

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 18, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La administración de la configuración es un aspecto importante de la ingeniería de software. Este artículo destacará el por qué y el qué del problema y el motivo de las diferentes soluciones que existen.

El enfoque para administrar la configuración cambia a medida que la aplicación se amplía, tanto en términos de tráfico como de tamaño del equipo de desarrolladores. Para ilustrar el recorrido, empecemos con una aplicación sencilla.
Esta es una aplicación de servidor simple que se conecta a MongoDB y devuelve la lista de usuarios. El código es solo un pseudocódigo y no está destinado a adherirse a ningún idioma.

Configuración de código duro en la aplicación: ¡un GRAN NO!

Al codificar la URI de MongoDB en la aplicación, será muy difícil ejecutar la aplicación en cualquier otro entorno, como las computadoras portátiles de otros compañeros de equipo o en producción. Deberíamos seguir las Metodología de aplicación de 12 factores aquí para separar la configuración del código.
«CONFIGURACIÓN SEPARADA DEL CÓDIGO»
Ahora la pregunta es qué comprende la configuración de una aplicación? Citando a https://12factor.net/config
De una aplicación configuración es todo lo que es probable que varíe entre despliega (puesta en escena, producción, entornos de desarrollo, etc.). Esto incluye:
1. Identificadores de recursos para la base de datos, Memcached y otros servicios de respaldo
2. Credenciales para servicios externos como Amazon S3 o Twitter
3. Valores por implementación, como el nombre de host canónico de la implementación
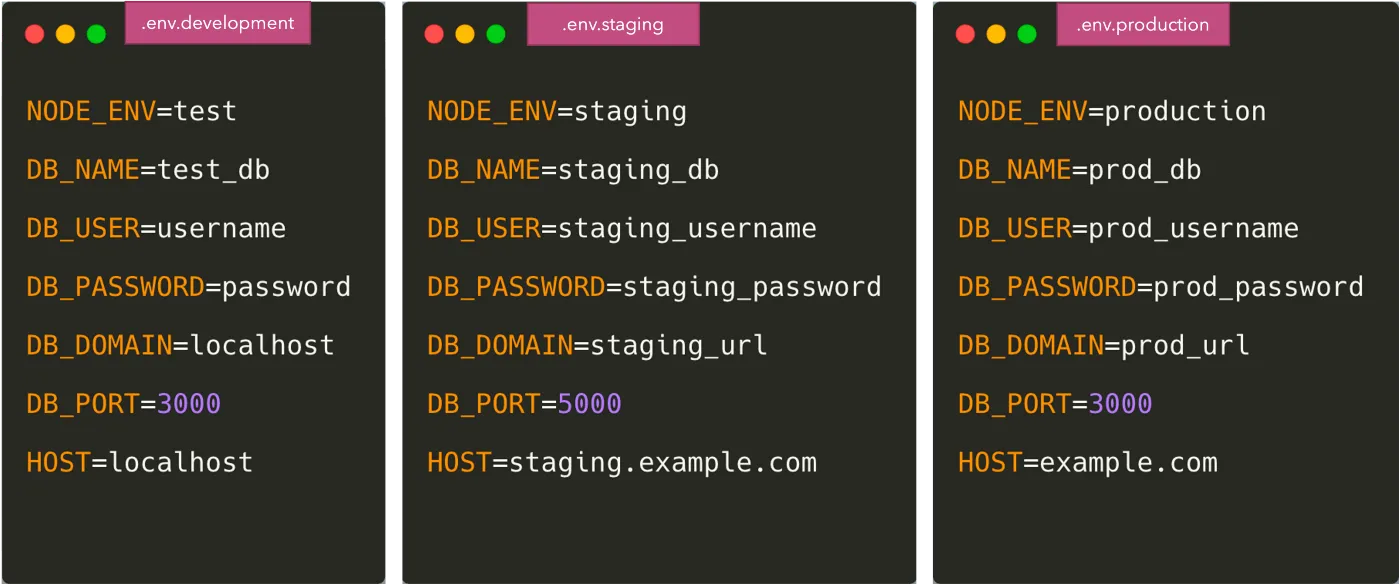
La forma más fácil y común de separar la configuración del código es colocar las variables en un archivo.env.
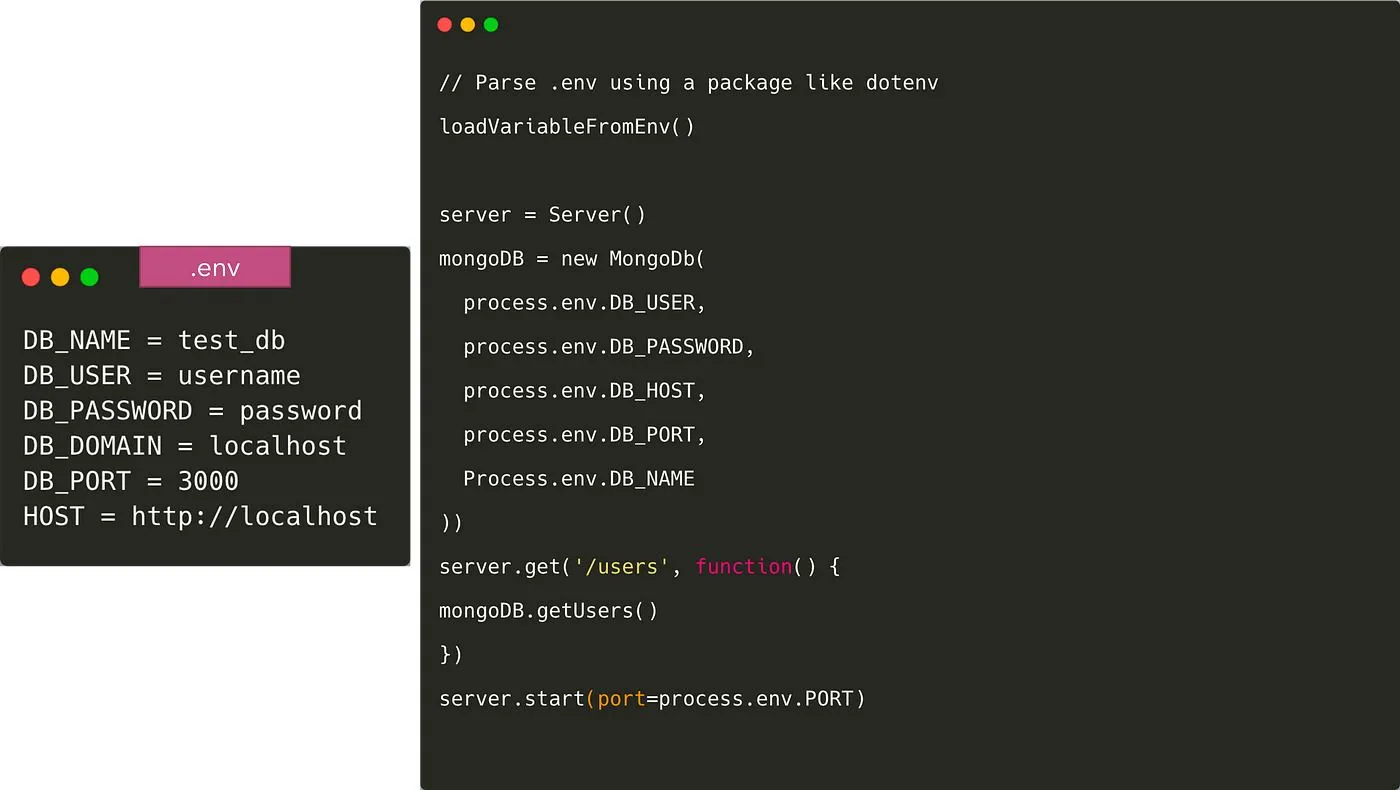
Una vez hecho esto, necesitamos cargar las variables en código desde el archivo.env. Hay varios paquetes que puedes hacer como doten v y dotenv-expand. El archivo.env no se envía a Git en este caso y cada desarrollador sobrescribe la variable según su propio entorno. Para que todos los desarrolladores tengan una idea de qué variables de entorno deben añadirse, solemos guardar un archivo como Ejemplo de.env. a Git.

También tendremos que proporcionar valores de estas variables en los entornos de puesta en escena y producción. Casi todos los sistemas de implementación proporcionan una forma de almacenar y proporcionar variables de entorno, como ConfigMap y Secrets en Kubernetes, o S3 para Elastic Container Service.
Tendremos que copiar estas variables a esos entornos y mantenerlas sincronizadas cada vez que los desarrolladores agreguen o eliminen variables de entorno. Un posible enfoque es tener un archivo.env independiente para los entornos de ensayo, producción, etc.

Se puede sugerir almacenar estos archivos en Git, pero hay un gran problema de seguridad en ese caso, especialmente para algunas de las credenciales confidenciales de los archivos env.
En este caso, las personas utilizan diferentes enfoques; sin embargo, algunos de los métodos más conocidos son:

Al usar cualquiera de estos sistemas externos, ahora hemos dividido la configuración entre los archivos.env y los secretmanagers. Algunos de los parámetros no confidenciales provendrán de los archivos.env y otros provendrán del almacenamiento remoto de credenciales. Podemos argumentar que podemos almacenar todos los parámetros en el almacenamiento remoto, pero a veces puede resultar exagerado. Así que ahora terminamos con lo siguiente:
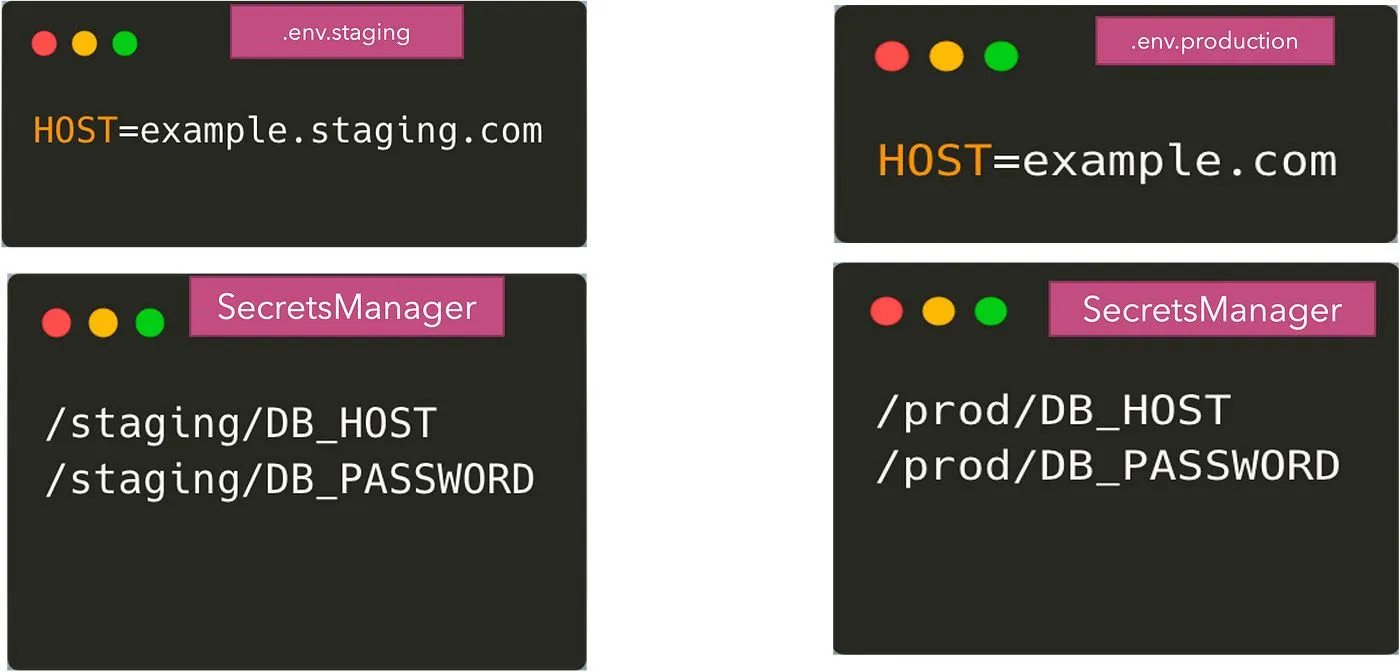
Nuestra aplicación ahora necesita tener código para leer de estas dos fuentes de configuración. La lectura de los archivos.env se puede hacer usando el paquete dotenv; sin embargo, obtener las variables de entorno de los secretmanagers requiere que usemos sus API correspondientes para obtener los valores.

Esto resuelve el problema de mantener nuestra configuración segura y también de seguir la metodología de 12 factores.
Sin embargo, escribir código de aplicación para obtener secretos termina siendo una práctica repetitiva en la que cada aplicación ahora necesita agregar código específico de secretmanager para obtener los valores de la API. Esto también significa que si alguna vez cambiamos nuestro proveedor de secretsmanager, el código de todas las aplicaciones debe cambiar. Para resolver este problema, puede haber varios enfoques:
La administración de la configuración es compleja y debe realizarse correctamente desde el principio para garantizar que la velocidad de los desarrolladores siga siendo alta sin sacrificar los aspectos de seguridad. Kubernetes, que es el más utilizado hoy en día para implementar aplicaciones, viene con su propia configuración y administración de secretos, que analizaré en otro artículo. Además, si utilizas alguna otra forma de gestión de la configuración, menciónala en los comentarios. ¡Me encantaría saber más y aprender de ti!
True Foundry es una puerta de enlace de inteligencia artificial de nivel empresarial que abarca pasarelas de LLM, MCP y agentes, lo que permite a las empresas conectarse, observar y controlar de forma segura el acceso a modelos, herramientas, barreras de protección y agentes desde un único plano de control. La puerta de enlace de IA permite cargas de trabajo agenciales que son:
a) Segura — resolver problemas de administración, autenticación y autorización de claves
b) Eficiente — optimizar el costo, la latencia y las conmutaciones por error multirregionales
c) Seguro para el futuro — permite conexiones unificadas y componibles entre LLM, MCP y barandas de cualquier proveedor
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


