

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 27, 2026
%20(10).webp)
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!

En este ejemplo, entrenamos un modelo que puede clasificar una flor del género del iris en una de las tres especies según las medidas de tamaño de sus pétalos y sépalos.
También puedes seguir este ejemplo en Cuaderno colaboratorio de Google.
El Conjunto de datos Iris contiene tres especies diferentes:
Necesitamos construir un clasificador que pueda identificar la especie de la flor teniendo en cuenta los siguientes parámetros:
True Foundry proporciona dos bibliotecas para simplificar los flujos de trabajo de aprendizaje automático:
fundición ml la biblioteca se usa para rastrear los experimentos de entrenamiento de ML.
¿Por qué necesitas el seguimiento de los experimentos? Si está entrenando varios modelos de aprendizaje automático para resolver un problema, es probable que entrene varios modelos con varios marcos, hiperparámetros y varios conjuntos de datos. Haz un seguimiento de tu experimento con una biblioteca como fundición ml puede ayudarle a organizar sus experimentos de aprendizaje automático.
Puede usar MLFoundry para registrar hiperparámetros, métricas, conjuntos de datos y modelos. A continuación, puede comparar diferentes experimentos en Panel de control de TrueFoundry y elija un modelo para implementarlo en producción o decida volver a entrenar el modelo.
Usaremos 5 API diferentes de MLFoundry en este ejemplo. Son:
Uso del fundicion de servicio biblioteca, puede empaquetar, contenedorizar e implementar un modelo en un clúster de Kubernetes fácilmente.
Abra un cuaderno de IPython: puede usar Jupyter que se ejecuta localmente en su máquina o un cuaderno de Google Colab que se ejecuta en la nube.
Instale las bibliotecas necesarias.
Inicie sesión en TrueFoundry. Crea y copia una clave de API desde la página de configuración. Usa esta clave de API para inicializar el cliente de MLFoundry y crear una ejecución. Una ejecución es una entidad que representa un único experimento.
Obtenga el conjunto de datos de Iris utilizando el sklearn.datasets módulo. Luego lo dividimos en conjuntos de datos de prueba y entrenamiento.
Echemos un vistazo a los nombres de los objetivos. Usaremos esto para mapear desde el resultado entero del modelo hasta los nombres reales de las especies
Inicialice un modelo. A continuación, utilice MLFoundry para registrar los parámetros del modelo y crear algunas etiquetas para la ejecución del experimento actual.
A continuación, entrenamos el modelo en nuestro conjunto de datos de trenes. Una vez finalizada la capacitación, calculamos las distintas métricas y las registramos en MLFoundry utilizando log_metrics.
Si estamos satisfechos con las puntuaciones de precisión y otras métricas, podemos optar por implementar el modelo actual. Para ello, necesitamos guardar el modelo y copiar el identificador de ejecución actual.
Puedes ver todas tus carreras y comparar las métricas a través del Panel de seguimiento de experimentos de TrueFoundry.

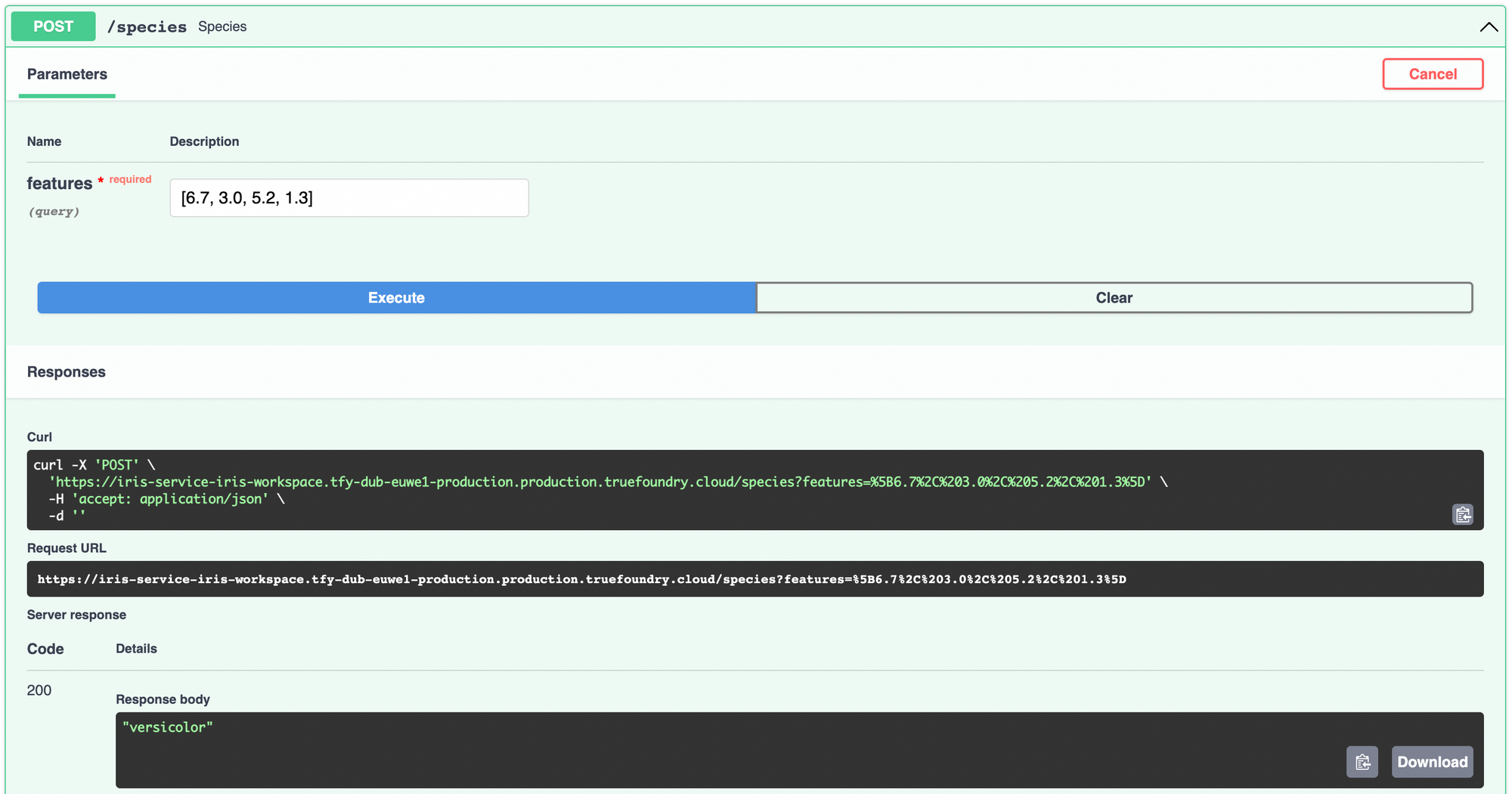
Para implementar el modelo usando ServiceFoundry, necesitamos crear un archivo Python que contenga la función que queremos exponer como punto final.
Dentro de ese archivo de Python, buscaremos el modelo que acabamos de entrenar y guardar usando el identificador de ejecución, usando fundición ml. Tenga en cuenta que la clave de API es requerida por fundición ml estará disponible como variable de entorno TFY_API_KEY.
En su bloc de notas de IPython, cree un bloque con el siguiente contenido y ejecútelo para crear un archivo de Python llamado predict.py. Usamos el comando mágico de Jupyter %s escribir archivo para crear el archivo en el entorno del bloc de notas.
Dentro de la función de especie, cargamos las características en un pandas DataFrame y haga la predicción utilizando el modelo. Traducimos de la clase entera a los nombres de las especies utilizando el nombres_objetivo imprimimos durante el entrenamiento.
Eso es prácticamente todo el trabajo que tendrás que hacer. Ahora vamos a implementar este modelo como un servicio de API. En primer lugar, instale e importe fundicion de servicio en tu cuaderno. Inicie sesión en fundicion de servicio.
Ir a la Panel de control de TrueFoundry y cree un espacio de trabajo para implementar el servicio. Los espacios de trabajo son una forma de agrupar proyectos relacionados dentro de TrueFoundry. Una vez creado el espacio de trabajo, copia el FQN para que podamos saberlo fundicion de servicio dónde implementar el modelo.

fundicion de servicio la biblioteca te permite recopilar todas las dependencias del archivo que acabas de crear usando recopilar requisitos función.
Ahora crea un Servicio SFY objeto, proporcione el FQN del espacio de trabajo e impleméntelo llamando .implementar ()
Puede realizar un seguimiento del progreso de esta implementación en la salpicadero. Una vez finalizada la implementación, puede acceder al servicio desplegado desde allí y probarlo.
El panel de TrueFoundry también enlaza con las métricas y los registros que vienen listos para usar con las implementaciones de TrueFoundry en forma de paneles de Grafana. Puedes leer más sobre ellos aquí.

También puede implementar aplicaciones de interfaz de usuario interactivas y aplicaciones de Gradio fácilmente desde un cuaderno IPython mediante fundicion de servicio. Lee esto guía para ver cómo.
Estamos trabajando para que la integración entre el seguimiento y el despliegue de los experimentos sea aún más estrecha y que la experiencia sea más agradable. Puedes leer sobre otras cosas que puedes hacer con TrueFoundry en nuestros documentos.Si está entrenando modelos de aprendizaje automático para resolver un problema, TrueFoundry lo ayuda a realizar un seguimiento de diferentes experimentos y hace que sea fácil e intuitivo implementar modelos con las mejores prácticas y ponerlos a disposición del público en cuestión de minutos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


