cohérentes à tous les fournisseurs.
Pour résumer, voici les principaux facteurs :
La meilleure passerelle LLM est celle qui disparaît en arrière-plan et vous permet de vous concentrer sur la construction.
Le marché des passerelles LLM se développe rapidement. De nouveaux joueurs font leur entrée, les joueurs les plus connus évoluent et chacun promet d'être la couche la plus intelligente entre vous et le monde des mannequins. Mais elles n'offrent pas toutes la même valeur. Certains mettent l'accent sur la rapidité, d'autres sur le contrôle des coûts, et d'autres encore mettent l'accent sur la conformité des entreprises.
La passerelle qui vous convient dépend de votre cas d'utilisation, qu'il s'agisse de faire évoluer un produit en démarrage, d'exécuter des charges de travail d'entreprise ou d'expérimenter des modèles de pointe. Vous trouverez ci-dessous six des passerelles les plus remarquables en 2026, chacune apportant une touche différente de performances, de flexibilité et de contrôle.
TrueFoundry se distingue comme l'une des principales passerelles LLM en 2026, conçue pour les entreprises qui ont besoin d'une IA prête à la production sans la complexité habituelle. Il combine l'orchestration, la gouvernance et l'évolutivité au sein d'une plateforme unique, ce qui facilite le déploiement, la gestion et l'optimisation des flux de travail LLM à grande échelle.
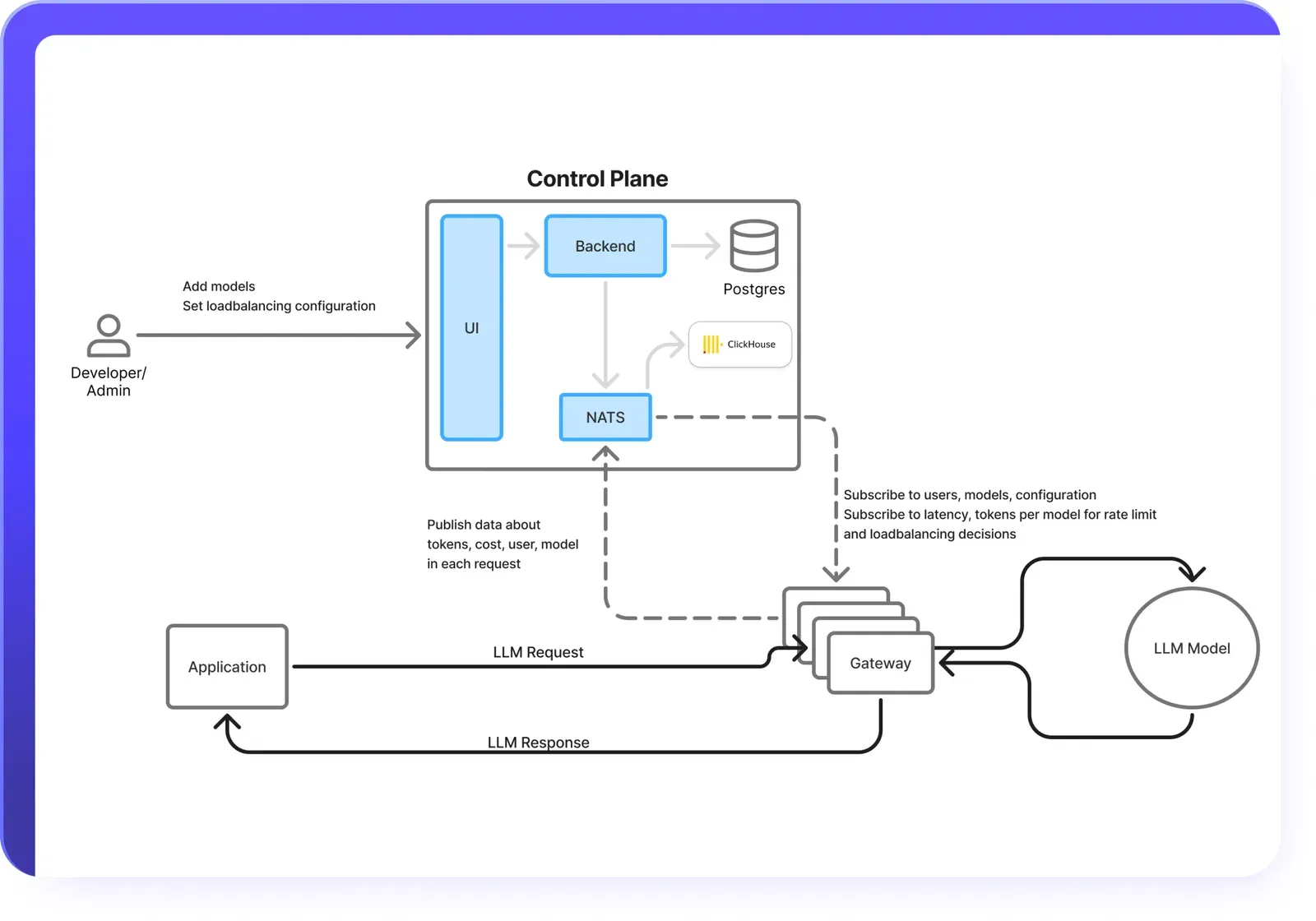
Orchestration intelligente : La passerelle LLM de TrueFoundry coordonne les flux de travail des agents en plusieurs étapes, gère la mémoire, intègre les outils et raisonne entre les tâches. Cela permet aux agents de planifier, d'agir et de s'adapter de manière fluide, tout en offrant aux équipes une visibilité et un contrôle complets.
Outils et gestion rapide du cycle de vie : Avec son MCP et son registre d'agents, TrueFoundry propose une bibliothèque centralisée d'API et d'outils avec validation des schémas et contrôles d'accès. La gestion du cycle de vie rapide ajoute la gestion des versions, les tests et la surveillance, permettant aux entreprises de maintenir un comportement cohérent et vérifiable des agents.
Déploiement flexible du modèle : TrueFoundry prend en charge tous les modèles LLM ou d'intégration, avec des backends optimisés tels que vLLM, TGI et Triton. Il s'intègre également à des frameworks tels que LangGraph, CrewAI et AutoGen, ce qui permet d'affiner les données propriétaires et de déployer des agents personnalisés prêts pour la production.
Conformité et évolutivité à l'échelle de l'entreprise : La plateforme fonctionne dans des environnements VPC sécurisés, sur site, hybrides ou ventilés, conformément aux normes SOC 2, HIPAA et GDPR. L'orchestration des GPU, la prise en charge des processeurs graphiques fractionnés et la mise à l'échelle automatique garantissent la rentabilité, certaines entreprises signalant une utilisation des GPU jusqu'à 80 % supérieure.
TrueFoundry est un choix de premier ordre pour les organisations qui recherchent une passerelle alliant flexibilité, sécurité et efficacité opérationnelle, ce qui en fait la solution idéale pour les déploiements d'IA sérieux.
Helicone est une passerelle d'IA open source conçue pour les développeurs qui recherchent une solution légère et performante pour gérer plusieurs fournisseurs LLM. Construit dans Rust et optimisé pour les déploiements en périphérie, Helicone propose une API unifiée qui simplifie l'intégration et améliore l'observabilité.
API unifiée pour plusieurs modèles : Helicone fournit une API unique qui fonctionne sur des dizaines de LLM, notamment GPT, Claude et Gemini, éliminant ainsi le besoin de plusieurs SDK ou clés.
Routage et basculement intelligents : la passerelle peut changer automatiquement de modèle, optimiser les coûts et équilibrer la charge, garantissant ainsi des performances fiables entre les différents fournisseurs.
Observabilité intégrée : les développeurs bénéficient d'une surveillance en temps réel des demandes et des réponses, de l'utilisation des jetons, de la latence et des coûts via un tableau de bord centralisé.
Limitation de débit personnalisée : les limites de débit spécifiques à l'application permettent un contrôle précis de l'utilisation et des dépenses.
Performances optimisées en périphérie : Helicone est optimisé pour les déploiements en périphérie, minimisant la latence et offrant des frais généraux très faibles, même en cas de forte charge.
Fonctionnalités d'entreprise limitées : Helicone ne dispose pas de contrôles d'accès avancés basés sur les rôles, de journalisation des audits et d'une application stricte des politiques, ce qui peut être nécessaire dans les environnements réglementés.
Support d'intégration de base : bien qu'il prenne en charge plusieurs fournisseurs, il ne propose pas encore d'écosystèmes de modèles étendus ni d'intégrations avancées pour les configurations d'entreprise complexes.
Pour les équipes qui ont besoin de fonctionnalités d'entreprise supplémentaires, telles qu'un contrôle d'accès avancé ou des intégrations plus étendues, envisagez un Alternative à Helicone peut aider à combler ces lacunes sans compromettre la simplicité pour les développeurs.
OpenRouter est une passerelle d'IA axée sur les développeurs qui permet d'accéder à plusieurs grands modèles de langage via une seule API, ce qui permet OpenRouter contre AI Gateway un point d'évaluation commun pour les équipes qui accordent la priorité à la flexibilité. Il simplifie l'intégration et la gestion, ce qui le rend idéal pour les équipes en quête de flexibilité et d'efficacité.
Accès unifié à l'API : Se connecte à plusieurs LLM de fournisseurs tels qu'OpenAI, Anthropic et Google, ce qui réduit la complexité liée à la gestion de plusieurs SDK.
Routage automatique et repli : Les demandes sont acheminées vers le meilleur modèle en fonction des performances, des coûts et de la disponibilité, avec un repli automatique en cas de panne.
Tarification et facturation transparentes : Une tarification claire par jeton et une facturation consolidée simplifient la gestion des coûts.
Apportez votre propre clé (BYOK) : Permet d'utiliser des clés d'API personnelles pour mieux contrôler l'authentification et les coûts.
Restrictions
Limites de débit sur les modèles gratuits : Les modèles de niveau gratuit ont des limites strictes, ce qui peut restreindre les tests ou le développement.
Latence en cas de forte charge : Les temps de réponse peuvent augmenter en fonction du modèle et du trafic.
Lisez également : Requesty et OpenRouter
Portkey est une passerelle d'IA open source conçue pour rationaliser l'accès à plus de 1 600 modèles d'IA, y compris des modèles de langage volumineux (LLM), des modèles de vision, audio et d'image. Il propose une API unifiée qui simplifie l'intégration et la gestion, ce qui en fait le choix idéal pour les développeurs en quête de flexibilité et d'efficacité.
Accès unifié à l'API : Portkey fournit un point de terminaison d'API unique qui se connecte à de nombreux modèles d'IA de différents fournisseurs, réduisant ainsi la complexité liée à la gestion de plusieurs SDK et informations d'identification.
Routage intelligent et basculement : La plateforme achemine intelligemment les demandes vers le modèle le plus approprié en fonction de facteurs tels que le coût, les performances et la disponibilité. En cas de panne, il revient automatiquement à d'autres modèles, ce qui garantit une fiabilité élevée.
Observabilité avancée : Portkey propose une surveillance en temps réel des charges utiles des demandes/réponses, de l'utilisation des jetons, des mesures de latence et des coûts, le tout accessible via un tableau de bord centralisé.
Intégration des garde-corps : La passerelle s'intègre à Prisma AIRS, fournissant une sécurité basée sur l'IA en temps réel pour protéger les applications, les modèles et les données contre un large éventail de menaces.
Mise en cache et optimisation des coûts : Portkey met en œuvre une mise en cache simple et sémantique pour réduire la latence et réduire les coûts, améliorant ainsi l'efficacité des opérations d'IA.
Limites de débit sur les modèles gratuits : Les modèles de niveau gratuit sont soumis à des limites de débit strictes, ce qui peut limiter le développement et les tests pour les utilisateurs utilisant des modèles gratuits.
Complexité pour les applications à petite échelle : Bien que riches en fonctionnalités, les fonctionnalités étendues de Portkey peuvent être mieux adaptées aux applications à grande échelle, ce qui peut compliquer inutilement les petits projets et inciter les équipes à explorer alternatives à Portkey.
LitellM est une passerelle d'IA open source conçue pour simplifier l'accès à plus de 100 grands modèles de langage (LLM) et à d'autres services d'IA. Il propose une API unifiée qui permet aux développeurs d'intégrer facilement divers modèles d'IA, ce qui en fait un choix intéressant pour les équipes en quête de flexibilité et d'efficacité.
Accès unifié à l'API : LiteLM fournit un point de terminaison d'API unique pour se connecter à plusieurs LLM de fournisseurs tels qu'OpenAI, Azure, AWS Bedrock, Hugging Face et Google Vertex AI. Cette standardisation réduit la complexité de la gestion de plusieurs SDK et informations d'identification.
Gestion du budget et des limites tarifaires : La plateforme permet de définir des budgets et des limites tarifaires par utilisateur, par équipe ou par clé d'API. Cette fonctionnalité permet de contrôler les coûts et de garantir une utilisation équitable entre les différents utilisateurs et équipes.
Support pour le streaming : LiteLM prend en charge le streaming des réponses des modèles, permettant une interaction en temps réel et améliorant l'expérience utilisateur.
Journalisation et observabilité : Il s'intègre à des outils tels que Prometheus, Datadog et S3/GCS pour la journalisation et la surveillance, fournissant des informations sur les modèles d'utilisation et les mesures de performance.
Intégration des garde-corps : LitellM prend en charge l'intégration de garde-corps pour garantir une utilisation sûre et conforme de l'IA, avec des options pour l'application des modèles d'appel avant, après ou pendant l'application des modèles d'appel.
Contrôle d'accès de base dans la version open source : La version open source offre des fonctionnalités de contrôle d'accès de base. Des fonctionnalités avancées telles que l'authentification JWT et les journaux d'audit sont disponibles dans la version entreprise.
Glots d'étranglement potentiels en matière de performances en cas de charge élevée : Certains utilisateurs ont signalé une dégradation des performances en cas de taux de demande élevés, ce qui indique des problèmes d'évolutivité potentiels dans certains scénarios.
Découvrez également : Les 5 meilleurs Alternatives à LiteLM en 2026
Unify AI est une passerelle d'IA open source conçue pour simplifier l'accès à un large éventail de grands modèles de langage (LLM) et à d'autres services d'IA. Il propose une API unifiée qui permet aux développeurs d'intégrer facilement divers modèles d'IA, ce qui en fait un choix intéressant pour les équipes en quête de flexibilité et d'efficacité.
Accès unifié à l'API : Unify AI fournit un point de terminaison d'API unique pour se connecter à plusieurs LLM de fournisseurs tels qu'OpenAI, Anthropic et Google Vertex AI. Cette standardisation réduit la complexité de la gestion de plusieurs kits de développement logiciel et informations d'identification.
Modèle de routage dynamique : La plateforme achemine intelligemment les demandes vers le modèle le plus adapté en fonction de facteurs tels que le coût, les performances et la disponibilité, garantissant une utilisation optimale des ressources.
Observabilité en temps réel : Unify AI permet de surveiller en temps réel les charges utiles des demandes/réponses, l'utilisation des jetons, les mesures de latence et les coûts, le tout accessible via un tableau de bord centralisé.
Intégration des garde-corps : La passerelle s'intègre à Prisma AIRS, fournissant une sécurité basée sur l'IA en temps réel pour protéger les applications, les modèles et les données contre un large éventail de menaces.
Mise en cache et optimisation des coûts : Unify AI met en œuvre une mise en cache simple et sémantique pour réduire la latence et réduire les coûts, améliorant ainsi l'efficacité des opérations d'IA.
Limites de débit sur les modèles gratuits : Les modèles de niveau gratuit sont soumis à des limites de débit strictes, ce qui peut limiter le développement et les tests pour les utilisateurs utilisant des modèles gratuits.
Complexité pour les applications à petite échelle : Bien que riches en fonctionnalités, les fonctionnalités étendues de Unify AI peuvent être mieux adaptées aux applications à grande échelle, ce qui peut entraîner une complexité inutile pour les petits projets.
Choisir la bonne passerelle LLM ne consiste pas seulement à choisir l'option la plus populaire ; il s'agit également d'adapter la plateforme aux objectifs, à la taille et au flux de travail de votre équipe. Chaque passerelle que nous avons abordée a ses points forts, et la « meilleure solution » dépend de vos priorités.
Si vous êtes une start-up ou une petite équipe, les options légères et open source comme Helicone ou LiteLM peuvent être intéressantes. Ils offrent de faibles frais généraux, une intégration rapide et une forte observabilité sans nécessiter une infrastructure étendue ni une gestion de la conformité.
Pour les entreprises dont les flux de travail sont complexes, TrueFoundry ou Portkey fournit une orchestration robuste, un contrôle d'accès précis et des fonctionnalités de conformité. Ils vous permettent de gérer les agents, les instructions de version et de mettre en place des garde-fous tout en optimisant les coûts à grande échelle.
Si votre priorité est la flexibilité des développeurs et l'accès multimodèle, des passerelles comme OpenRouter et Unify AI simplifient les intégrations grâce à une API unique et à un routage intelligent. Ils permettent d'expérimenter plus facilement sur plusieurs LLM tout en gardant un œil sur la latence et l'utilisation.
En fin de compte, la bonne passerelle offre un équilibre entre performances, coûts, conformité et évolutivité pour votre cas d'utilisation spécifique. Commencez par cartographier vos exigences techniques, votre base d'utilisateurs et le trafic attendu, puis évaluez comment chaque passerelle répond à ces besoins. Le choix idéal est celui qui soutient la croissance, permet à votre infrastructure de rester gérable et permet à votre équipe de se concentrer sur la construction, et non sur la lutte contre les incendies.
La sélection de la bonne passerelle LLM peut faire ou défaire votre stratégie d'IA en 2026. Que vous donniez la priorité à la rapidité, à la rentabilité, à la conformité ou à l'accès multimodèle, les passerelles que nous avons couvertes offrent des solutions adaptées à tous les besoins. TrueFoundry et Portkey excellent en matière d'orchestration et de sécurité de niveau professionnel, tandis que Helicone, LiteLM, OpenRouter et Unify AI offrent une flexibilité adaptée aux développeurs et une intégration légère. L'essentiel est d'aligner votre choix sur votre flux de travail, votre échelle et vos objectifs. Une passerelle choisie avec soin simplifie non seulement la gestion des modèles, mais permet également à votre équipe d'innover plus rapidement, d'optimiser les ressources et de fournir des applications d'IA en toute confiance.
TrueFoundry est la meilleure passerelle LLM pour les équipes d'IA d'entreprise qui ont besoin d'une infrastructure LLM sécurisée, évolutive et prête pour la production. Contrairement aux proxys de base, la passerelle IA de TrueFoundry est conçue pour la gouvernance, la fiabilité et les déploiements à grande échelle, ce qui en fait la solution idéale pour les organisations qui exécutent des applications d'IA critiques.
Lorsque vous choisissez une passerelle LLM, recherchez un support multifournisseur, un routage et une solution de secours intelligents, une limitation du débit, une mise en cache, des analyses d'utilisation détaillées, un suivi des coûts, un RBAC, une gestion sécurisée des clés et une forte observabilité. Les équipes de l'entreprise doivent également donner la priorité aux journaux d'audit, au contrôle d'accès au niveau de l'environnement et à la haute disponibilité.
Les passerelles LLM améliorent les performances grâce au routage intelligent, aux nouvelles tentatives automatiques et à la mise en cache des réponses. Ils réduisent les coûts en permettant de sélectionner des modèles sur la base de compromis prix/performances, en imposant des limites de taux et en fournissant une visibilité de l'utilisation en temps réel pour éviter les dépenses excessives.
TrueFoundry se distingue comme la meilleure passerelle LLM en fournissant un plan de contrôle unifié pour l'orchestration et la sécurité des modèles. Il intègre l'observabilité en temps réel à un basculement automatique, garantissant ainsi une haute disponibilité entre les fournisseurs. Sa prise en charge native des GPU et son RBAC de niveau entreprise permettent aux entreprises de faire évoluer l'IA de production tout en maintenant une résidence et une conformité strictes des données.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


