

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Dans notre série de blogs sur Kubernetes, nous avons parlé des bâtiments MLOps évolutifs sur Kubernetes, architecture pour MLOps, et résolution du développement d'applications. Dans ce blog, nous allons parler de l'hébergement d'un service GRPC sur le cluster AWS EKS. Le processus sera à peu près le même pour tous les clusters Kubernetes. Cependant, nous avons dû définir certains paramètres spécifiques sur l'équilibreur de charge AWS pour que cela fonctionne.
gRPC est un framework RPC open source qui peut fonctionner dans n'importe quel environnement. Il est capable de connecter efficacement les services au sein des centres de données et entre eux, avec la possibilité de connecter un support pour l'équilibrage de charge, le suivi, la vérification de l'état et l'authentification.
Notre cas d'utilisation: Hébergement de modèles Tensorflow sous forme d'API acceptant une charge utile d'environ 100 Mo. Le GRPC fonctionne bien mieux pour les charges utiles plus importantes. Nous avons donc exposé le port GRPC sur le port 5000.
Nous avons hébergé le service sur Kubernetes en utilisant le code YAML de déploiement ci-dessous :
Version de l'API : applications/v1
type : Déploiement
métadonnées :
nom : ml-api
espace de noms : ml-services
spécification :
répliques : 1
sélecteur :
Étiquettes de match :
truefoundry.com/component : ml-api
modèle :
métadonnées :
étiquettes :
truefoundry.com/application : ml-api
spécification :
conteneurs :
- nom : ml-api
image : >-
xxxx.dkr. ecr.us-east-1.amazonaws.com /ml-services-ml-api:latest
ports :
- nom : port-8500
Port de conteneur : 8500
protocole : TCP
ressources :
limites :
processeur : « 4 »
stockage éphémère : 2G
mémoire : 4G
demandes :
processeur : « 1 »
stockage éphémère : 1G
mémoire : 500M
Politique d'extraction de l'image : si elle n'est pas présente
Politique de redémarrage : Toujours
Période de grâce de terminaison en secondes : 30
Politique DNS : ClusterFirst
Contexte de sécurité : {}
Les secrets de ImagePull :
- nom : ml-api-image-pull-secret
Nom du planificateur : planificateur par défaut
stratégie :
type : RollingUpdate
Mise à jour en cours :
Maximum disponible : 25 %
Surge maximale : 0
Cela fera apparaître la capsule. Nous devons créer l'objet Service à l'aide du code YAML ci-dessous :
Version de l'API : networking.istio.io/v1alpha3
type : Gateway
métadonnées :
étiquettes :
argocd.argoproj.io/instance : tfy-istio-ingress
nom : tfy-wildcard
espace de noms : istio-system
spécification :
sélecteur :
Adresse : tfy-istio-ingress
serveurs :
- hôtes :
- « ml.exemple.com »
port :
nom : http-tfy-wildcard
Numéro : 80
protocole : HTTP
tls :
HttpsRedirect : vrai
- hôtes :
- « ml.exemple.com »
port :
nom : https-tfy-wildcard
Numéro : 443
protocole : HTTP
Nous utilisons Istio comme couche d'entrée dans Kubernetes. Istio provisionne un équilibreur de charge lorsque l'istio-ingress est installé. La configuration de l'équilibreur de charge peut être personnalisée à l'aide d'annotations sur la passerelle istio. Les spécifications pour créer la passerelle Istio sont les suivantes :
Version de l'API : networking.istio.io/v1alpha3
type : Gateway
métadonnées :
étiquettes :
argocd.argoproj.io/instance : tfy-istio-ingress
nom : tfy-wildcard
espace de noms : istio-system
spécification :
sélecteur :
Adresse : tfy-istio-ingress
serveurs :
- hôtes :
- « ml.exemple.com »
port :
nom : http-tfy-wildcard
Numéro : 80
protocole : HTTP
tls :
HttpsRedirect : vrai
- hôtes :
- « ml.exemple.com »
port :
nom : https-tfy-wildcard
Numéro : 443
protocole : HTTP
Nous procédons à la terminaison SSL sur l'AWS Load Balancer. Pour cela, nous devons joindre le certificat au Load Balancer. Cela peut être réalisé en utilisant les annotations ci-dessous sur le graphique de la passerelle istio (https://istio-release.storage.googleapis.com/charts).
« service.beta.kubernetes.io/aws-load-balancer-type » : « nlb »
« service.beta.kubernetes.io/aws-load-balancer-backend-protocol » : « tcp »
<certificate-arn>« service.beta.kubernetes.io/aws-load-balancer-ssl-cert » : »
« service.beta.kubernetes.io/aws-load-balancer-ssl-ports » : « https »
« service.beta.kubernetes.io/aws-load-balancer-alpn-policy » : « Http2Preferred »
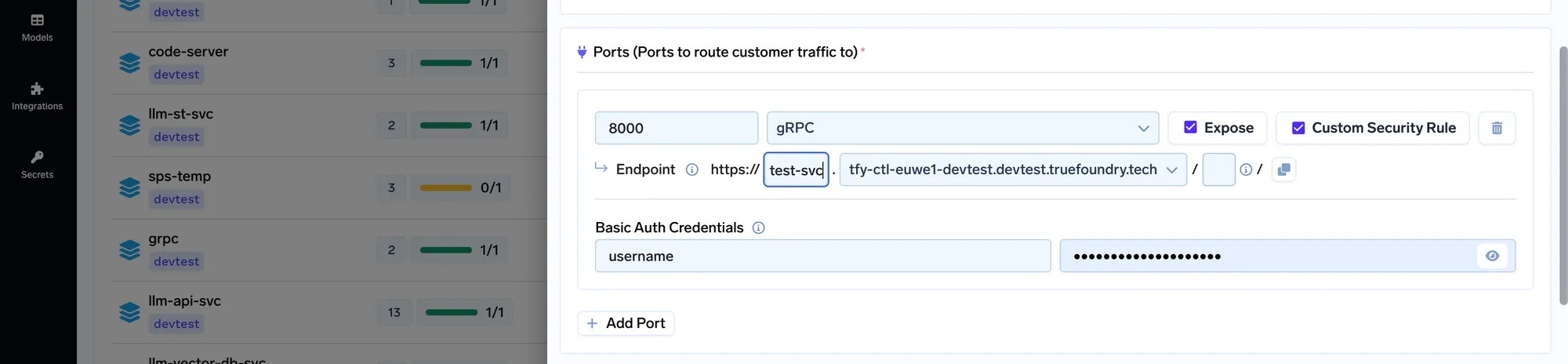
Il est important de spécifier la politique alpn pour autoriser le trafic GRPC. Notre service ml-api peut être exposé en créant un VirtualService pointant vers le service Kubernetes. Le YAML pour le service virtuel est le suivant :
Version de l'API : networking.istio.io/v1alpha3
type : VirtualService
métadonnées :
étiquettes :
argocd.argoproj.io/instance : ml-services_ml-api
nom : ml-apiport-8500-vs
espace de noms : ml-services
spécification :
passerelles :
- istio-system/tfy-wildcard
hôtes :
- ml.exemple.com
http :
- itinéraire :
- destination :
hébergeur : ml-api
port :
Numéro : 8500
Une fois le service virtuel exposé, nous pouvons adresser des demandes à notre service à l'adresse ml.example.com. Nous avons ensuite voulu ajouter une authentification à l'API afin que tout le monde ne puisse pas appeler l'API. Nous aurions pu ajouter l'authentification dans le code, mais nous avons décidé de l'ajouter au niveau de la couche istio afin qu'il puisse s'agir d'une couche unifiée pour tous les services.
Pour ajouter une authentification au niveau de la couche istio-ingress, nous avons décidé de procéder avec un Plug-in IstioWasm. Le fichier yaml du plugin ressemble à ceci :
Version de l'API : extensions.istio.io/v1alpha1
type : WASMPlugin
métadonnées :
nom : ml-services-ml-api-0
espace de noms : istio-system
spécification :
phase : AUTHN
Configuration du plugin :
règles_d'authentification de base :
- informations d'identification :
- nom d'utilisateur : mot de passe
hôtes :
- ml.exemple.com
préfixe :/
méthodes_demandes :
- OBTENIR
- METTRE
- POSTE
- ÉCUSSON
- SUPPRIMER
sélecteur :
Étiquettes de match :
Adresse : tfy-istio-ingress
URL : oci : //ghcr.io/istio-ecosystem/wasm-extensions/basic_auth:1.12.0
Une fois que vous avez appliqué la spécification ci-dessus au cluster, l'application vous demandera le nom d'utilisateur et le mot de passe une fois que vous l'aurez ouverte dans le navigateur.
Pour rendre le processus ci-dessus beaucoup plus facile, nous décidons de le rendre très simple sur Véritable fonderie plateforme.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


