

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 23, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Au début des années 2010, la révolution des microservices s'est heurtée à un mur. Nous avions divisé nos monolithes en centaines de services, mais nous ne nous étions pas mis d'accord sur la manière dont ils devaient parler. Certaines équipes ont utilisé REST, d'autres XML-RPC, d'autres le TCP brut. Le résultat a été une « Tour de Babel », un écosystème fragmenté où l'intégration était difficile et l'observabilité impossible.
L'industrie a résolu ce problème grâce à la standardisation : grPC pour le transport, Protobuf pour le schéma, et OpenTelemetry pour l'observabilité.
Aujourd'hui, le IA agentique L'écosystème se trouve exactement dans ce chaos d'avant la standardisation.
Ces agents ne peuvent naturellement pas collaborer. Ils ont des représentations d'état différentes, des mécanismes de gestion des erreurs différents et aucun concept d'identité commun.
Pour résoudre ce problème, TrueFoundry introduit le support pour Protocole A2A (agent à agent). Il s'agit d'une couche de transport stricte qui normalise la communication, transformant une collection fragmentée de scripts en un ensemble unifié Maillage cognitif.
L'erreur fondamentale de la plupart des premières conceptions d'agents est de traiter la communication agent-agent comme un simple appel d'API (POST /chat {« prompt » : «... »}). C'est insuffisant car il manque Métacognition.
Un agent n'a pas seulement besoin du texte du message. Il a besoin de savoir :
Le protocole A2A résout ce problème en encapsulant chaque interaction dans un Enveloppe. Nous traitons la logique métier de l'agent (l'invite) comme Charge utile, mais nous l'enveloppons dans un emballage rigide Plan de contrôle.
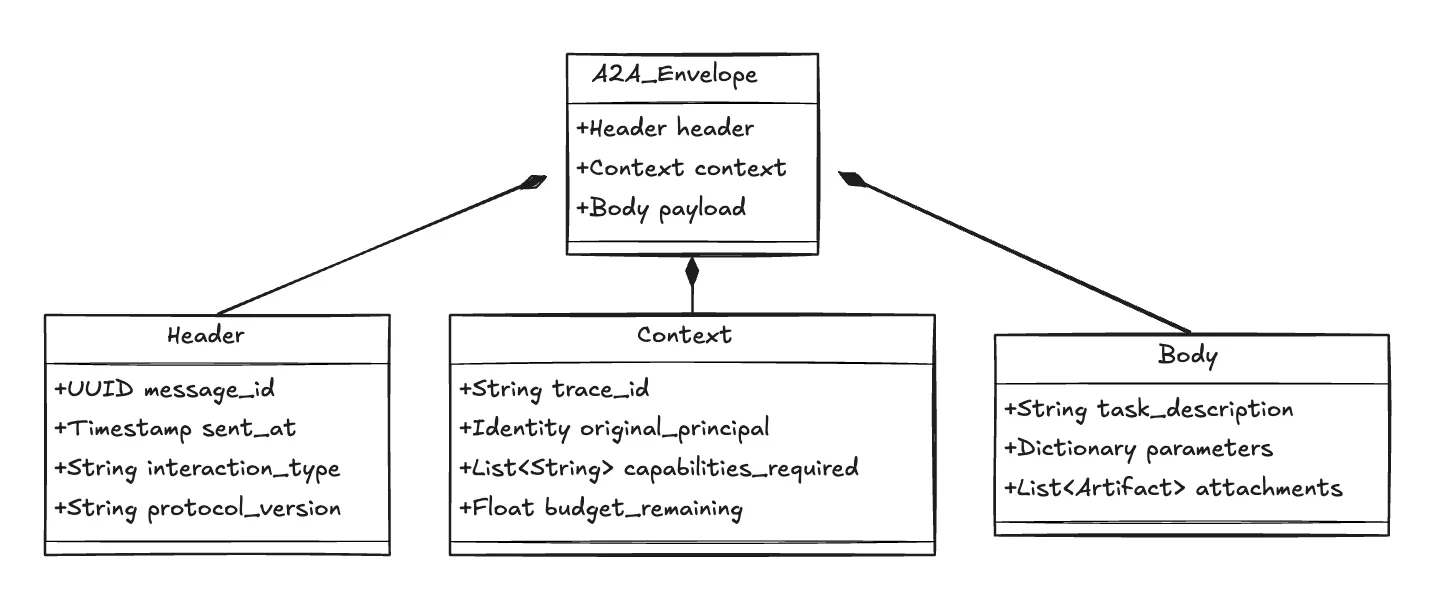
Figure 1 : Enveloppe A2A de sa structure sous-jacente
Lisez également : MCP contre A2A
Pour illustrer la puissance de ce protocole, examinons un scénario complexe à plusieurs piles : Système de due diligence en matière de fusions et acquisitions.
Ce système nécessite trois agents hautement spécialisés qui utilisent des technologies complètement différentes :
Sans protocole, le Python Manager ne peut pas facilement déclencher l'équipe AutoGen. AutoGen s'attend à un format d'historique des conversations spécifique, tandis que LangChain s'attend à une « chaîne ». Si le Legal Reviewer (Node) génère une erreur, le Python Manager peut l'interpréter comme une hallucination plutôt que comme une défaillance du système.
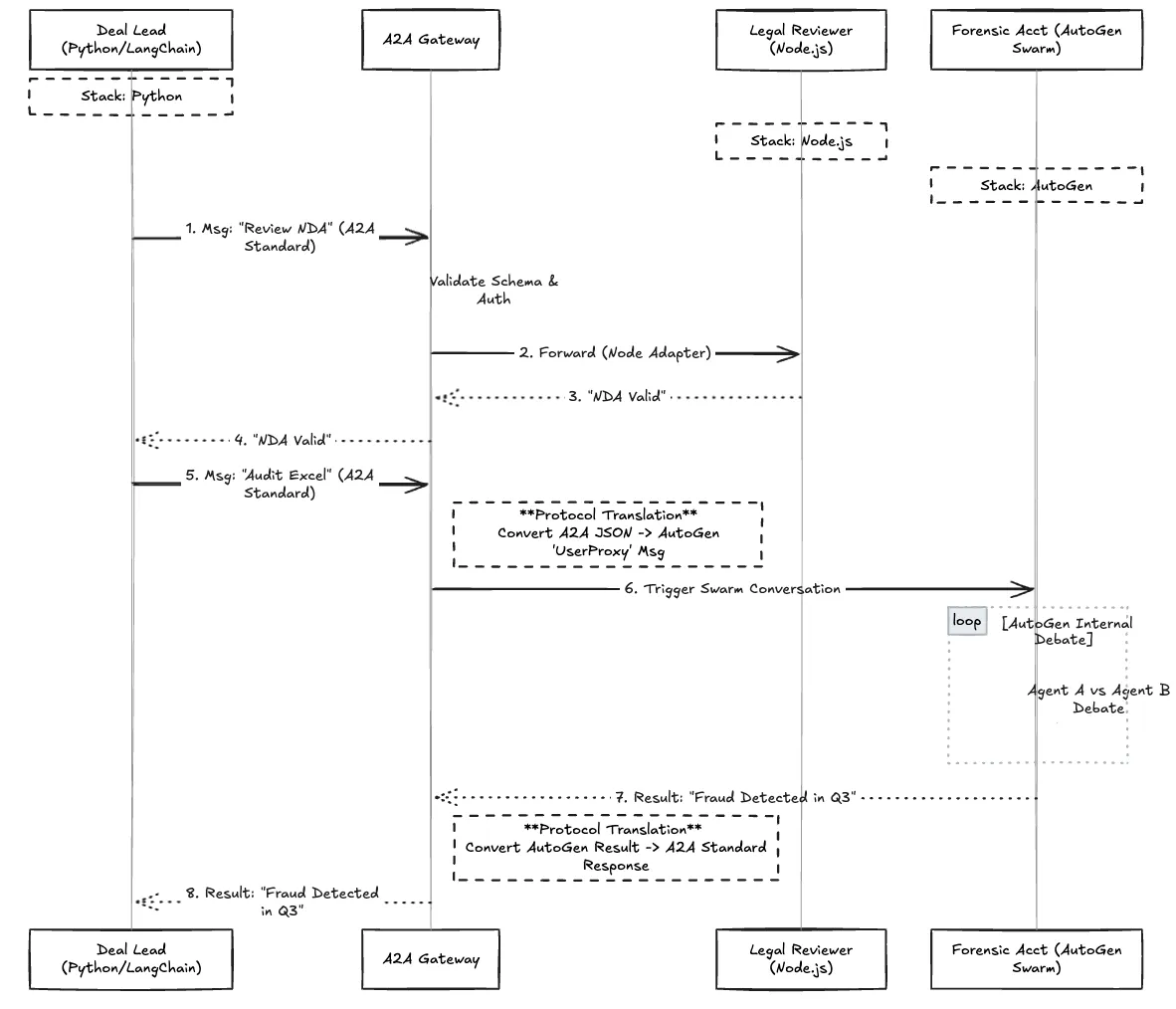
Figure 2 : Le déroulement détaillé d'un processus de révision juridique
Dans un maillage d'agents poste à poste, l'agent A appelle directement l'agent B. C'est dangereux car cela nuit à l'observabilité et à la sécurité. Si l'agent A est compromis, il peut inonder l'agent B de demandes, et personne ne le saura avant l'arrivée de la facture.
Le protocole A2A applique un Hub-and-Spoke modèle.

Le débogage d'un seul LLM est difficile. Le débogage d'une chaîne récursive de 5 agents est impossible sans traçage distribué.
Lorsque le « responsable de la transaction » ne parvient pas à conclure l'opération de fusion et d'acquisition, vous devez savoir pourquoi. Y a-t-il eu un délai d'attente pour l'agent juridique ? Le juricomptable n'a-t-il plus de jetons ?
Les mandats du protocole A2A Propagation d'en-tête. Lorsque la passerelle reçoit la demande initiale, elle génère un TraceID. Cela oblige chaque agent en aval à inclure cet identifiant dans ses sous-appels.
Cela nous permet de visualiser « Thought Stack »—un diagramme de Gantt temporel de la cognition. Nous pouvons constater que l'agent juridique a pris 45 secondes (problème de latence) alors que le comptable a pris 2 secondes.

Figure 3 : Diagramme de Gantt de cette opération de fusion et acquisition
Le dernier élément du protocole A2A est le Adaptateur universel.
Nous reconnaissons que les développeurs utiliseront toujours des outils différents. Certains adorent LangGraph pour son contrôle ; d'autres préfèrent CrewAI pour ses fonctionnalités de jeu de rôle.
Le Gateway agit comme Couche de traduction.
Cela vous permet de créer un Maille d'agents hétérogènes. Vous n'êtes pas bloqué dans une seule bibliothèque Python. Vous pouvez choisir le meilleur outil pour le travail de chaque agent spécifique et laisser le Protocole gérer la communication.
La standardisation est la condition préalable à la mise à l'échelle. Tout comme le protocole TCP/IP permettait à Internet de connecter différents ordinateurs, le Protocole A2A de plus, les fonctionnalités de passerelle d'agent TrueFoundry AI permettent à l'entreprise de connecter différentes intelligences. Il transforme une collection de « chatbots » en un outil coordonné, observable et sécurisé Main-d'œuvre numérique.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception






.png)

.webp)
.webp)
.webp)



.webp)
.webp)


