

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 27, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La plataforma de Vercel, especialmente su SDK de IA y un solo clic implementar en modo push El flujo de trabajo facilita a los equipos de frontend la puesta en marcha de demostraciones de IA en cuestión de minutos. El Vercel AI SDK es un conjunto de herramientas gratuito y de código abierto que permite a los equipos ofrecer funciones de IA con rapidez.
Sin embargo, los precios de Vercel se diseñaron originalmente para sitios estáticos y funciones web de corta duración. Cuando la carga de trabajo de inteligencia artificial de una aplicación se alarga (por ejemplo, cuando se transmiten las respuestas de los agentes en varios pasos o se canalizan muchos procesos de RAG), el modelo de precios de Vercel AI cambia radicalmente.
En lugar de tarifas mensuales fijas, comienza a pagar por milisegundos de tiempo de ejecución sin servidor y gigabytes de datos transferidos. En la práctica, los equipos se dan cuenta de que sus facturas predecibles de 20 dólares al mes aumentan considerablemente a medida que los chatbots y los agentes alcanzan los límites de recursos de Vercel.
Esta guía explica cómo funcionan los precios de Vercel AI, en qué tarifas ocultas incurren las cargas de trabajo de IA y por qué los equipos de ingeniería finalmente migran a plataformas de nube privada como TrueFoundry para evitar estos costos.
Para obtener más información sobre Puerta de enlace de IA panorama y consideraciones a tener en cuenta antes de elegir un proveedor, lea la información completa La guía de mercado de Gartner para AI Gateways 2025 está aquí.
.webp)
Vercel ahora usa un modelo híbrido combinar los asientos de usuario con las cuotas de uso y los cargos por exceso de uso. En pocas palabras: el uso por parte de aficionados es gratuito, pero los costes de uso profesional aumentan con el tamaño del equipo y las necesidades informáticas. A continuación se muestra un resumen de cada nivel y sus implicaciones para las aplicaciones de IA.
El Pasatiempo plan es «el punto de partida perfecto para su aplicación web o proyecto personal» y es gratis para siempre. Está estrictamente limitado al uso personal y no comercial; el uso empresarial o generador de ingresos del plan Hobby infringe las condiciones de Vercel. Hobby incluye funciones generosas (CDN, 1 millón de solicitudes perimetrales al mes, WAF simple) pero unos límites de procesamiento muy estrictos. En concreto, las funciones de Hobby solo pueden ejecutarse durante un máximo de 60 segundos (predeterminado), porque el duración de la función tiene un límite (y solo se puede ajustar ligeramente) en los planes gratuitos. Las aplicaciones de IA suelen necesitar transmitir las respuestas o ejecutar bucles de agentes de más de un minuto. En Hobby, estas largas tareas son sencillas tiempo de espera con 504 errores. En resumen, si tu demostración de IA necesita algún cálculo continuo (por ejemplo, una consulta compleja o una búsqueda vectorial), es probable que Hobby interrumpa el proceso antes de que llegue el resultado. En la práctica, los equipos descubren que incluso las llamadas de LLM o las cadenas de agentes de LLM moderadamente complejas superan los límites de duración de Hobby. Esto hace que el nivel gratuito sea adecuado para prototipos y experimentos ligeros, pero no es adecuado para cargas de trabajo de IA de producción que requieren salidas de procesamiento o streaming ampliadas.
El Pro el plan comienza en 20$ por usuario que realiza la implementación al mes. (Cada puesto de desarrollador cuesta 20$ al mes; puedes añadir asientos de «espectador» gratuitos e ilimitados). Pro convierte esas cuotas de afición en límites más altos, pero con un coste. Por ejemplo, Pro incluye 1 TB de ancho de banda al mes (con un valor aproximado de 350 dólares), diez veces más que los 100 GB incluidos en Hobby. Más allá de ese 1 TB, el tráfico saliente se factura al precio 0,15 USD POR GB. Pro también aumenta la función compute incluida: por defecto te mueves 1000 GB-hora de ejecución sin servidor al mes (en todas las funciones) (aproximadamente lo que consumiría un desarrollador que ejecutara tareas pequeñas) antes de pagar más.
Sin embargo, las cargas de trabajo de la IA superan esos límites con extrema rapidez. Cada transmisión abierta o inferencia larga consume memoria y tiempo de CPU. En la práctica, los desarrolladores informan que agotan las cuotas de Pro en cuestión de días: un ejemplo mostró que un servicio de capturas de pantalla desplegado utilizaba 494 GB-hora en solo 12 días de probar, proyectar 1276 GB-hora en un mes. Como Vercel factura según el tiempo de ejecución, los 1276 GB de horas de ese trabajador incurrirían en una 160$ extra al mes (aproximadamente 0,18 USD por GB-hora) más allá del plan base. En resumen, el coste de la IA de Vercel en el plan profesional puede ascender fácilmente a cientos o miles una vez que empieces a hacer transmisiones de IA de larga duración, a realizar grandes cantidades de RAG o a transferir grandes cantidades de datos.
Conclusiones clave para Pro: it poder admiten aplicaciones de producción, pero cada desarrollador que añadas cuesta más de 20$ al mes, y un uso impredecible (streaming de IA, modelos grandes) puede generar promedios elevados. Los créditos gratuitos incluidos solo aplazan la facturación; la transmisión de respuestas de 45 segundos significa que los servidores permanecen activos durante 45 segundos, lo que supone un coste 45 veces mayor que una llamada a la API de 1 segundo.
El nivel Enterprise está personalizado y está dirigido a grandes organizaciones. Oficialmente, los detalles se indican entre comillas, pero en la práctica, la entrada empieza por alrededor 25 000$ al año para funciones básicas.
Este nivel desbloquea herramientas avanzadas de cumplimiento y escalado, como:
Por ejemplo, solo el contrato Enterprise obtiene cientos de ranuras de reglas de WAF (hasta 1000 reglas de bloqueo de IP). En cuanto a los precios de Vercel AI, Enterprise elimina algunos límites de uso y permite funciones más amplias, pero se mantienen las tasas de datos y memoria por gigabyte por hora.
Muchas empresas emergentes consideran que el salto de Pro a Enterprise es un «precipicio», ya que las funciones adicionales están orientadas a la empresa, pero el precio es un orden de magnitud superior. Como señaló un desarrollador, el nivel Pro puede ser «todo lo que necesitas», pero el coste a gran escala depende del uso, no de la licencia.
Los precios de Vercel AI están optimizados para las aplicaciones web (muchas solicitudes breves y sin estado). Las aplicaciones de IA se comportan de manera diferente. El principales impulsores de costos para la IA en Vercel son: ejecución duración, datos salida, y concurrencia restricciones.
En Vercel, pagas por cada milisegundo de una función activo. La espera inactiva para la E/S o la transmisión cuenta como tiempo facturable. Los documentos declaran explícitamente: «La duración de la función genera facturas en función del tiempo total de ejecución de una función de Vercel».. Para una llamada normal a la API web (10 a 100 ms), esto es insignificante, pero un chat de LLM puede reproducirse durante 30 a 60 segundos. En ese caso, una sola solicitud puede costar muchísimo más.
Considere un escenario típico:
Una función perimetral de Next.js abre una respuesta de transmisión en el navegador hasta que finalice el LLM. Durante esa transmisión, la instancia sin servidor permanece ocupada todo el tiempo, lo que implica una facturación continua de la memoria (y parte de la CPU). En la práctica, los equipos han informado de un uso sorprendentemente elevado. En un caso práctico, un desarrollador migró un servicio pesado de capturas de pantalla de Puppeteer a Vercel. El plan Pro incluía 1000 GB por hora, pero en 12 días ese servicio ya se había agotado 494 GB-hora. Extrapolado a un mes completo, eso es 1276 GB-hora, es decir, aproximadamente 160$ de cargos adicionales de Vercel para esa única función. (Al final, ese desarrollador se cambió a AWS Lambda porque la misma carga de trabajo en AWS solo era de unos 101 GB de horas/mes).
La lección: Las transmisiones prolongadas de IA son fundamentalmente «pesadas» para la facturación sin servidor. Una respuesta de chat de un minuto podría consumir entre 20 y 50 MB de memoria durante 60 segundos, con un coste aproximado de 0,001 USD por solicitud. Multiplique esa cantidad por el uso intensivo y se acumulará rápidamente.
Las aplicaciones de IA suelen incluir la generación aumentada de recuperación (RAG) o canalizaciones de datos que mueven megabytes de texto e incrustaciones. Cada vez que su función de Vercel recupera un documento o modelo de un almacén remoto, esos datos salen de la red de Vercel.
El uso intensivo de RAG significa grandes excedentes. Por ejemplo, recuperar un documento de 100 MB diez veces consumiría 1 GB de ancho de banda. Si una canalización de RAG distribuye cientos de gigabytes al mes, eso podría suponer cientos de dólares para la factura.
En resumen, las cuotas de ancho de banda de Vercel parecen generosas para el tráfico web normal, pero las aplicaciones de IA que habitualmente envían grandes cargas útiles o incrustan lotes las superarán rápidamente y generarán costosos excedentes.
Las funciones de Vercel se escalan automáticamente hasta un punto, pero hay límites. De forma predeterminada, la plataforma permite hasta unas 30 000 ejecuciones simultáneas en Hobby/Pro (y más de 100 000 en Enterprise). En el caso de la mayoría de las aplicaciones, esta cifra parece elevada, pero las cargas de trabajo de la IA pueden impulsar la concurrencia de formas inesperadas.
Por ejemplo, un servicio de chat de IA puede abrir docenas de transmisiones de funciones simultáneas para muchos usuarios a la vez. Una vez que alcanzas el límite de concurrencia, las nuevas solicitudes se ponen en cola o se limitan. En ese momento, tendrás que actualizar (por ejemplo, Enterprise) o implementar un escalado externo.
De hecho, Vercel pone un límite a las ráfagas de tráfico de IA, a menos que pagues mucho más. Como anécdota, los equipos han visto cómo los chatbots empezaban a fallar (errores 504/429) durante los picos de tráfico, porque el grupo subyacente sin servidor estaba saturado.
.webp)
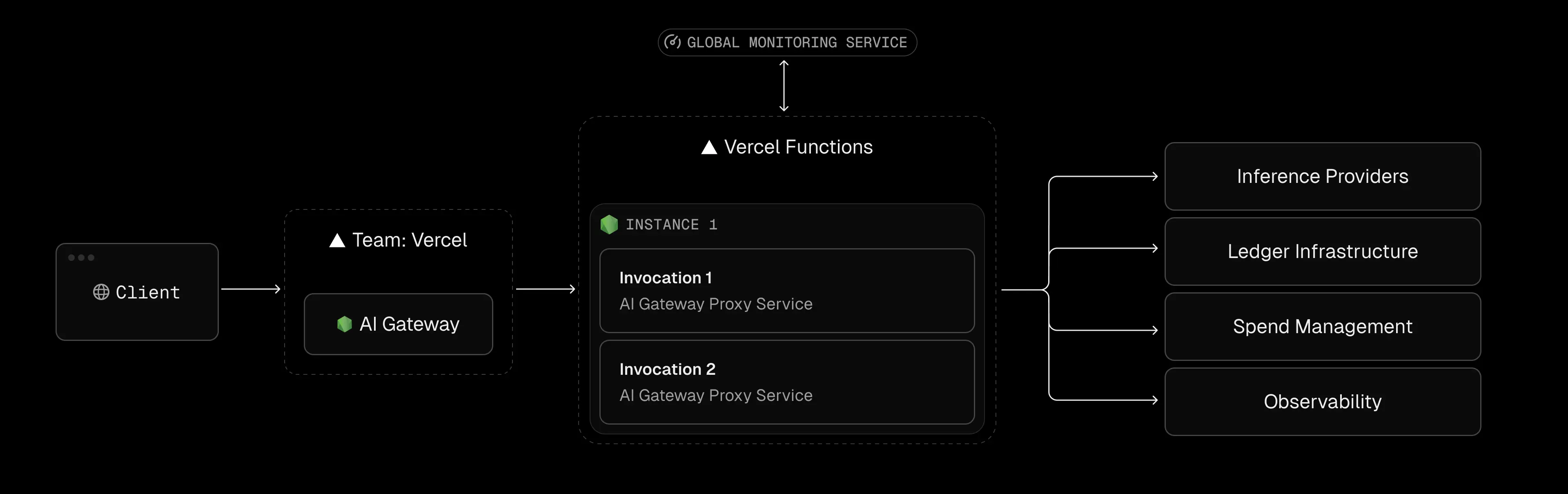
Un error común es que usar el Vercel SDK AI lo obliga a acceder a la infraestructura de Vercel. En realidad, el SDK de IA es solo un conjunto de herramientas (de código abierto, gratuito) para crear funciones de IA en next.js/TypeScript.
Puedes usar el SDK para dirigirte a cualquier proveedor de LLM, incluidos los modelos autohospedados, lo cual es una consideración importante a la hora de comparar Puerta de enlace Vercel AI frente a OpenRouter para la flexibilidad de los proveedores y el control de costos. Hay sin requisito para ejecutar su código en los servidores de Vercel. De hecho, la mayoría de las partes del SDK (componentes de la interfaz de usuario, proveedores, bibliotecas cliente) funcionan en cualquier lugar. Por ejemplo, un equipo podría almacenar en contenedores su aplicación Next.js con el SDK de IA e implementarla en Kubernetes (EKS/GKE) o en cualquier máquina virtual en la nube. El código no «sabe» que proviene de Vercel.
Por qué los equipos se quedan estancados:
Por lo general, por conveniencia. El alojamiento de Vercel se integra perfectamente con el SDK: tú confirmas el código y Vercel crea, implementa e incluso proporciona una pestaña AI Gateway integrada. Muchos equipos presionan «Implementar en Vercel» de forma predeterminada.
La desventaja es que la comodidad oculta el modelo de costos sin servidor. Los ingenieros pueden crear prototipos con Vercel sin saber que cada modelo de llamada se factura según las tarifas de Vercel (a menudo más altas) sin servidor, hasta que llegue la factura.
A medida que crecen los proyectos de IA impulsados por Vercel, surgen varios puntos problemáticos operativos junto con los problemas de precios de Vercel AI:
Incluso en los planes de pago, Vercel impone límites de ejecución estrictos. De forma predeterminada, las funciones HTTP en Pro agotan su tiempo de espera después 5 minutos (configurable hasta 13 minutos con «Fluid Compute»). En Hobby, son solo 60 segundos.
En la práctica, cualquier agente de IA o flujo de trabajo de investigación que se ejecute durante más de unos minutos morirá. Por ejemplo, un agente de varios pasos que necesite entre 10 y 15 minutos para consultar bases de datos, resumir documentos y emitir un informe superará de forma fiable el límite y fallará.
Los equipos informan de errores 504 frecuentes en sus tareas de IA una vez que superan estos límites. Por el contrario, en su propia infraestructura de nube, puede permitir que las funciones o los contenedores se ejecuten indefinidamente (o al menos durante horas) según sea necesario.
El middleware perimetral de Vercel (como Next.js Edge Functions) puede mejorar el rendimiento, pero viene con bloqueo.
En la práctica, los equipos a veces incorporan una lógica crítica en Edge Functions para aumentar la velocidad, solo para encontrar la migración fuera de Vercel se convierte en una reescritura importante.
Actualmente, Vercel no tiene instancias de GPU nativas para cargas de trabajo de IA. Esto significa que cualquier trabajo de inferencia o incrustación de modelos que necesite acelerarse debe realizarse fuera de la plataforma.
Los equipos suelen terminar alojando modelos tipo GPT o búsquedas vectoriales en AWS/GCP/Render/Azure con GPU, y luego los llaman desde las funciones de Vercel. Esta configuración dividida añade latencia (cada llamada salta a un servicio externo) y complejidad operativa.
Por el contrario, una infraestructura basada en Kubernetes (como TrueFoundry) puede ejecutar código web únicamente para CPU e inferencias de GPU en paralelo en el mismo clúster, lo que elimina esa fragmentación.
A pesar de estas advertencias, Vercel no es una mala elección para algunos Escenarios de IA. Sus puntos fuertes brillan cuando:
En resumen: Los precios de Vercel AI funcionan bien para las aplicaciones de front-end que utilizan la IA a la ligera, o para equipos que valoran el tiempo de comercialización por encima de todo. El punto de equilibrio llega cuando las cargas de trabajo de la IA se convierten en partes «reales» de la aplicación, y no solo en demostraciones novedosas. Es entonces cuando los costos se vuelven difíciles de predecir.
.webp)
A medida que las funciones de IA se vuelven fundamentales para el producto, muchos equipos llegan a un punto de inflexión y buscan alternativas. TrueFoundry se posiciona como una solución que ofrece la facilidad de no tener servidores con la economía de la nube sin procesar. A continuación se muestra una comparación de los factores clave de las cargas de trabajo de la IA:
¿Qué significa esto en la práctica? Muchos equipos descubren que sus facturas mensuales en Vercel aumentan de forma desproporcionada en comparación con su cálculo real. En un ejemplo real, un servicio consumió aproximadamente 1276 GB por hora en Vercel (aproximadamente 2000 USD al año), pero solo 101 GB por hora en AWS Lambda sin procesar (capa gratuita) para la misma carga. En pocas palabras, las cargas de trabajo de IA equivalentes pueden ser mucho más baratas en una infraestructura de nube autogestionada. Con TrueFoundry, tu factura consiste básicamente en computación en nube «estándar» (EC2, nodos de GKE, etc.) más una tarifa de plataforma, en lugar del multiplicador que impone la tecnología sin servidor.
.webp)
TrueFoundry ofrece un enfoque híbrido: usted mantiene el modelo sin servidor, fácil de usar para desarrolladores (escalado automático, API simples), pero lo ejecuta en su propia cuenta en la nube. Los aspectos clave incluyen:
TrueFoundry le permite implementar Next.js (y cualquier otra aplicación) como servicios Docker estándar en Kubernetes (EKS, GKE o AKS) en su propia cuenta en la nube. Como explica un blog, «TrueFoundry facilita enormemente la implementación de aplicaciones en clústeres de Kubernetes en su propia cuenta de proveedor de nube».. Bajo el capó, tus puntos finales de Next.js se ejecutan en los pods/nodos que tú controlas.
Esto significa que se le factura en tasas brutas de nube para CPU y memoria, sin una prima oculta sin servidor. Un WebSocket inactivo o una transmisión abierta siguen consumiendo RAM en el nodo, pero esa RAM tiene un precio inferior al de un GB por hora sin servidor.
Dado que administras los nodos de Kubernetes, controlas los tiempos de espera y la vida útil de las funciones. Puedes ejecutar módulos o tareas de larga duración durante minutos u horas, según sea necesario. TrueFoundry no impone un límite de 5 o 15 minutos, sino su infraestructura.
Las complejas canalizaciones de agentes y las tareas de investigación simplemente se completan (solo están sujetas a la vida útil máxima normal del pod, si la hubiera). Esto elimina el problema más común de Vercel: los errores 504 a mitad de camino. Si un agente de IA necesita 20 minutos para terminar, puede hacerlo en TrueFoundry; en Vercel, habría fallado a los 5 minutos.
Una de las principales ventajas de TrueFoundry para IA es la compatibilidad con GPU integrada. Como es Kubernetes en secreto, puedes conectar grupos de nodos de GPU y programar las cargas de trabajo de inferencia junto con tus servicios web. Esto significa que tus API de front-end y tus inferencias intensivas de aprendizaje automático pueden ejecutarse en el mismo clúster (lo que reduce la latencia y la transferencia de datos). De hecho, la arquitectura nativa de la nube de TrueFoundry de forma explícita «nos permite tener acceso a los diferentes tipos de hardware proporcionados por los diferentes proveedores de nube, especialmente en el caso de las GPU».
En la práctica, esto significa que puede ejecutar la inferencia de LLM o la generación de incrustaciones en nodos acelerados por GPU sin salir de la plataforma. No es necesario conectar un servicio de GPU independiente (ni pagar por el tráfico interregional).
Vercel sigue siendo una plataforma excelente para la entrega de frontend. Pero tan pronto como la IA computa desde el backend, la economía cambia. La conclusión clave: evite pagar la prima basada en la duración de Vercel por tareas pesadas de IA.
A diferencia del tráfico HTTP simple, los backends de IA suelen funcionar durante mucho más tiempo por solicitud y mueven muchos datos. Según el modelo de precios de Vercel AI, eso significa pagar por cada segundo de procesamiento y cada gigabyte disponible. Por el contrario, con TrueFoundry pagas por los nodos sin procesar y los segundos de tiempo de actividad, el mismo modelo de costes que utilizarías si utilizaras un contenedor en EC2 o GKE.
El resultado final son unos costes de escalado más fluidos. Los equipos descubren que su gasto mensual aumenta linealmente con el cálculo real utilizado, no con cada milisegundo de tiempo de función. En muchos casos, lo que les cuesta cientos de dólares al mes en Vercel puede hacerse por decenas en su propia nube.
Si tu equipo se enfrenta a un aumento vertiginoso de las facturas de Vercel o se esfuerza constantemente por perder tiempo muerto, vale la pena considerar un cambio de infraestructura. True Foundry está diseñado para permitirle mantener la productividad de los sistemas sin servidor (implementaciones sencillas, escalado) y, al mismo tiempo, eliminar las penalizaciones. Una demostración rápida puede mostrar cómo trasladar la carga de trabajo de la IA a TrueFoundry puede reducir los costos sin sacrificando la velocidad.
Reserve una demostración rápida para saber cómo trasladar la carga de trabajo de la IA a TrueFoundry puede reducir los costes sin sacrificar la velocidad.
El Vercel AI Gateway ofrece una nivel gratuito. Todas las cuentas del equipo de Vercel reciben 5$ de créditos de AI Gateway cada mes una vez que hagas tu primera solicitud. Puedes seguir usando este crédito gratuito de forma indefinida (se actualiza cada 30 días) para experimentar con los LLM a través de Vercel. Más allá de eso, pasarás al sistema de pago por uso y tendrás que comprar créditos adicionales. Ten en cuenta que este crédito de 5$ es solo para el uso de la pasarela; es cierto no cubre los costos de ancho de banda o procesamiento de tu función en la plataforma, que se facturan por separado en el plan de tu cuenta.
El nivel Hobby de Vercel es libre para proyectos personales. El Pro el plan comienza en 20$ por puesto de desarrollador al mes, además de cualquier complemento basado en el uso. En la práctica, un pequeño equipo de 3 desarrolladores paga aproximadamente 60 dólares al mes. Si necesitas más funciones (inicio de sesión único, tiempo de actividad garantizado, etc.), el nivel Enterprise comienza en un rango de cinco cifras al año. Además de esas tarifas básicas, pagas los GB por hora adicionales, las solicitudes periféricas y la transferencia de datos de acuerdo con las tarifas de uso de Vercel.
El Plan de 20$ se refiere a Vercel's Nivel Pro (a veces llamada simplemente «cuenta Pro»), que cuesta 20 dólares por usuario al mes. Incluye todas las funciones de Hobby, además de herramientas de colaboración en equipo y cuotas más altas. Por ejemplo, la versión Pro incluye 1 TB de ancho de banda perimetral al mes y una asignación mayor de GB por hora para funciones. Si un equipo Pro supera esas cuotas, el uso adicional se factura según las tarifas de excedentes de Vercel. En resumen, el plan de 20 dólares es el plan básico de pago para equipos profesionales (más allá del nivel Hobby gratuito).
La plataforma de Vercel tiene varias restricciones que afectan a las aplicaciones de IA. De forma predeterminada, las funciones sin servidor se agota rápidamente (60 a 300 segundos en Hobby/Pro). Las respuestas de la IA en streaming cuentan como tiempo completo de actividad, por lo que las consultas largas se vuelven costosas. Hay límites estrictos en cuanto a la concurrencia y al tamaño de la carga útil de las solicitudes (máximo 4,5 MB). Además, Vercel sí no es compatible con las GPU, por lo que cualquier inferencia de modelo pesada debe ejecutarse fuera de la plataforma. El propio AI Gateway solo tiene un crédito gratuito de 5$ al mes; aparte de eso, pagas los precios de lista de los proveedores por los tokens. En la práctica, los equipos de Vercel informan de 504 errores inesperados, facturas elevadas por GB por hora y bloqueos arquitectónicos en el entorno periférico de Vercel si se vuelven demasiado dependientes de él. Por estos motivos, las cargas de trabajo avanzadas de IA suelen llegar a su límite en Vercel y provocar una migración a plataformas como TrueFoundry.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


