

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 29, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Chaque demande LLM qui passe par TrueFoundry AI Gateway génère une trace. Cette trace capture l'arborescence complète de la demande : gestion de la passerelle, validation JWT et résolution des autorisations, routage du fournisseur, appel de modèle sortant et réponse en flux continu. Ces traces sont stockées en interne pour l'interface utilisateur de TrueFoundry Monitor. Mais ils peuvent également être exportés via les protocoles OpenTelemetry standard vers des backends d'observabilité externes. Arize est l'un de ces backend.
Cet article explique comment fonctionne l'exportation de traces au niveau de l'architecture : quelles primitives OTEL sont impliquées, comment la passerelle émet des traces sans ajouter de latence au chemin de la demande et ce que fait Arize avec les données de trace une fois qu'elles arrivent. Il couvre également la surface de configuration et les contrôles de confidentialité des données qui vous permettent de supprimer le contenu rapide avant qu'il ne quitte votre infrastructure.
OpenTelemetry définit un format de fil indépendant du fournisseur pour les traces distribuées. Une trace est un arbre de travées reliées par les relations parents-enfants. Chaque intervalle représente une unité de travail distincte : un gestionnaire HTTP, un appel LLM ou une invocation d'outil. Les spans comportent des attributs de valeur clé saisis qui codent le contexte opérationnel, tels que les codes de latence et d'état et le nombre de jetons.
Les conventions sémantiques OTEL standard couvrent bien les systèmes distribués à usage général, mais elles n'ont pas été conçues pour les charges de travail LLM. Les appels LLM comportent des entrées structurées (tableaux de messages multitours avec instructions système, définitions d'outils et contenu multimodal) et des sorties structurées (complétions avec raisons de fin et appels de fonction). L'économie des jetons est une métrique opérationnelle de premier ordre : les jetons rapides et les jetons de complétion, ainsi que les jetons mis en cache et les jetons de raisonnement doivent tous être suivis par intervalle. Un single valeur d'entrée l'attribut string est insuffisant.
C'est là que les conventions sémantiques spécifiques au LLM entrent en jeu. Arize gère la spécification OpenInference qui définit un schéma d'attributs concret et une taxonomie des types de spans en plus des spans OTEL. Chaque trace OpenInference est une trace OTLP valide. Les conventions donnent aux noms d'attributs leur signification spécifique à l'IA. Espanez des types tels que LLM et CHAÎNE et RETRIEVER et OUTIL et ENCASTREMENT classifiez les opérations afin que les plateformes d'observabilité puissent générer des traces grâce à des visualisations et des agrégations compatibles avec l'IA.
TrueFoundry AI Gateway émet des traces à l'aide de son propre espace de noms d'attributs (tfy.input et tfy.output et tfy.input_short_hand ainsi que la norme gen_ai. * attributs pour le nombre de jetons, les métadonnées du modèle et les raisons de fin d'achèvement). Arize les ingère en tant que traces OTLP valides et mappe les attributs dans son interface utilisateur de suivi.
TrueFoundry AI Gateway utilise une architecture divisée : un plan de contrôle qui gère la configuration et un plan de passerelle qui traite les demandes d'inférence. Le plan de passerelle est construit sur le framework Hono, qui est un environnement d'exécution HTTP ultra rapide optimisé pour les périphériques. Un seul module de passerelle sur 1 processeur virtuel et 1 Go de RAM gère plus de 250 demandes par seconde avec environ 3 ms de latence supplémentaire.
Le principe de conception essentiel est qu'il n'y a aucun appel externe dans le chemin de la demande, à l'exception de l'appel réel du fournisseur LLM. Lorsqu'une demande arrive à un pod de passerelle, les opérations suivantes se produisent entièrement en mémoire :
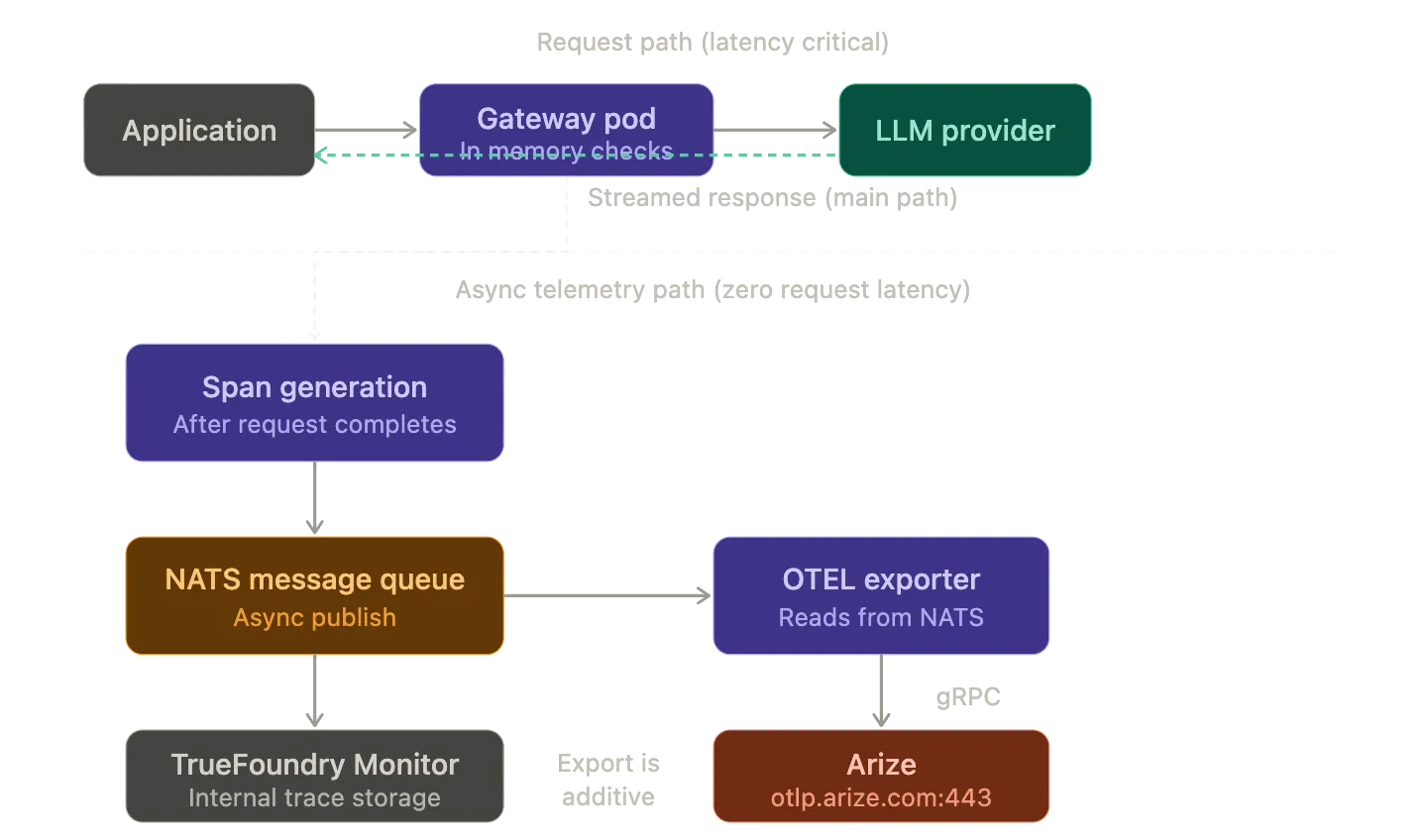
La génération de traces s'effectue de manière asynchrone parallèlement à ce flux. La passerelle crée des intervalles OTEL pour chaque étape du cycle de vie de la demande : le gestionnaire HTTP entrant et le contrôle d'authentification, la résolution du modèle, l'appel sortant du fournisseur et la réponse en streaming. Ces spans contiennent des attributs qui capturent l'utilisation et la latence des jetons, ainsi que le nom du modèle et le fournisseur, l'estimation des coûts et les métadonnées des demandes. Une fois la demande terminée, la passerelle publie les données de trace dans une file de messages NATS. Il s'agit du même bus NATS qui gère la synchronisation de la configuration entre le plan de contrôle et les modules de passerelle.
L'exportateur OTEL récupère les données de trace à partir de ce chemin asynchrone et les transmet au point de terminaison externe configuré. Comme l'exportation de traces est découplée du chemin de la demande, elle n'ajoute aucune latence aux demandes d'inférence. La passerelle ne fait jamais échouer une demande, même si le point de terminaison externe de l'OTEL est inaccessible.

Arize est une plateforme d'observabilité et d'évaluation de l'IA spécialement conçue pour les charges de travail des LLM et des agents. Il accepte les traces OTEL via gRPC à otlp.arize.com : 443 et fournit plusieurs couches d'analyse en plus des données de trace brutes.
Visualisation des traces. Arize affiche des cascades de traces complètes montrant l'arbre de la travée pour chaque demande. Vous pouvez inspecter les spans individuels pour voir l'utilisation des jetons et la répartition de la latence, ainsi que le contenu des entrées et des sorties et les métadonnées du modèle. Pour les flux de travail des agents où une seule demande utilisateur déclenche plusieurs appels LLM et des appels d'outils, cette vue en cascade rend le chemin d'exécution lisible.
Analyse des performances. Arize calcule des mesures agrégées sur l'ensemble de votre flux de traces : distributions de latence par modèle et par fournisseur, taux d'erreur au fil du temps et tendances en matière de débit. Vous pouvez configurer des règles d'alerte qui se déclenchent lorsque des anomalies apparaissent dans ces distributions. Ceci est utile pour détecter la dégradation des fournisseurs avant qu'elle n'affecte les utilisateurs finaux.
Évaluation LLM. Au-delà du traçage brut, Arize prend en charge des pipelines d'évaluation automatisés. Vous pouvez exécuter des flux de travail LLM as a Judge qui évaluent les résultats sur des critères tels que la pertinence, la cohérence et la factualité. Vous pouvez également intégrer des flux de travail d'annotation humains pour une évaluation de la qualité plus nuancée. Les traces fournissent les données brutes (entrées et sorties et paramètres du modèle) qui alimentent ces boucles d'évaluation.
Le principal facteur de différenciation est qu'Arize comprend la sémantique spécifique au LLM de manière native. Il analyse le nombre de jetons et les identificateurs de modèles, invite le contenu à sortir de l'étendue des attributs et les affiche dans des vues spécialement conçues au lieu de les traiter comme des paires clé-valeur de chaîne génériques.
L'intégration consiste en une exportation directe de gRPC depuis la passerelle vers Arize. Aucun side-car collecteur n'est nécessaire. Aucun SDK personnalisé n'est impliqué. Vous configurez l'exportateur OTEL dans le tableau de bord TrueFoundry et les traces commencent à circuler.
Vous pouvez suivre les étapes d'intégration ici : https://www.truefoundry.com/docs/ai-gateway/arize
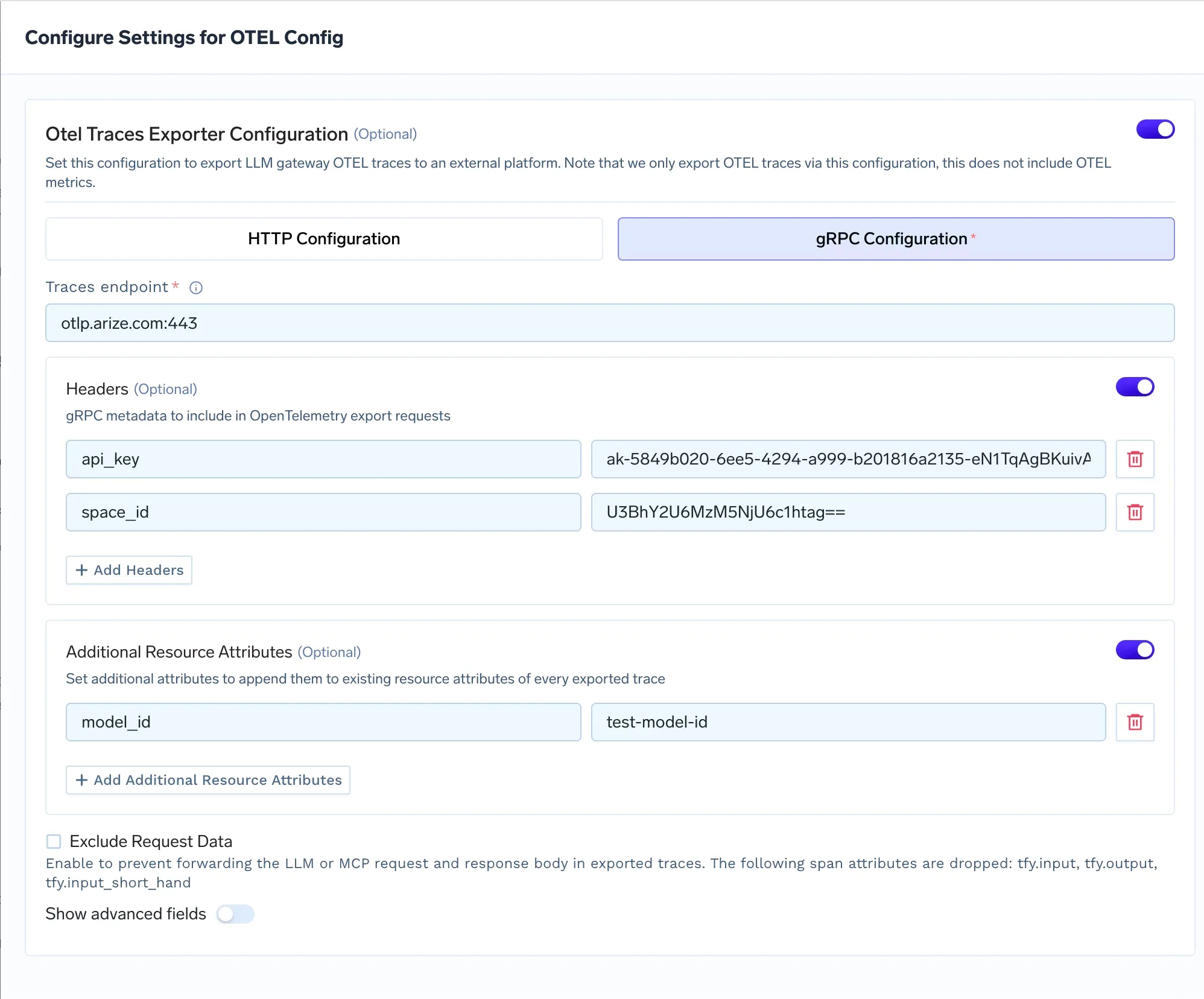
Vous pouvez associer des attributs de ressource supplémentaires à chaque trace exportée. Il s'agit de paires clé-valeur qui sont ajoutées au niveau de la trace et qui sont utiles pour le filtrage et le regroupement dans Arize.
L'attribut le plus courant à définir est identifiant_modèle. Arize l'utilise pour regrouper les traces par modèle dans les vues de son tableau de bord. Si vous acheminez le trafic de production via un modèle LLama affiné, vous pouvez définir identifiant_modèle pour production de lama-3 aux réglages raffinés. Vous pouvez également ajouter version_modèle si vous exécutez des déploiements parallèles et que vous souhaitez comparer les performances entre les versions d'Arize.
Dans certains scénarios de déploiement, le contenu rapide et le contenu complet ne doivent pas quitter votre infrastructure. Les exigences de conformité peuvent interdire l'envoi des organismes de demande à des services tiers. Les informations personnelles contenues dans les invites peuvent empêcher l'exportation externe de démarrer.
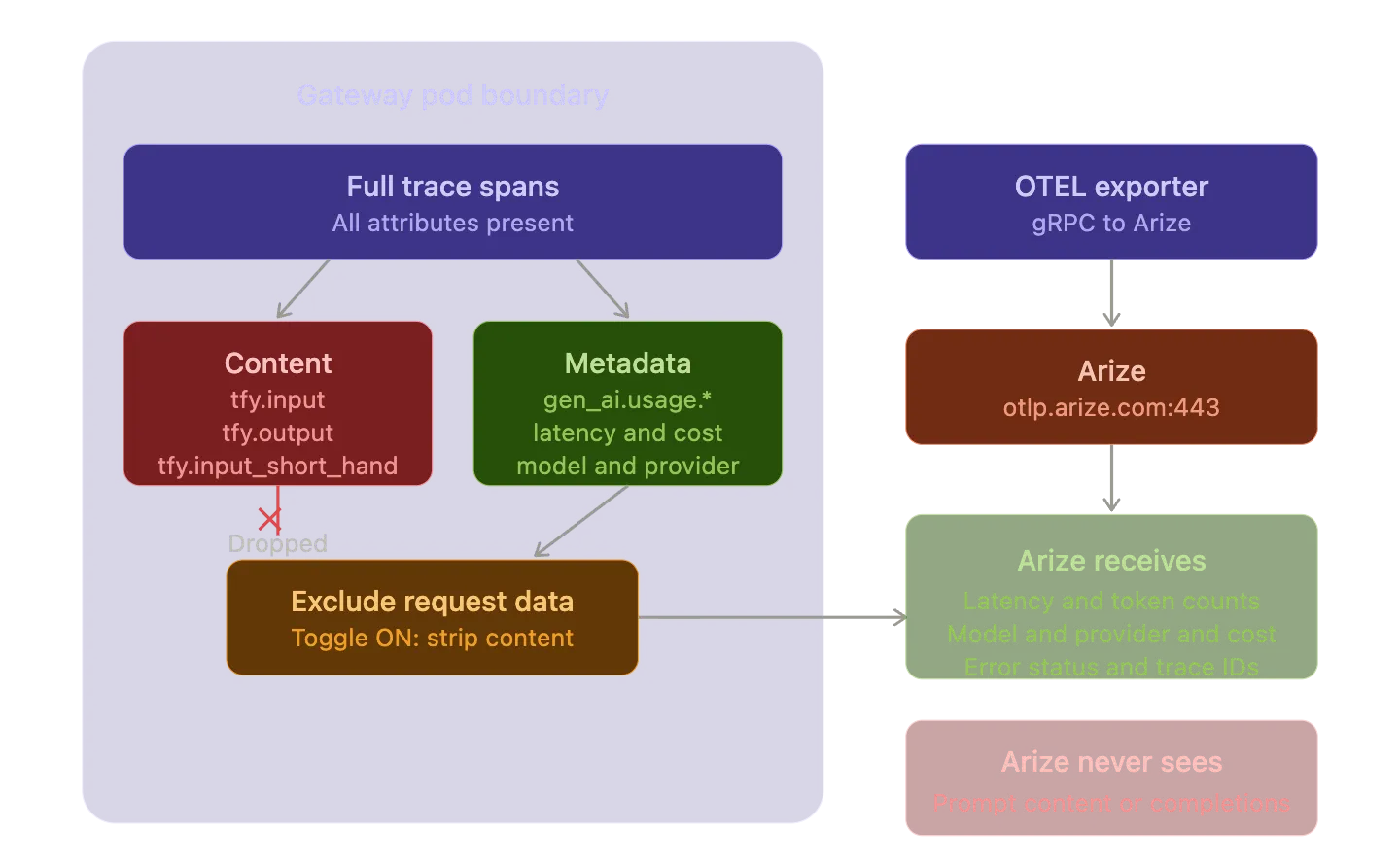
TrueFoundry gère cela à l'aide du bouton Exclure les données de demande dans la configuration de l'exportateur OTEL. Lorsque cette option est activée, la passerelle supprime trois attributs de span avant l'exportation : tfy.input et tfy.output et tfy.input_short_hand. Arize reçoit toujours les données de trace structurelles (latence et nombre de jetons, métadonnées du modèle et état des erreurs) mais ne voit jamais le contenu réel des instructions ou des complétions.
Il s'agit d'un détail architectural important. Le filtrage s'effectue au niveau de la passerelle avant que les données de trace n'atteignent l'exportateur gRPC. Le contenu ne quitte jamais le module de passerelle. Vous bénéficiez d'une observabilité totale en termes de performances, de coûts et de fiabilité sans exposer de contenu sensible à une plateforme externe.
Après avoir enregistré la configuration OTEL, envoyez quelques requêtes LLM via la passerelle. Ouvrez ensuite le tableau de bord Arize et accédez à Traces. Recherchez des traces provenant du passerelle tfy-llm service. Chaque trace doit afficher l'arborescence complète avec les plages de gestion des passerelles et la durée des appels sortants du fournisseur LLM. Cliquez sur des intervalles individuels pour vérifier que l'utilisation des jetons, la latence et les métadonnées du modèle sont correctement renseignées.
Si vous avez configuré des attributs de ressources, vous devriez les voir apparaître dans les métadonnées de suivi. Utilisez le identifiant_modèle attribut pour filtrer la liste des traces et vérifier que les traces sont correctement regroupées par modèle.
Le flux de données est simple. Les applications envoient des requêtes LLM à TrueFoundry AI Gateway. La passerelle traite la demande en mémoire (authentification et autorisation, routage et limitation de débit) et la transmet au fournisseur de modèle configuré. En parallèle, la passerelle génère des spans OTEL pour le cycle de vie des requêtes et les publie de manière asynchrone dans la file de messages NATS. L'exportateur OTEL lit cette file d'attente et envoie des traces via gRPC à otlp.arize.com : 443. Arize ingère les traces OTLP et les rend disponibles pour visualisation, analyse et évaluation.
Aucun appel externe n'est ajouté au chemin d'inférence. Aucun side-car collector n'a besoin d'être déployé. Aucune modification du code d'application n'est requise. La passerelle est le point d'instrumentation unique et l'exportation OTEL s'ajoute au stockage de traces interne de la passerelle. Vous pouvez exporter vers Arize tout en continuant à utiliser l'interface utilisateur Monitor intégrée de TrueFoundry pour les mêmes données de trace.
C'est ce schéma qui fait de l'OTEL un choix de protocole précieux. La passerelle émet des traces OTLP standard. Arize accepte les traces OTLP standard. Si vous décidez de changer de backend d'observabilité demain, vous modifiez le point de terminaison et les en-têtes dans la configuration de la passerelle et vous pointez vers un autre récepteur OTLP. Le code de votre application, la configuration de votre passerelle et votre instrumentation de suivi restent exactement les mêmes.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


