

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Au cours des derniers mois, nous avons eu l'occasion de travailler avec une équipe peu nombreuse. Ils ont développé un modèle d'apprentissage profond de pointe et créé des partenariats pour le proposer avec talent à plus de 10 millions d'utilisateurs.
La dernière pièce manquante de leur histoire d'impact était la gestion de l'ingénierie nécessaire pour y parvenir. Le modèle exigeait beaucoup de ressources de calcul et, à l'échelle nécessaire pour proposer ce modèle à ses utilisateurs finaux, ils avaient besoin d'une infrastructure fiable et performante qu'ils pouvaient gérer à deux (1 ingénieur DevOps et 1 ingénieur ML).
Le modèle a été conçu pour traiter des entrées audio de différentes tailles. Étant donné que le modèle avait un temps de traitement élevé (environ 5 secondes en moyenne), il avait besoin d'une inférence asynchrone pour chaque demande afin de traiter ces demandes et d'y répondre.
L'équipe a construit sa pile initiale pour servir le modèle sur Sagemaker. Cependant, lorsqu'ils ont réalisé leur premier projet pilote en utilisant cette conception, ils se sont rendu compte qu'il serait difficile de servir le modèle de manière fiable à l'échelle souhaitée avec cette pile.
Même après avoir utilisé la configuration asynchrone, étant donné que les instances mettaient du temps à évoluer (8 à 10 minutes par machine), l'expérience de l'utilisateur final était compromise lorsqu'il a dû supporter ce décalage.
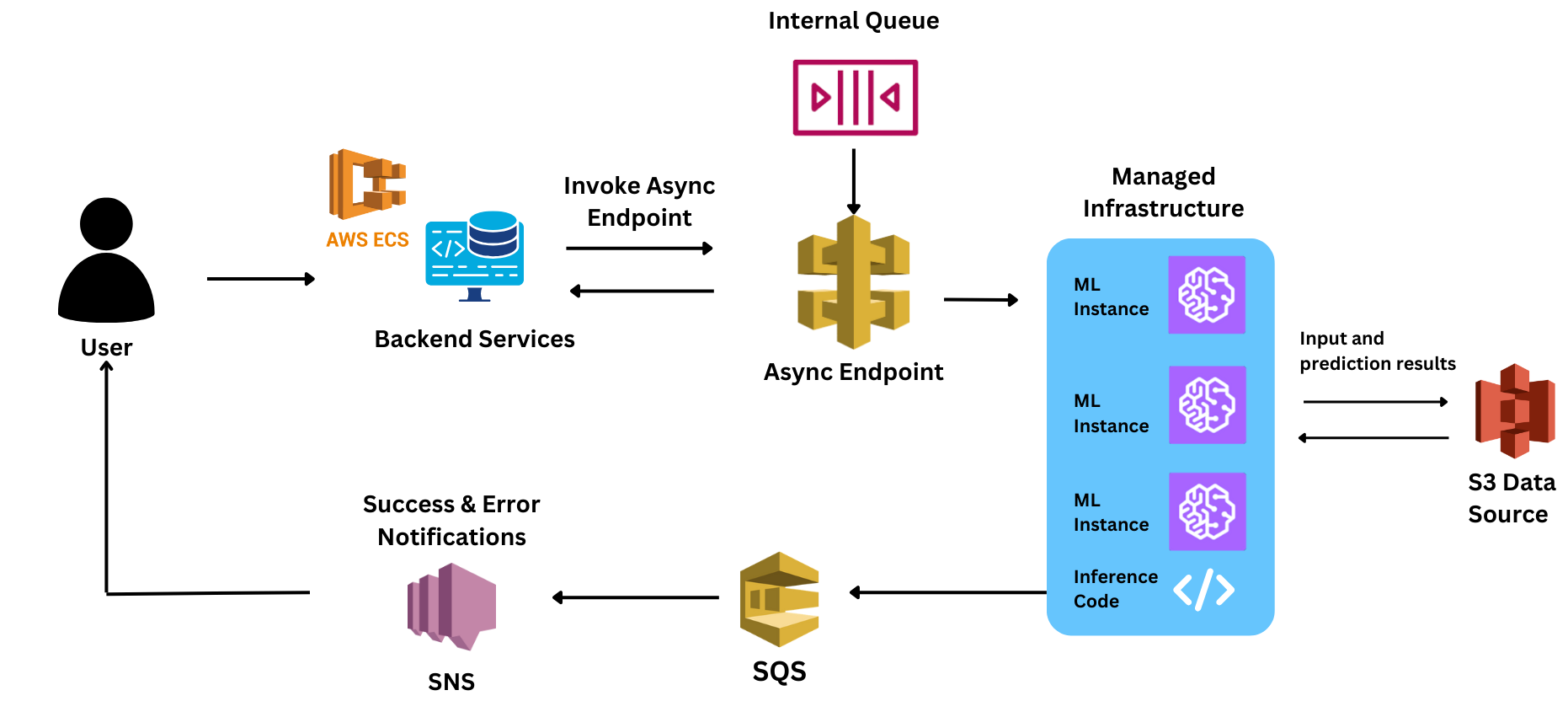
Cependant, pendant le PoC, ils ont dû faire face à d'énormes retards dans les temps de réponse. Comme la plupart des commandes liées à SageMaker étaient novices, ils ont perdu un temps critique pour trouver la raison de ces retards. Certains des défis auxquels ils ont été confrontés étaient les suivants :
Après le PoC, l'équipe a perdu confiance en Sagemaker et a décidé qu'elle avait besoin d'une solution que les deux (un ingénieur ML et un ingénieur DevOps) pourraient proposer à leur public cible de plus de 10 millions d'utilisateurs.
Lorsque nous avons commencé à collaborer avec l'équipe, leur projet pilote était dans environ 7 jours. Nous avons assuré à l'équipe que nous pouvions les aider à migrer l'ensemble de la pile et à la reconstruire à l'aide des modules TrueFoundry en moins de 2 jours, afin qu'ils aient suffisamment de temps pour tester avant que leur pilote ne passe en production.
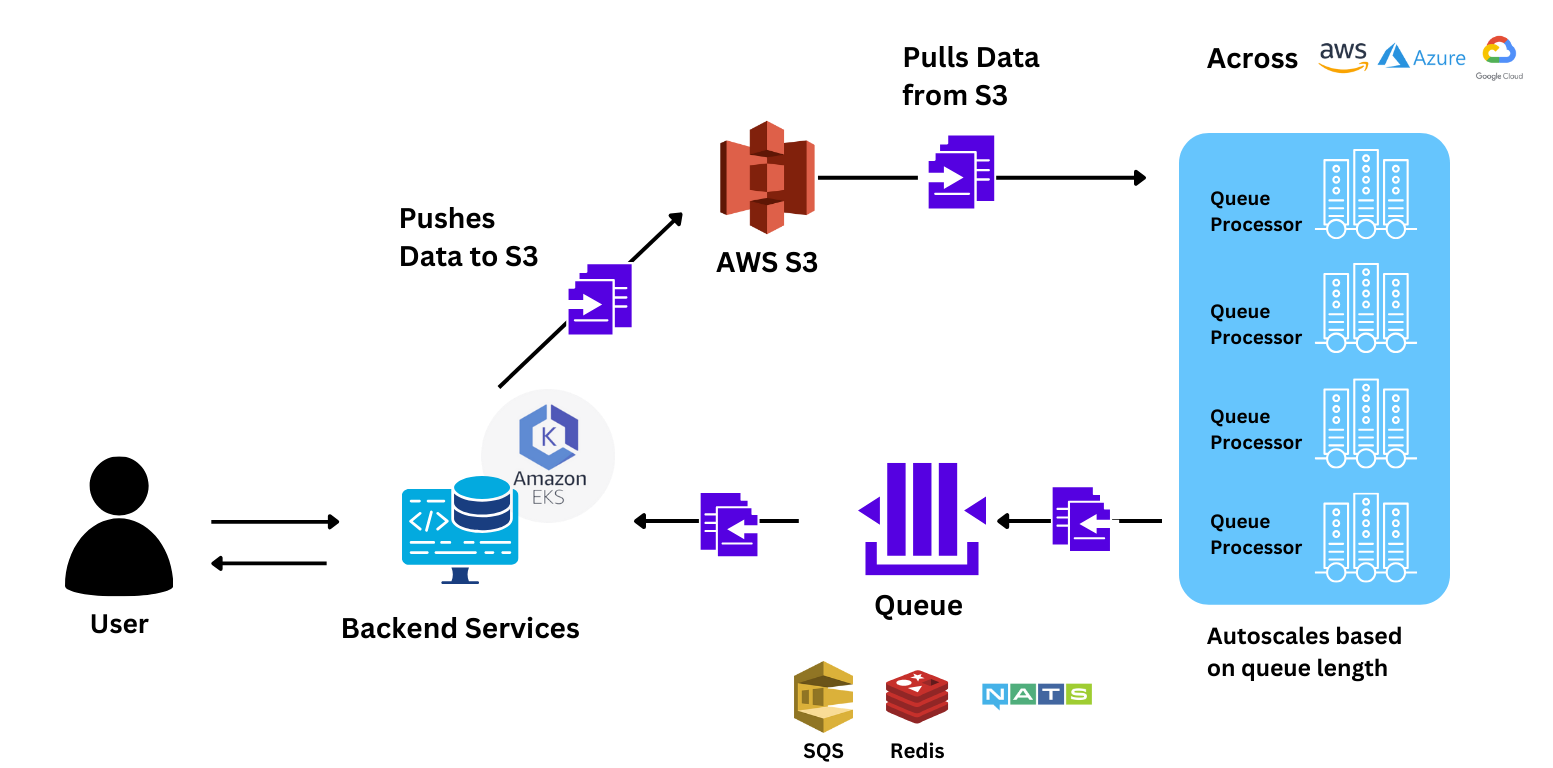
L'équipe a effectué des benchmarks en envoyant une rafale de 88 requêtes au modèle pour comparer les performances par rapport à Sagemaker. True Foundry à grande échelle 78 % plus rapide que Sagemaker, ce qui donne à l'utilisateur des réponses beaucoup plus rapides. Le le temps nécessaire pour répondre à la requête de bout en bout était 40 % plus rapide avec TrueFoundry.
L'équipe a simplement pu étendre l'application à plus de 150 nœuds GPU pour les raisons suivantes :
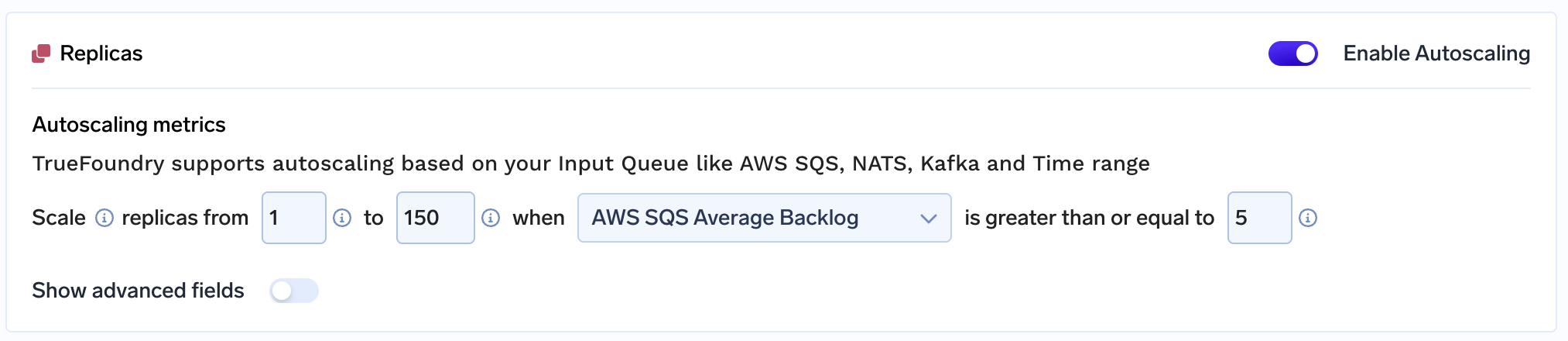

En utilisant True Foundry, les 2 membres de l'équipe peuvent gérer l'intégralité de leur charge de travail, qui s'étend souvent à plus de 150 nœuds GPU ! par eux-mêmes. En travaillant avec nous, l'élément le plus remarquable qui a retenu l'attention de l'équipe a été notre service client et nos faibles temps de réponse. TrueFoundry investit dans le succès de ses clients et espère que tous nos clients pourront évoluer et créer un impact à des échelles similaires à celles de ce projet !
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


