

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 27, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Elástico es una solución innovadora de código abierto diseñada para optimizar el uso de los recursos de Kubernetes al permitir que los servicios se reduzcan a cero durante los períodos de inactividad y se amplíen según demanda. Diseñada con una arquitectura de dos componentes (un controlador de Kubernetes y un solucionador de solicitudes), ELASTI administra sin problemas la disponibilidad de los servicios y minimiza los costos. El objetivo de esta publicación es ofrecer un recorrido técnico sobre su arquitectura, instalación y flujos operativos, para garantizar que pueda integrar y ampliar Elasti de forma eficaz en sus entornos de Kubernetes.
💡 Esta función está incluida en la suite de escalado automático de Truefoundry. Para obtener más información, consulta la documentación.
Si bien Kubernetes ofrece sólidas capacidades de escalado a través de HPA y soluciones como KEDA, escalar a cero réplicas sigue siendo un desafío. Los enfoques existentes suelen clasificarse en dos categorías:
Elati se creó para abordar estas limitaciones con tres objetivos de diseño clave:
Elati se compone de dos componentes principales que funcionan en conjunto para gestionar la escalabilidad de los servicios:
Controlador (operador):
Resolvedor:
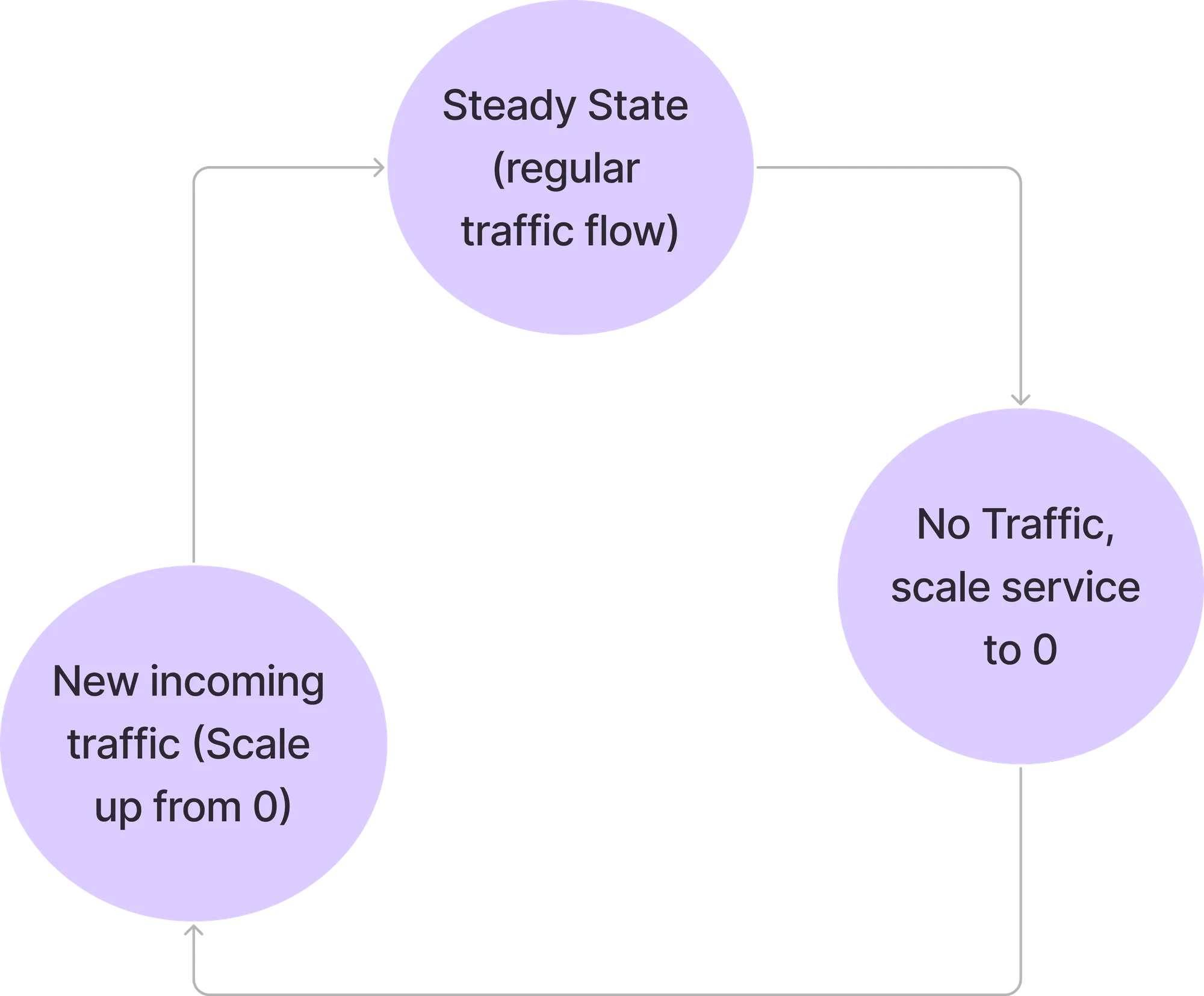
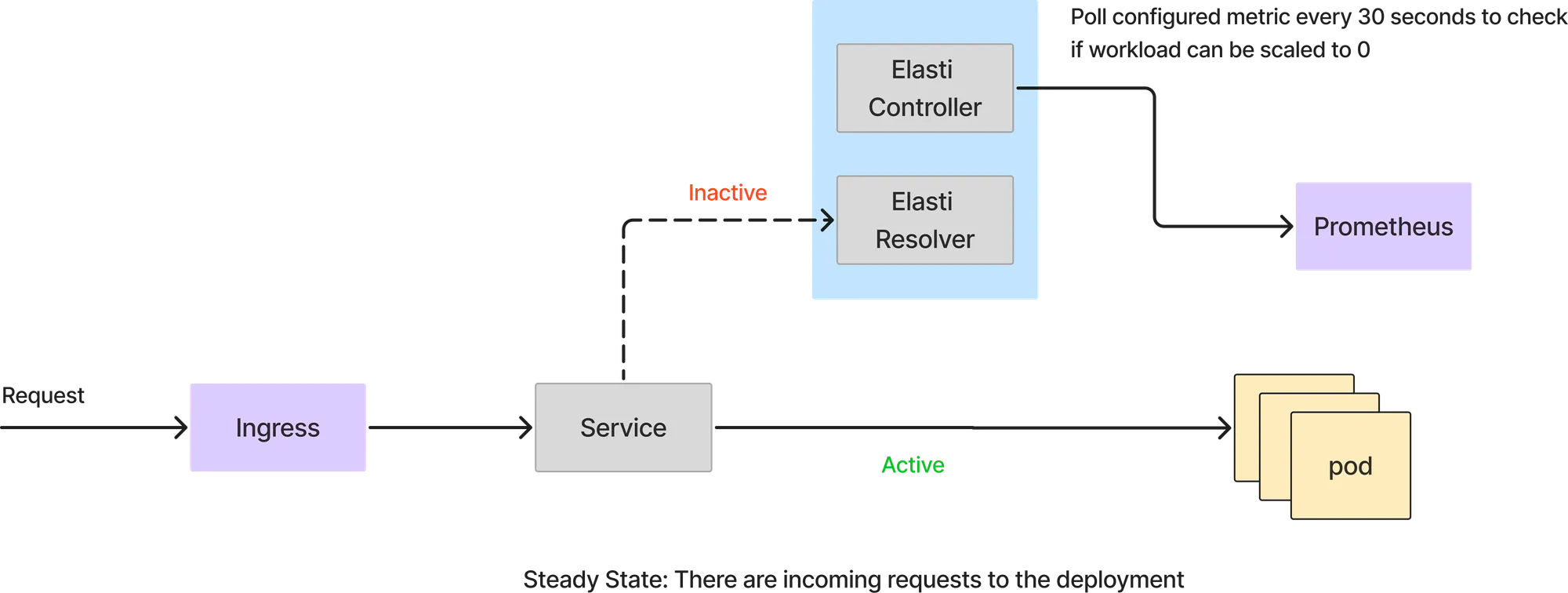
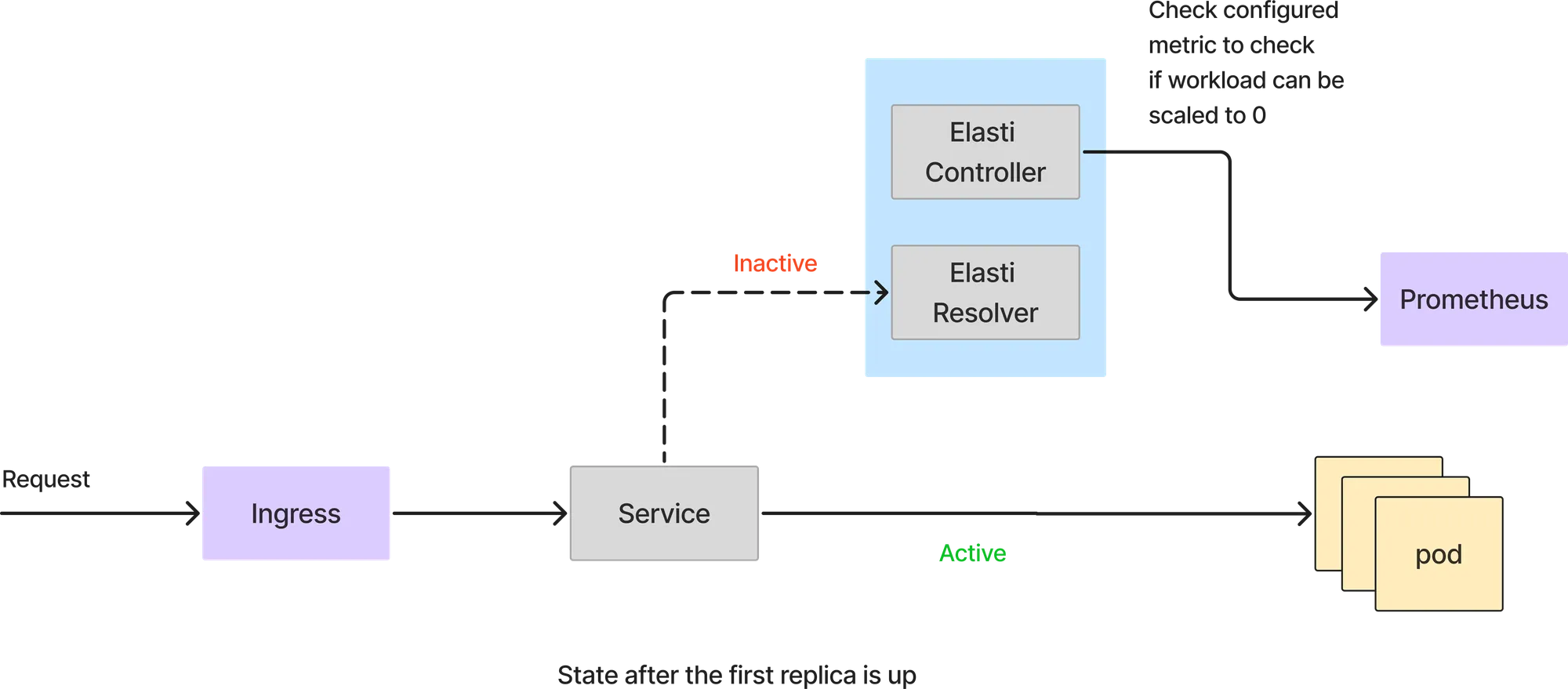
En este modo, todas las solicitudes las gestionan directamente los service pods. El solucionador de Elatti no entra en la ruta de la solicitud. El controlador Elasis sigue sondeando a Prometheus con la consulta configurada y comprueba el resultado con un valor umbral para ver si el servicio se puede reducir.
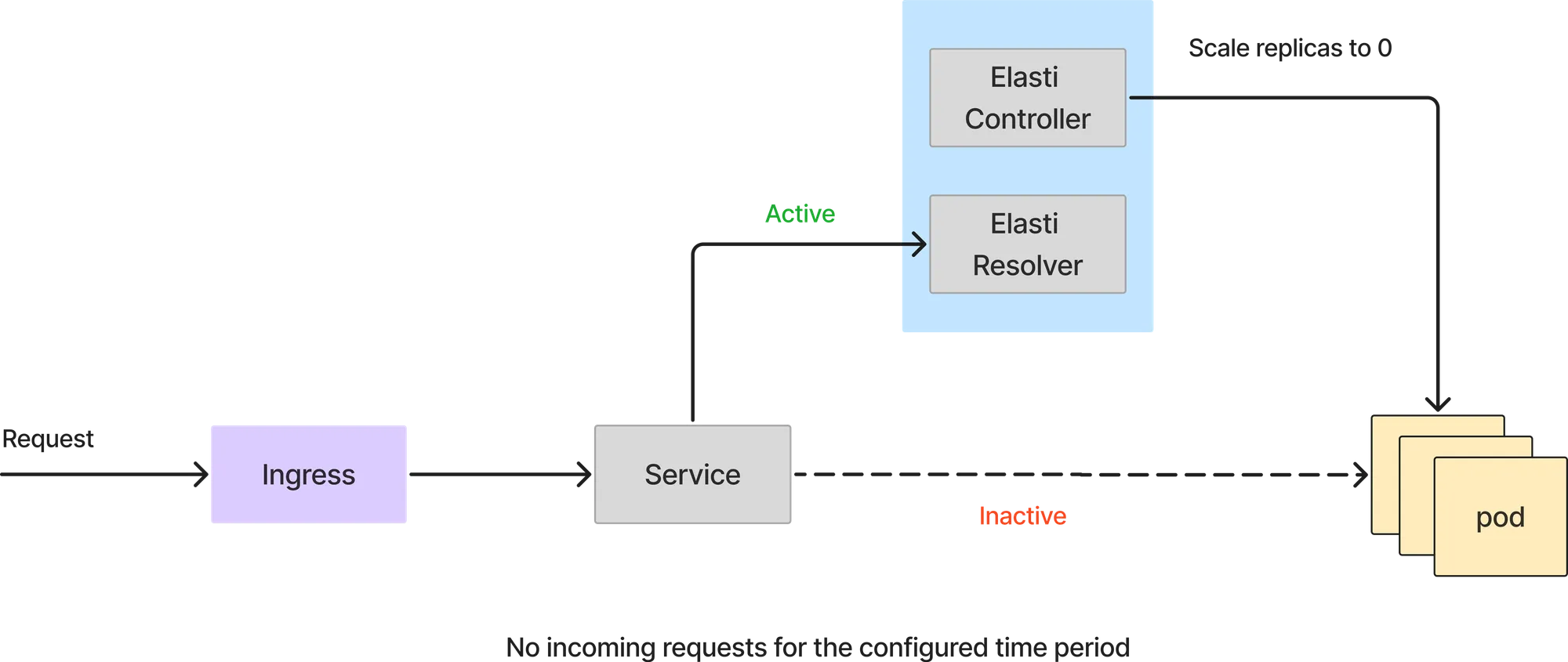
Si la consulta de prometheus devuelve un valor inferior al umbral, Elatis reducirá el servicio a 0. Antes de escalar a 0, redirige las solicitudes para que se reenvíen al solucionador de Elatis y, a continuación, modifica el despliegue o la implementación para tener 0 réplicas. A continuación, también detiene Keda (si se está utilizando Keda) para impedir que amplíe el servicio, ya que Keda está configurado con minReplicas como 1.
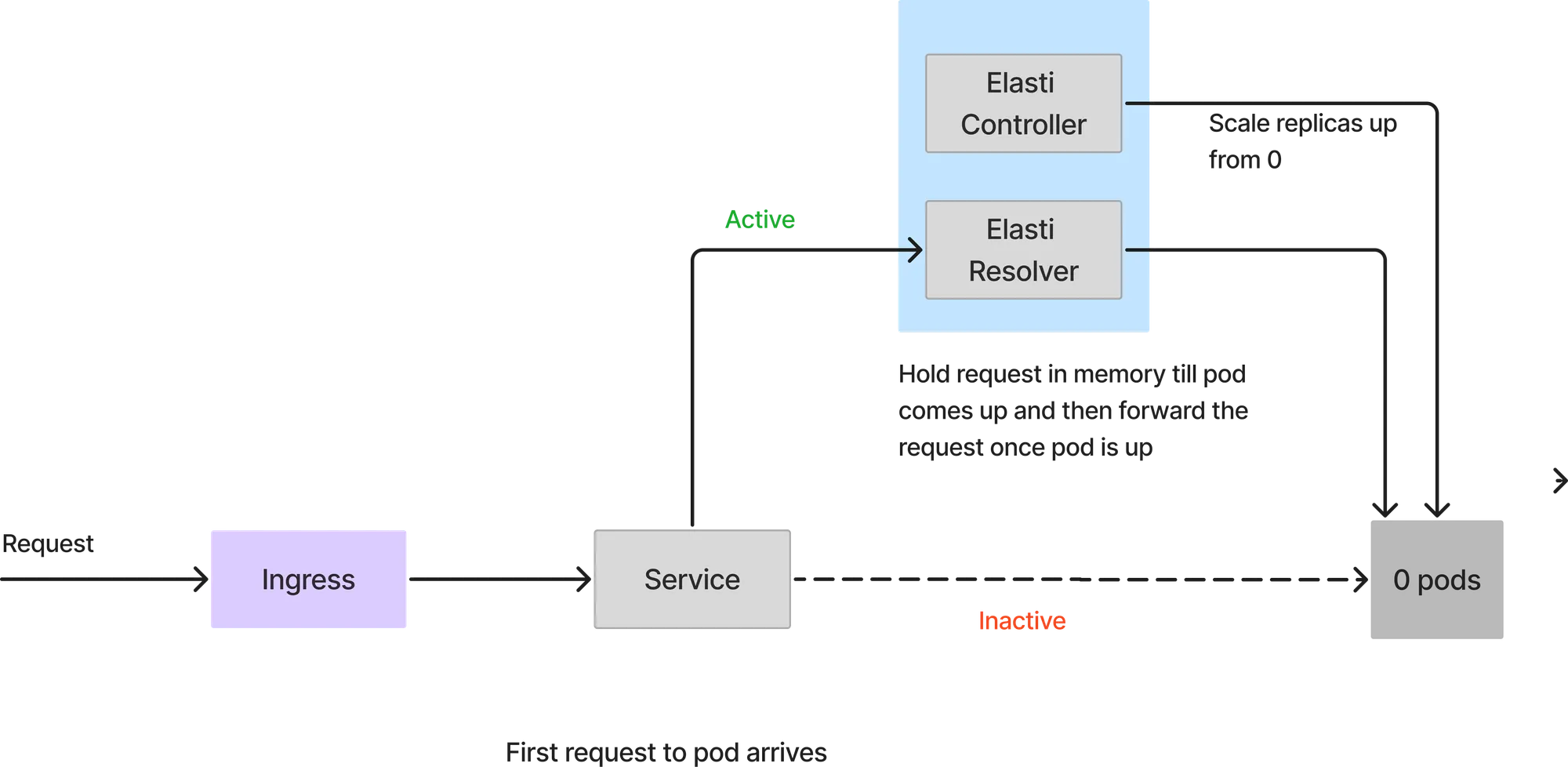
Como el servicio se reduce a 0, todas las solicitudes llegarán al solucionador de Elatti. Cuando llegue la primera solicitud, Elatti ampliará el servicio hasta las minTargetReplicas configuradas. A continuación, reanuda Keda para continuar con el escalado automático en caso de que se produzca una ráfaga repentina de solicitudes. También cambia el servicio para que apunte a los módulos de servicio reales una vez que el módulo está activo. Las solicitudes que llegan a ElastiResolver se vuelven a intentar hasta 6 minutos y la respuesta se devuelve al cliente. Si el pod tarda más de 6 minutos en aparecer, la solicitud se descarta.
inicio de minikube
o
tipo create cluster --name elasti-demo
o
Crea un clúster local con Docker Desktop
helm repo agrega prometheus-community https://prometheus-community.github.io/helm-charts
actualización del repositorio de helm
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack\
--supervisión del espacio de nombres\
--crear-espacio de nombres\
--set alertmanager.enabled=false\
--set grafana.enabled=false\
--set Prometheus.PrometheusSpec.ServiceMonitorSelectorSelectorNiLuseShelmValues=false
Instala y configura prometheus en control espacio de nombres
Prometheus se utilizará para leer las métricas de nginx ingress, que luego serán utilizadas por elasti para consultar las métricas en función de las cuales decidirá cuándo escalar un servicio desde y hacia cero.
helm repo agregar ingress-nginx https://kubernetes.github.io/ingress-nginx
actualización del repositorio de helm
helm install ingress-nginx ingress-nginx/ingress-nginx\
--espacio de nombres ingress-nginx\
--set controller.metrics.enabled=true\
--set controller.metrics.ServiceMonitor.enabled=true\
--create-namespace
Implementa un controlador nginx en el ingress-nginx espacio de nombres
El controlador se utilizará para dirigir el tráfico a nuestro servicio httpbin de demostración.
4. Configuración de Elati:
helm repo agrega elasti https://charts.truefoundry.com/elasti
actualización del repositorio de helm
helm install elasti oci: //tfy.jfrog.io/tfy-helm/elasti\
--namespace elasti --create-namespace
Instalación de Elasis con helm en el espacio de nombres elasti
Una vez instalado Elati, verás que sus dos componentes clave se están ejecutando:
Para configuraciones más avanzadas, consulta valores.yaml para ver todas las opciones de configuración en el archivo de valores del timón.
kubectl crea un espacio de nombres elastici-demo
kubectl apply -n elasti-demo -f\
https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-application.yaml
Implementación de un servicio httpbin en demo elástica espacio de nombres
Este servicio httpbin se utilizará para demostrar cómo configurar un servicio para gestionar el tráfico a través de elasti.
Crea un archivo yaml con la siguiente configuración para un ElastiService.
Versión de API: elasti.truefoundry.com/v1alpha1
tipo: ElastiService
metadatos:
nombre: httpbin-elasti
espacio de nombres: elasti-demo
especificación:
Número mínimo de réplicas de Target: 1
servicio: httpbin
Período de enfriamiento: 5
Referencia de objetivo de escala:
Versión de API: aplicaciones/v1
tipo: despliegues
nombre: httpbin
desencadenantes:
- tipo: prometheus
metadatos:
consulta: sum (rate (nginx_ingress_controller_nginx_process_requests_total [1m])) o vector (0)
Dirección del servidor: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
umbral: «0.5"
demo-elasti-service.yaml
Una vez creado el archivo, aplique el ElastiService
kubectl apply -f https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-elastiService.yaml
Algunos campos clave de la especificación CRD son:
Réplicas minTarget: Número mínimo de réplicas que se deben mostrar cuando llegue la primera solicitud.Período de enfriamiento: Tiempo mínimo (en segundos) de espera después de la ampliación antes de considerar la reduccióndisparadores: Lista de condiciones que determinan cuándo reducir la escala (actualmente solo admite las métricas de Prometheus)Scale TargetRef: Referencia al objetivo de escala similar al utilizado en HorizontalPodAutoScaler.Para obtener más información y configurar un ElastiService para su caso de uso, consulte este documento.
Con estos pasos, ahora tiene:
Esta configuración le ayuda a probar escenarios de enrutamiento reales y a supervisar el rendimiento y las métricas del tráfico de entrada.
Para probar esta configuración, puedes enviar solicitudes al balanceador de cargas de nginx y monitorear los pods de nuestro servicio de demostración.
kubectl svc/nginx-ingress-nginx-controller\
-n ingress-nginx 80:80:80
Reenvío de puertos al controlador nginx
kubectl obtiene pods -n elasti-demo -w
Inicie un reloj en el servicio httpbin
Ahora puedes enviar una solicitud a http://localhost:8080/httpbin y puede ver cómo elasti escala el servicio a 1 réplica.
curl -v http://localhost:8080/httpbin
Enviar una solicitud al servicio httpbin
Luego, el servicio se reducirá nuevamente después de que no haya actividad durante Período de enfriamiento segundos especificados en ElastiService (5 segundos en este caso).
Para desinstalar Elastos, primero tendrá que eliminar todos los ElastiServices instalados. A continuación, simplemente borre el archivo de instalación.
kubectl elimina elastiservices --todos
helm uninstall elasti -n elasti
kubectl elimina el espacio de nombres elasti
Elati es la mejor opción cuando:
Elasti se desarrolló a partir de la necesidad de abordar un desafío específico de Kubernetes: implementar una verdadera escala a cero sin sacrificar la integridad de las solicitudes ni imponer una sobrecarga excesiva. Esta solución admite el escalado automático nativo con HPA y KEDA, lo que garantiza que las configuraciones de servicio existentes permanezcan inalteradas y, al mismo tiempo, se logre una utilización eficiente de los recursos.
Con el código abierto de esta herramienta, nuestro objetivo es proporcionar una solución sólida para los entornos que requieren una verdadera escalabilidad a cero, cero pérdidas de solicitudes y un espacio operativo mínimo.
Agradecemos las contribuciones y los comentarios de la comunidad. Explore el documento de desarrollo para obtener más información.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


