Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
Evaluación comparativa del TrueFoundry LLM Gateway: es increíblemente rápido ⚡
TrueFoundry LLM Gateway proporciona una interfaz unificada compatible con OpenAI para varios proveedores de LLM como Anthropic, OpenAI, Bedrock, Gemini y muchos otros
TrueFoundry LLM Gateway se amplía sin problemas hasta 350 RPS en una sola réplica de 1 unidad de CPU y utiliza 270 MB de memoria. Lo comparamos con otro producto de puerta de enlace, LitellM, que tenía una configuración similar y LitellM no pudo escalar más allá de los 50 RPS
TrueFoundry LLM Gateway solo agrega una latencia adicional de 3 a 5 ms, mientras que LitELLM agrega entre 15 y 30 ms por solicitud.
¿Por qué su organización necesita un LLM Gateway?
Una pasarela de LLM proporciona una interfaz unificada para administrar el uso de LLM de su organización:
API unificada: Acceda a varios proveedores de LLM a través de un solo Compatible con OpenAI interfaz, no es necesario cambiar el código
Seguridad de claves de API: Administración de credenciales segura y centralizada
Gobernanza y control: Establezca límites, controles de acceso y filtrado de contenido
Limitación de velocidad: Prevenir el abuso y garantizar un uso justo
Observabilidad: Realice un seguimiento del uso, los costos, la latencia y el rendimiento
Equilibrio de carga: Dirige automáticamente las solicitudes entre los proveedores
Administración de costos: Supervise los gastos y establezca alertas presupuestarias
Registros de auditoría: Registra todas las interacciones de LLM para garantizar el cumplimiento
¿Qué tan rápido es TrueFoundry LLM Gateway?
Configuración de la prueba de carga
Para nuestro experimento de prueba de carga, configuramos una implementación de esto servicio de punto final falso de OpenAI usando TrueFoundry. El servicio simularía el formato de solicitud y respuesta de OpenAI sin producir realmente tokens.
También implementamos el TrueFoundry LLM Gateway y el servidor proxy LitELLM, ambos ejecutados en una única réplica con 1 unidad de CPU y 1 GB de memoria.
Añadimos nuestro proveedor falso de OpenAI a las pasarelas TrueFoundry y LitellM. Durante las pruebas de carga, realizamos solicitudes al servidor falso de OpenAI de tres maneras diferentes:
Configuración 1: Directamente sin usar ningún proxy o puerta de enlace
Configuración 2: A través de la puerta de enlace LLM de TrueFoundry implementada en 1 unidad de CPU y 1 GB de memoria
Configuración 3: A través del servidor proxy LitellM implementado en 1 unidad de CPU y 1 GB de memoria
RPS
10 RPS
50 RPS
200 RPS
300 RPS
OpenAI direct (Setup 1)
73 ms
73 ms
73 ms
73 ms
TrueFoundry LLM Gateway (Setup 2)
76 ms (+3 ms)
76 ms (+3 ms)
76 ms (+3 ms)
77 ms (+4 ms)
LiteLLM Proxy (Setup 3)
88 ms (+15 ms)
99 ms (+26 ms)
Could not scale to 200 RPS
Could not scale to 300 RPS
Observaciones
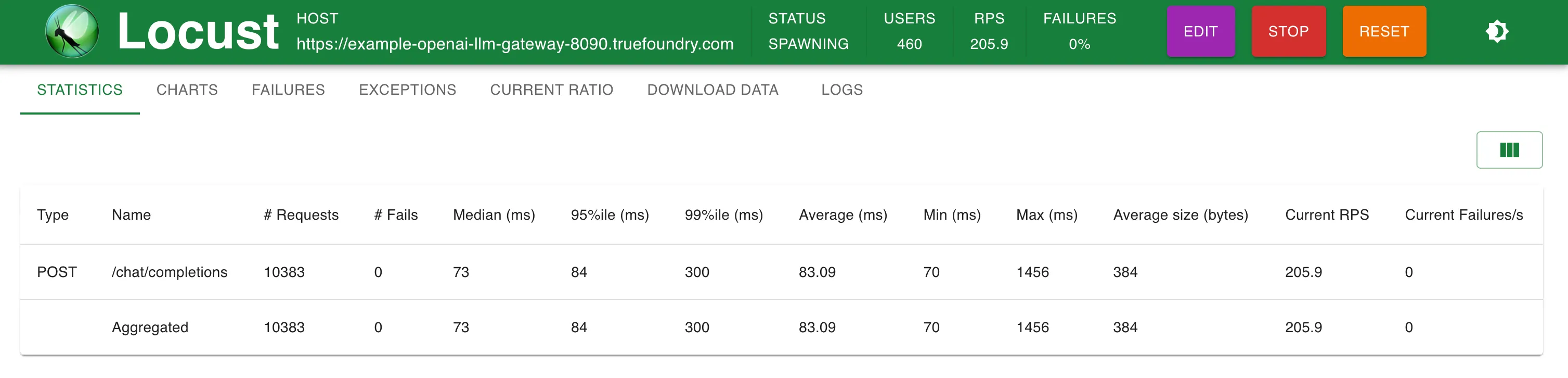
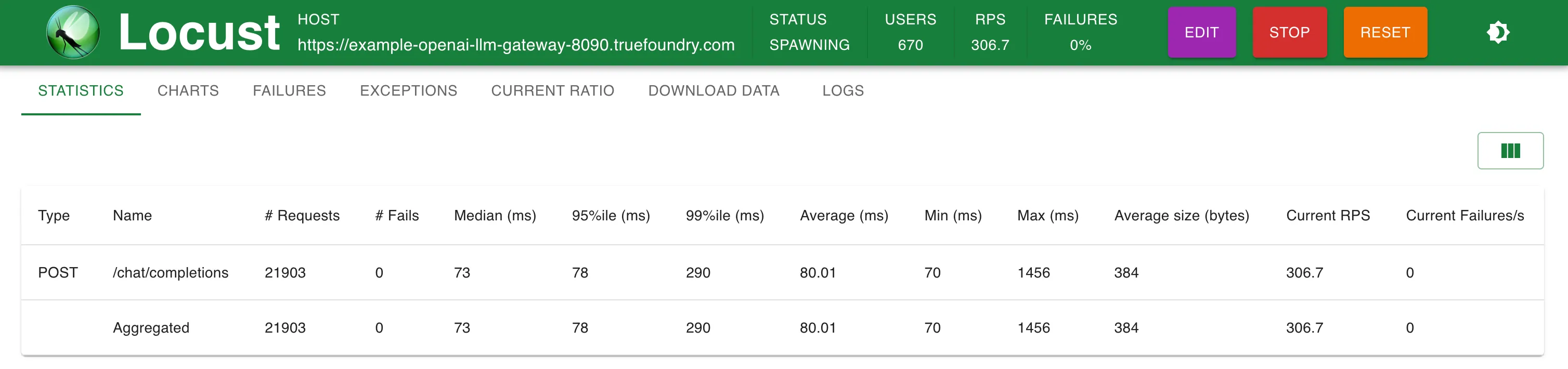
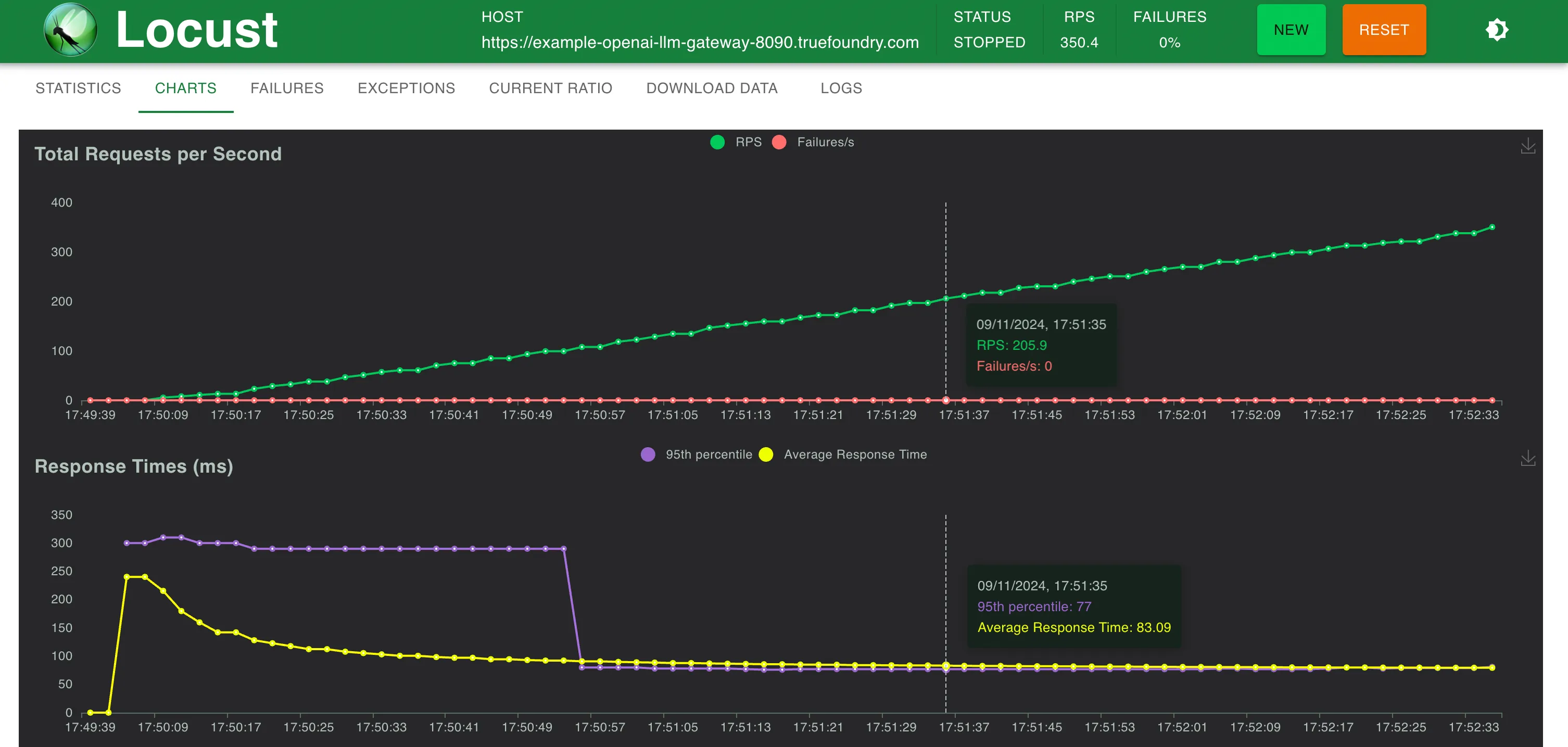
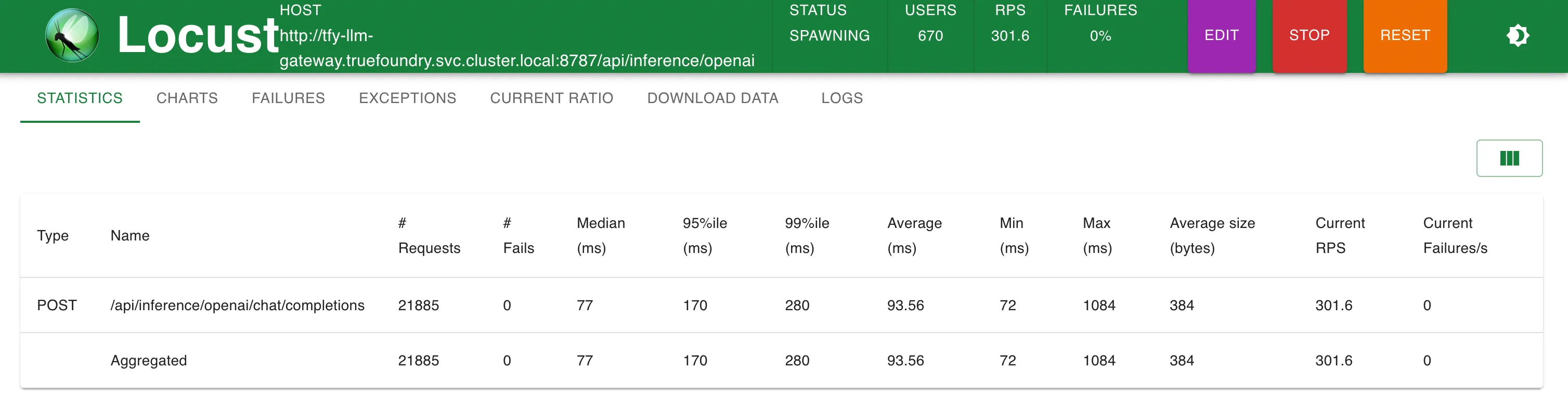
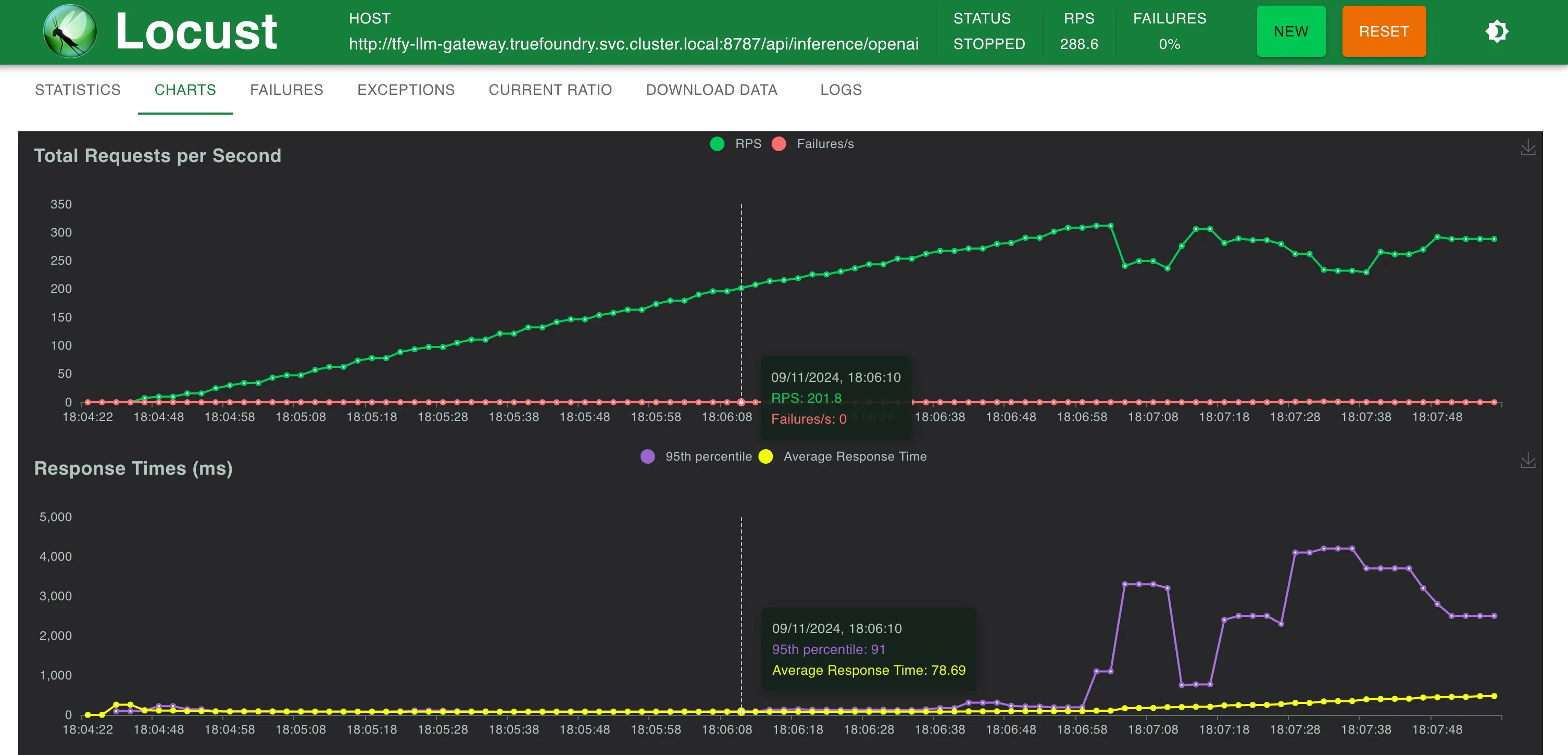
TrueFoundry Gateway agrega solo 3 ms adicionales de latencia hasta 250 RPS y 4 ms a RPS > 300
TrueFoundry LLM Gateway pudo escalar sin ninguna degradación en el rendimiento hasta aproximadamente 350 RPS (1 vCPU, máquina de 1 GB) antes de que la utilización de la CPU alcanzara el 100% y las latencias empezaron a verse afectadas. Con más CPU o más réplicas, el LLM Gateway puede escalar a decenas de miles de solicitudes por segundo.
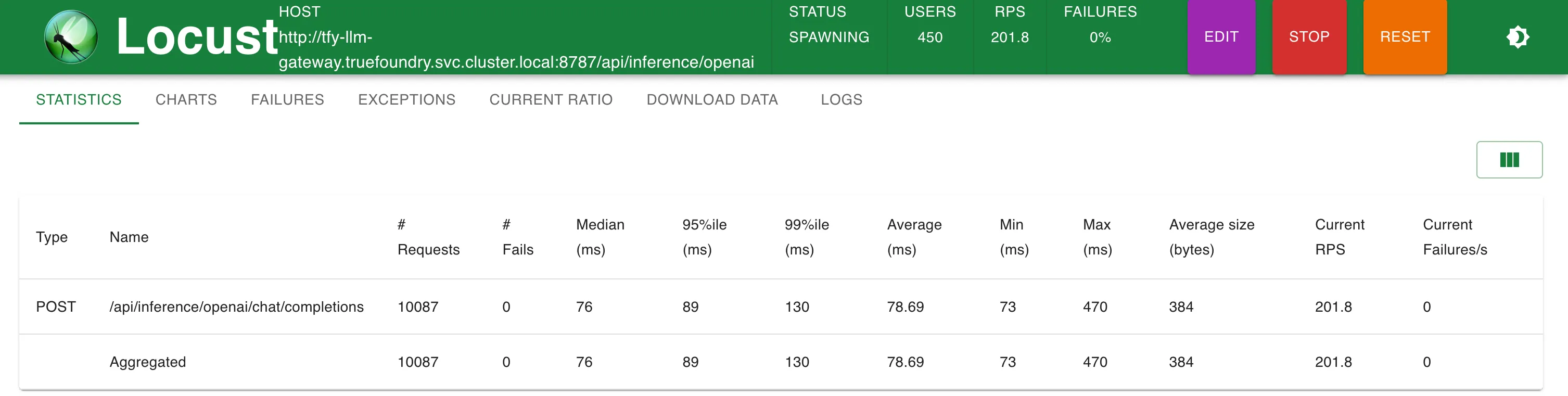
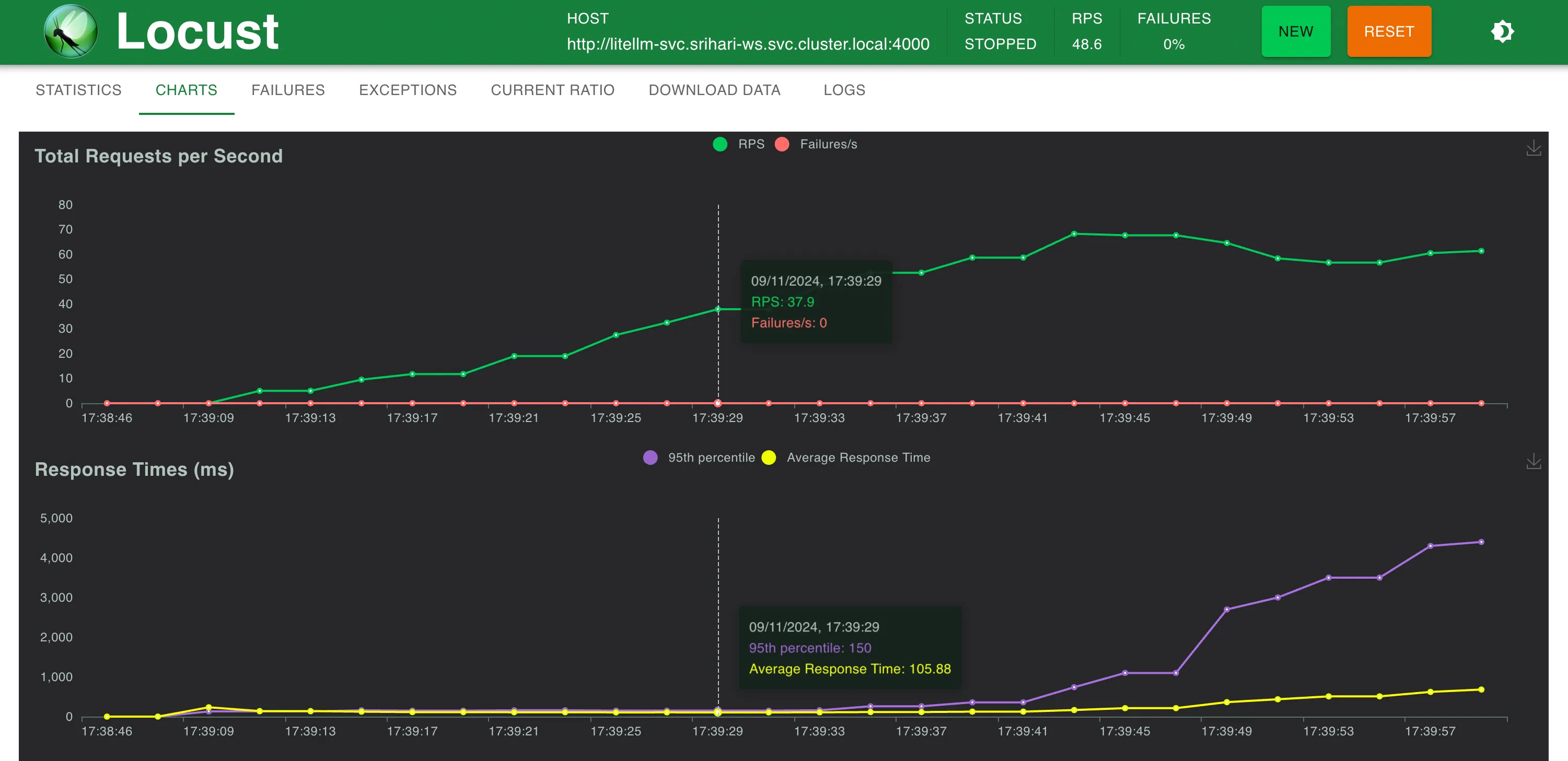
LitellM en la misma máquina no pudo escalar más allá de 40 a 50 RPS antes de alcanzar el límite de CPU
Más métricas
Configuración 1: Llamada directa a terminales de OpenAI
Estadísticas a 200 RPS
Estadísticas a 300 RPS
Tiempo de respuesta frente a RPS
Configuración 2: Puerta de enlace LLM de TrueFoundry
Estadísticas a 200 RPS
Estadísticas a 300 RPS
Tiempo de respuesta frente a RPS
Configuración 3: LitellM
Estadísticas a ~ 58 RPS
Tiempos de respuesta frente a RPS
Características de velocidad de LLM Gateway
Gastos generales casi nulos: Solo de 3 a 5 ms de latencia añadida
Backend optimizado: Construido con el marco Node.js de alto rendimiento
Almacenamiento en caché de configuración: La configuración se almacena en la memoria para una búsqueda rápida
Enrutamiento inteligente: Mínima sobrecarga de procesamiento
Listo para Edge: Implemente cerca de sus aplicaciones
Alta capacidad: UN t2.2 x grande La máquina de instancias de AWS (43$ al mes in situ) puede escalar hasta aproximadamente 3000 RPS sin problemas.
Implementación perimetral de TrueFoundry LLM Gateway
Proveedores compatibles
A continuación se muestra una lista completa de los proveedores de LLM populares compatibles con TrueFoundry LLM Gateway:
Provider
Streaming Supported
GCP
✅
AWS
✅
Azure OpenAI
✅
Self Hosted Models on TrueFoundry
✅
OpenAI
✅
Cohere
✅
AI21
✅
Anthropic
✅
Anyscale
✅
Together AI
✅
DeepInfra
✅
Ollama
✅
Palm
✅
Perplexity AI
✅
Mistral AI
✅
Groq
✅
Nomic
✅
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga




































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


