

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 12, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los modelos lingüísticos grandes (LLM) ofrecen capacidades poderosas, pero también presentan altos costos de infraestructura, patrones de uso impredecibles y la posibilidad de un uso indebido. A medida que las empresas integran los LLM en las herramientas orientadas al cliente, los copilotos internos y las plataformas de API, la necesidad de un acceso controlado y confiable se vuelve crítica. Aquí es donde la limitación de tarifas desempeña un papel clave.
En el contexto de la inferencia de LLM, el límite tradicional de velocidad de solicitudes por segundo (RPS) no es suficiente. Los LLM consumen muchos recursos, se basan en tokens y su carga computacional es muy variable. Una sola solicitud para un modelo de 70 000 millones de parámetros puede consumir miles de tokens y afectar significativamente a la latencia de la GPU. Sin los controles adecuados, la infraestructura compartida puede volverse inestable rápidamente o tener un costo prohibitivo.
Este artículo explica cómo funciona la limitación de velocidad en un Puerta de enlace de IA, por qué es esencial para una infraestructura de IA escalable y cómo TrueFoundry la habilita de forma predeterminada para garantizar un uso justo, la rentabilidad y un rendimiento de nivel de producción en las implementaciones de varios inquilinos.
La limitación de velocidad es un mecanismo que se utiliza para controlar el número de solicitudes que un cliente puede enviar a un sistema dentro de un período de tiempo específico y es una capacidad fundamental de la tecnología moderna. Puertas de enlace de IA administrar el tráfico de LLM. Garantiza la equidad, evita la sobrecarga y mantiene la disponibilidad, especialmente en entornos multiusuario. Las API tradicionales suelen aplicar límites simples, como 100 solicitudes por minuto por usuario, lo que funciona bien para los servicios REST estándar.
Sin embargo, los LLM funcionan de manera muy diferente. Cada solicitud puede suponer una carga radicalmente diferente para la infraestructura en función del tamaño de la entrada, el tipo de modelo y la salida esperada. Por ejemplo, una solicitud de 20 fichas a un modelo de 7 000 millones puede completarse rápidamente, mientras que una solicitud de 2000 fichas a un modelo de 65 000 millones puede bloquear las GPU durante varios segundos. Incluso dos solicitudes idénticas a modelos diferentes pueden variar 5 veces o más en cuanto al costo de procesamiento.
Esto hace que los límites basados en solicitudes sean insuficientes. Las pasarelas de LLM modernas deben adoptar una limitación de velocidad basada en los tokens, que tenga en cuenta la cantidad real de tokens procesados y la carga informática por llamada.
Los factores clave que se tienen en cuenta para limitar las tasas teniendo en cuenta los siguientes:
En comparación con los límites de solicitudes fijos, los límites de reconocimiento de tokens:
En los flujos de trabajo de IA generativa, la limitación de la velocidad se vuelve aún más crítica. Un solo usuario puede activar el procesamiento de backend a gran escala mediante solicitudes extensas, la ingestión de documentos o agentes de varios pasos. Sin controles, esto puede provocar una congestión de la GPU, una alta latencia o costes inesperados.
El uso en el mundo real suele ser impredecible y está impulsado por aplicaciones frontales, bucles de prueba o automatización. La limitación de velocidad garantiza que estas interacciones se mantengan estables y eficientes, incluso cuando la infraestructura se comparte entre usuarios o inquilinos.
Para cualquier implementación de LLM de nivel de producción, la limitación inteligente de velocidad no es una función opcional, sino un requisito fundamental para la escalabilidad, la confiabilidad y el control de costos.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

La limitación de velocidad es más que una salvaguarda de fondo. Para las plataformas que prestan servicios a las LLM, especialmente aquellas que ofrecen API públicas o multiusuario, actúa como una capa estratégica para la estabilidad, la gobernanza y la alineación empresarial. Ya se trate de OpenAI, Anthropic o de plataformas creadas con TrueFoundry, los límites de tarifas cumplen varios propósitos fundamentales.
Proteja la infraestructura contra el abuso
La inferencia generativa de IA consume muchos recursos. Una ráfaga repentina de solicitudes largas o solicitudes simultáneas puede sobrecargar las colas de GPU, aumentar la latencia o incluso interrumpir los servicios. Los límites de velocidad garantizan que el tráfico se procese de forma controlada y priorizada, lo que evita el agotamiento de los recursos.
Haga cumplir la equidad entre los usuarios o inquilinos
En los sistemas multiusuario, el uso de un cliente no debe degradar el rendimiento de los demás. Los límites de velocidad ayudan a reforzar el aislamiento entre los usuarios, los equipos o las claves de API. Esto garantiza niveles de servicio consistentes independientemente del número de usuarios activos a la vez.
Alinee el uso con los planes de precios
Muchas plataformas de la generación de IA monetizan en función de los tokens o los niveles de uso. Los límites de tarifas ayudan a hacer cumplir esos límites. Por ejemplo:
Evite sorpresas y sobrecostos
El uso del LLM puede ampliarse de forma rápida y silenciosa. Sin los límites adecuados, el consumo de fichas y la utilización de la GPU pueden aumentar. La limitación de velocidad ayuda a las plataformas a evitar costos de infraestructura inesperados y a mantener el control presupuestario.
Mejore la confiabilidad y la experiencia del usuario
Cuando se controla el uso, las colas del sistema permanecen estables. Esto se traduce en una latencia más baja, tasas de éxito más altas y una experiencia de usuario más uniforme, algo que es especialmente importante en los entornos de producción con acuerdos de nivel de servicio.
En los sistemas basados en LLM, no todas las solicitudes tienen el mismo impacto. Una solicitud breve dirigida a un modelo pequeño puede consumir recursos mínimos, mientras que una consulta larga a un modelo grande puede consumir una cantidad considerable de tiempo de GPU. Debido a esta variabilidad, las plataformas modernas aplican límites de velocidad en múltiples dimensiones en lugar de basarse únicamente en el recuento de solicitudes.
Estas son las dimensiones más comunes que se utilizan para la limitación de velocidad efectiva:
El uso de estas dimensiones brinda a los equipos de plataforma la flexibilidad necesaria para alinear el uso de los recursos con las restricciones de infraestructura, las necesidades de los usuarios y las expectativas de nivel de servicio.
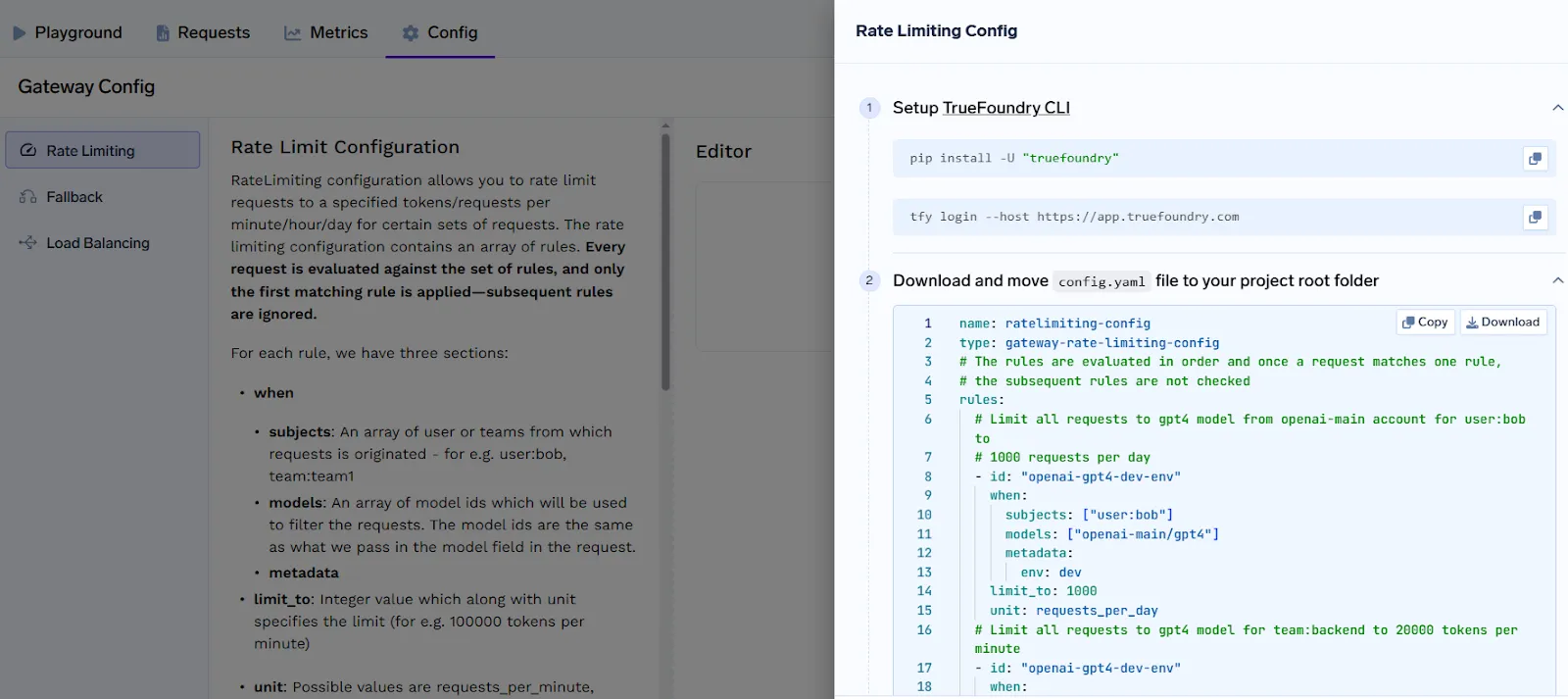
TrueFoundry proporciona un sistema de limitación de velocidad robusto y flexible que permite a los equipos de la plataforma controlar el acceso a los puntos finales de LLM en función de las solicitudes o el uso de tokens. Esto garantiza una asignación justa de la computación, evita el abuso y alinea el uso con las políticas de la organización o los planes de facturación.
La base del mecanismo de limitación de velocidad de TrueFoundry es un sistema de configuración basado en reglas que permite a los equipos definir políticas precisas para todos los usuarios, equipos, cuentas virtuales, modelos y solicitudes de metadatos.
Configuración basada en reglas
La limitación de velocidad en TrueFoundry se define mediante una lista de reglas, cada una de las cuales especifica:
Las reglas se evalúan en orden, por lo que las reglas más específicas deben colocarse por encima de las más amplias para garantizar una coincidencia correcta.
Tipos de límites admitidos
TrueFoundry admite límites basados en solicitudes y en tokens en varios intervalos de tiempo:
Esto permite la aplicación de políticas que reflejen el uso real de la computación, lo que es especialmente importante cuando se presentan solicitudes de longitud variable a modelos de diferentes tamaños.
Casos de uso comunes
La flexibilidad del sistema de configuración admite una amplia gama de casos de uso:
Ejemplo de configuración
nombre: ratelimiting-config
tipo: gateway-rate-limiting-config
reglas:
- id: «regla específica»
cuando:
temas: ["usuario: bob@email.com «]
modelos: ["openai-main/gpt4"]
límite_a: 1000
unidad: requests_per_day
Este ejemplo limita el uso del GPT-4 de un usuario específico a 1000 solicitudes por día. El sistema de limitación de velocidad de TrueFoundry está diseñado para ser potente y fácil de administrar. Gracias a los controles basados en los tokens, la segmentación granular y las políticas claras basadas en YAML, los equipos pueden ampliar el uso de la LLM con confianza y, al mismo tiempo, mantener el control sobre la infraestructura y los costos.
Cómo aplicar la configuración
1. Instale la CLI de TrueFoundry:
pip install -U «truefoundry»
prueba iniciar sesión --host https://app.truefoundry.com
2. Coloca tu config.yaml en el directorio de tu proyecto.
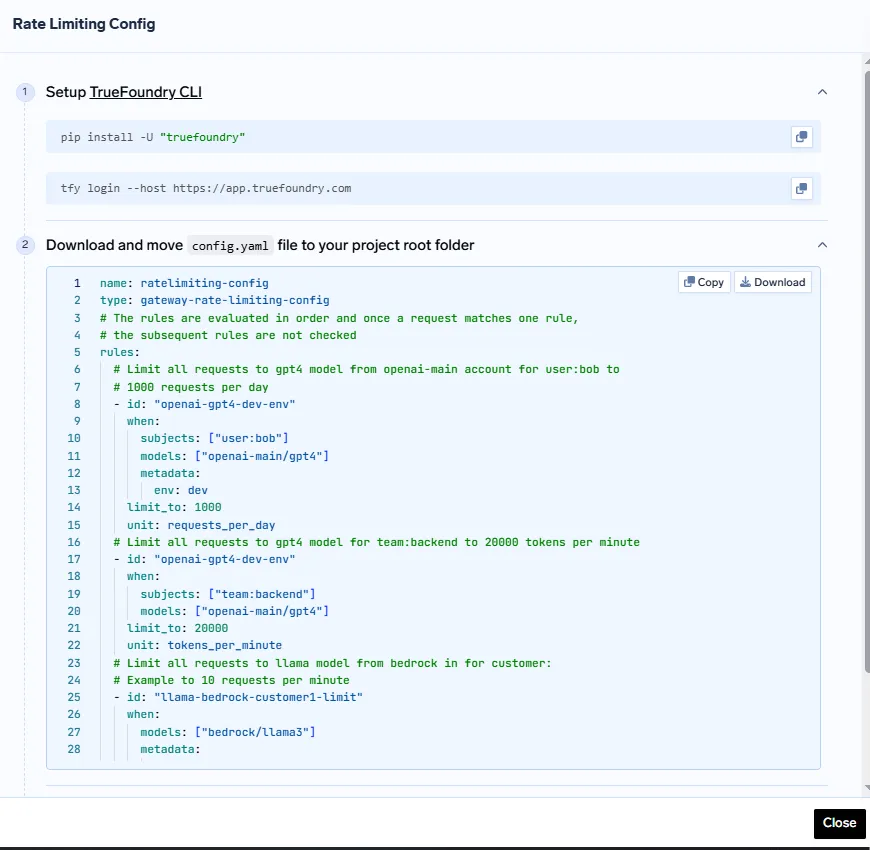
3. Aplique la configuración mediante:
intenta aplicar -f config.yaml
Este enfoque declarativo garantiza que los límites de velocidad estén controlados por versiones, sean reproducibles y estén alineados con las mejores prácticas de GitOps.
Comentarios en tiempo real sobre los límites de tarifas
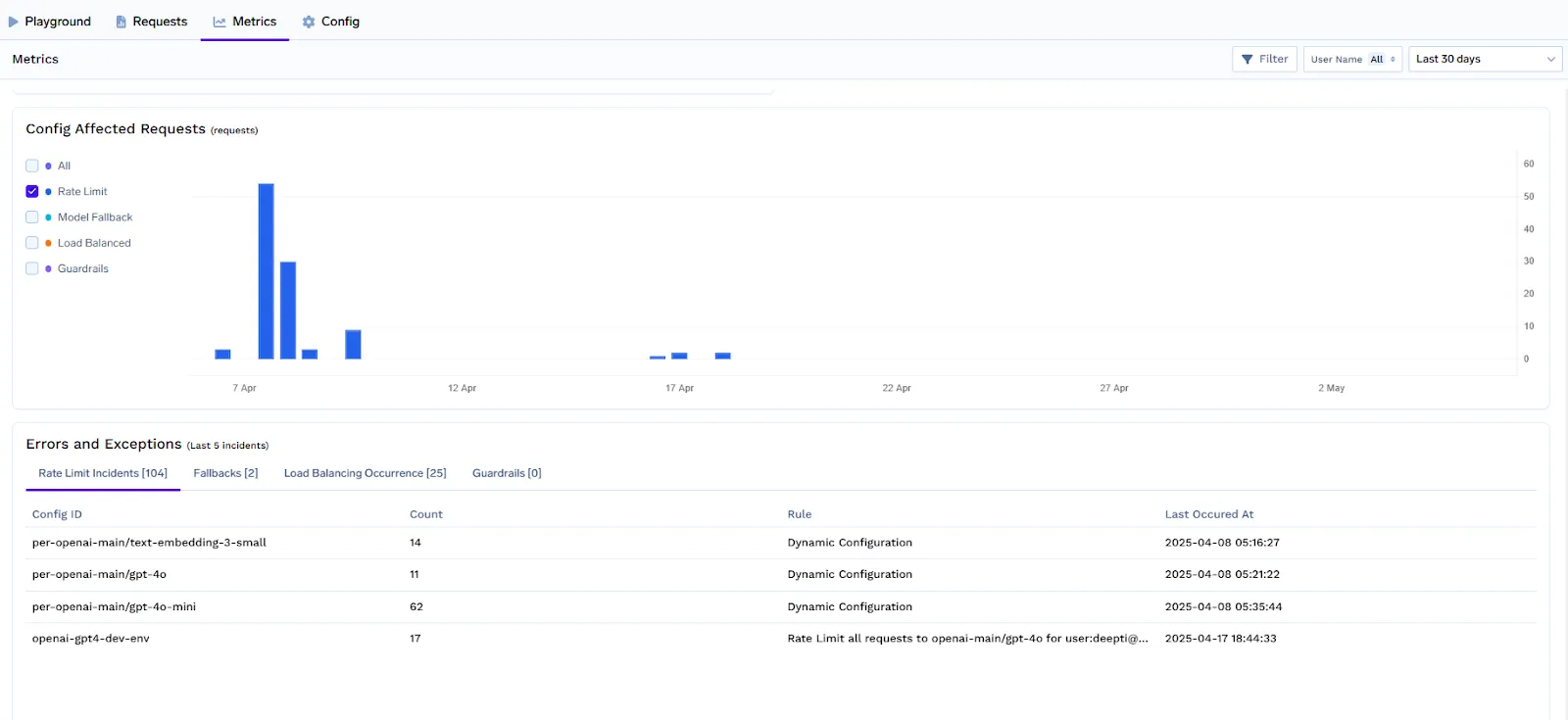
El sistema de limitación de tarifas de TrueFoundry está diseñado para proporcionar comentarios inmediatos y transparentes a los clientes cuando se infringen los límites o están a punto de agotarse. Esto ayuda a los desarrolladores a comprender los límites de uso y a gestionar correctamente las limitaciones en sus aplicaciones.
Cuando una solicitud supera el límite de velocidad definido:
Este mecanismo de comentarios favorece un mejor comportamiento de los clientes, habilita la lógica de reintento automatizado y garantiza que el uso se mantenga dentro de los límites de la cuota sin conjeturas.
Paneles y alertas
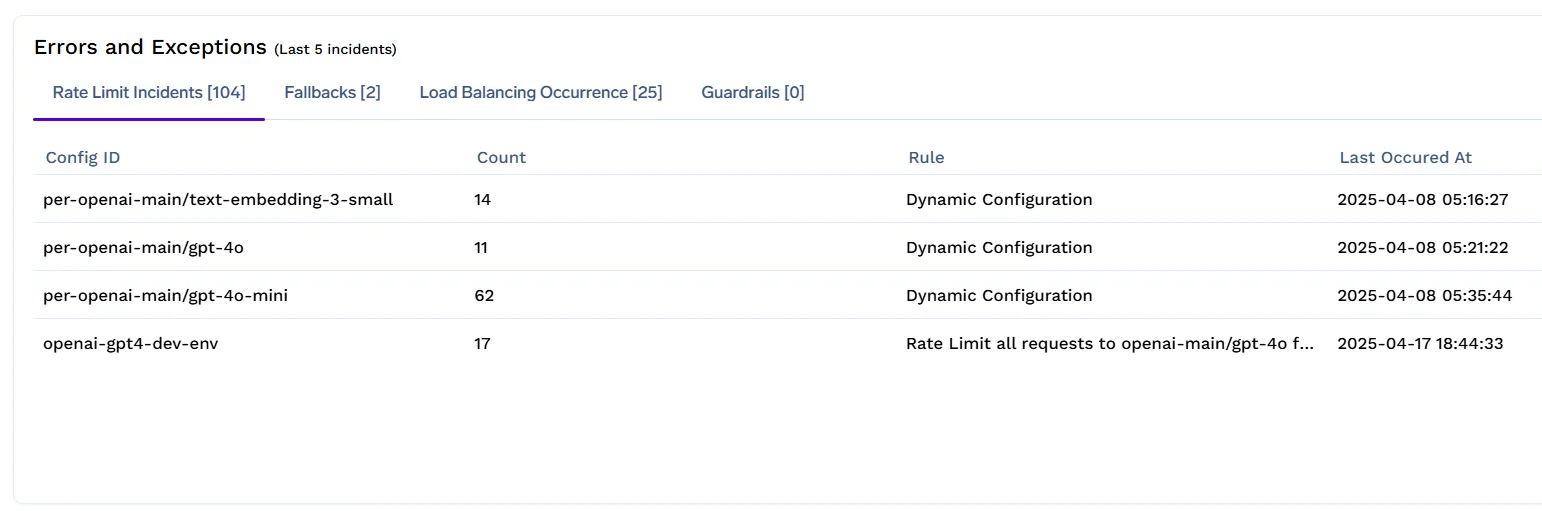
TrueFoundry proporciona una capacidad de observación integrada para ayudar a los equipos de la plataforma a supervisar y optimizar las políticas de límites de velocidad en tiempo real.
Con el panel de control de LLM Gateway, puede realizar un seguimiento de:
Esta información ayuda a detectar el abuso, ajustar los límites de forma proactiva y garantizar que los usuarios de alto valor reciban un servicio uniforme.
Cuando las API de LLM fallan, ya sea debido a límites de velocidad, errores internos o interrupciones temporales, los mecanismos de respaldo mantienen sus aplicaciones funcionando sin problemas. En lugar de devolver los errores al usuario final, TrueFoundry puede dirigir automáticamente la solicitud a un modelo o proveedor de respaldo, manteniendo la disponibilidad con una interrupción mínima.
Las reglas de respaldo se activan en función de condiciones específicas, como el ID del modelo, el usuario o el equipo solicitante y los códigos de respuesta, como 429 o 500. Cuando una solicitud cumple estas condiciones, se dirige a uno o más modelos alternativos especificados en la configuración alternativa. Estos objetivos alternativos pueden incluir, de forma opcional, la anulación de parámetros como la temperatura o los valores máximos, lo que permite ajustar el comportamiento según el proveedor del modelo. Durante la evaluación, solo se aplica la primera regla de coincidencia, lo que garantiza una gestión predecible y determinista de las fallas.
Una regla alternativa típica de TrueFoundry incluye los siguientes componentes:
Ejemplo de configuración de respaldo:
nombre: model-fallback-config
tipo: gateway-fallback-config
# Las reglas se evalúan en orden. Una vez que una solicitud coincide con una regla, las reglas siguientes no se comprueban.
reglas:
# Vuelva a gpt-4 en Azure o AWS si openai-main/gpt-4 falla con 500 o 503.
# El objetivo openai-main también anula algunos parámetros de solicitud como temperature y max_tokens.
- identificador: «openai-gpt4-fallback»
cuando:
modelos: ["openai-main/gpt4"]
códigos de estado de respuesta: [500, 503]
modelos_alternativos:
- objetivo: openai-main/gpt-4
override_params:
temperatura: 0.9
número máximo de tokens: 800
# Vuelva a LLama3 en Azure o AWS si bedrock/llama3 falla con 500 o 429 para el cliente1.
- identificador: «llama-bedrock-customer1-fallback»
cuando:
modelos: ["bedrock/llama 3"]
metadatos:
identificador de cliente: cliente1
códigos de estado de respuesta: [500, 429]
modelos_alternativos:
- objetivo: aws/llama3
- objetivo: azure/llama3
LLM Gateway de TrueFoundry admite de forma nativa la configuración de respaldo declarativo como parte de su sistema de configuración. Esto permite a los equipos definir políticas de enrutamiento tolerantes a errores y preservar el tiempo de actividad sin intervención manual, especialmente cuando trabajan con varios proveedores. En conjunto, la limitación inteligente de la velocidad y el respaldo automatizado crean la base para los servicios de la generación de inteligencia artificial de alta disponibilidad.
En cualquier plataforma de IA multiusuario, la limitación de tarifas es crucial para garantizar la estabilidad, la equidad y la gobernanza de los costos. Permite a los equipos definir los límites de acceso no solo para los usuarios individuales, sino también entre equipos, cuentas virtuales y modelos específicos sin necesidad de una lógica personalizada.
El Gateway de TrueFoundry admite la limitación de velocidad declarativa mediante la configuración de YAML, donde las reglas se evalúan en orden. Se aplica la primera regla de coincidencia, lo que significa que las reglas más específicas deben colocarse en la parte superior, mientras que las reglas más genéricas deben colocarse en la parte inferior de la configuración. Esta estructura garantiza el control por capas y, al mismo tiempo, mantiene configuraciones limpias y legibles.
Cada regla puede incluir los siguientes componentes:
Ejemplos de límites de tarifas para múltiples inquilinos
Limitar la solicitud de usuario específica: Supongamos que desea limitar todas las solicitudes al modelo gpt4 desde la cuenta openai-main para los usuarios bob@email.com y jack@email.com a 1000 solicitudes por día:
- identificador: «user-gpt4-limit»
cuando:
temas: ["usuario: bob@email.com «, «usuario: jack@email.com «]
modelos: ["openai-main/gpt4"]
límite_a: 1000
unidad: requests_per_day
Aplica límites a todo el equipo: Si quieres restringir el número total de solicitudes para el equipo de «frontend» a 5000 por día
- id: «límite de interfaz de equipo»
cuando:
temas: ["equipo:interfaz"]
límite_a: 5000
unidad: requests_per_day
Restrinja las cuentas virtuales: Si quieres limitar el número de solicitudes de la cuenta virtual 'va-james' a 1500 por día
- id: «va-james-limit»
cuando:
temas: ["cuenta virtual: va-james"]
límite_a: 1500
unidad: requests_per_day
Establezca límites globales para todos los usuarios y modelos:
- id: «{usuario} - {modelo} -límite diario»
cuando: {}
límite_a: 1000000
unidad: tokens_per_day
Esta configuración permite a los equipos de la plataforma segmentar el uso entre las unidades de negocio, aplicar cuotas por entorno y proteger los costosos puntos finales de los modelos, al tiempo que admiten cargas de trabajo de IA escalables y confiables.
La limitación de velocidad es más que un control de backend. Es un factor fundamental para un uso confiable, rentable y justo de la infraestructura de LLM a escala. Ya sea que opere una plataforma multiusuario, ofrezca acceso por niveles a los clientes o ejecute cargas de trabajo internas de inteligencia artificial en todos los equipos, la implementación de límites de tarifas inteligentes y que tengan en cuenta los tokens garantiza que su sistema siga siendo predecible en situaciones de presión.
Además de la limitación de velocidad, funciones como el enrutamiento alternativo, la retroalimentación en tiempo real y la configuración granular brindan a los equipos de ingeniería las herramientas necesarias para equilibrar el rendimiento con el control. El LLM Gateway de TrueFoundry combina estas capacidades con una interfaz declarativa, que permite a los equipos de la plataforma definir políticas transparentes, auditables y alineadas con los objetivos de la organización.
A medida que se acelera la adopción de la IA generativa, los sistemas que aplican el control de acceso inteligente sin sacrificar la experiencia del usuario ni el tiempo de actividad definirán la próxima generación de resiliencia de la infraestructura. Si está creando o ampliando una puerta de enlace de inteligencia artificial, la limitación de velocidad no es solo algo a tener en cuenta. Es algo que hay que hacer bien desde el primer día.
La limitación de velocidad en la pasarela LLM se refiere al mecanismo utilizado para controlar la frecuencia de las solicitudes entrantes o el volumen de tokens que un usuario, equipo o aplicación puede procesar dentro de un período de tiempo específico. A diferencia de la limitación tradicional de las API, se basa en los tokens y tiene en cuenta la carga informática real de las diferentes arquitecturas de modelos, lo que garantiza que las consultas que consumen muchos recursos no bloqueen el sistema.
La implementación de la limitación de velocidad en los entornos de puertas de enlace de LLM ayuda a controlar los costos al evitar picos inesperados de consumo de tokens y scripts fuera de control. Al establecer cuotas pormenorizadas por día o por hora, las organizaciones pueden limitar el gasto destinado a usuarios o entornos no productivos específicos, lo que garantiza que los experimentos de IA se mantengan dentro de un presupuesto predecible y, al mismo tiempo, se protegen de las costosas sorpresas en la facturación.
La limitación de velocidad en las configuraciones de pasarelas de LLM es esencial para proteger la infraestructura del abuso y garantizar una alta disponibilidad para todos los usuarios. Impide que un solo «vecino ruidoso» agote las cuotas de los proveedores o la capacidad de la GPU, lo que, de lo contrario, provocaría un aumento de la latencia y generaría errores frecuentes de 429 «solicitudes excesivas». Esta capa de administración es fundamental para mantener los SLA estables en la producción.
Las estrategias comunes para limitar la velocidad en LLM Gateway incluyen los límites de solicitud por minuto (RPM) y token por minuto (TPM), que proporcionan una medida precisa del uso de los recursos. Las pasarelas avanzadas también admiten límites escalonados en función de las funciones de los usuarios o los tipos de modelo, lo que permite que las tareas de misión crítica reciban una mayor prioridad, mientras que las cargas de trabajo de desarrollo de menor prioridad se reducen durante los períodos de congestión.
Si bien añade un pequeño paso de procesamiento, la limitación de velocidad en LLM Gateway generalmente introduce menos de 4 milisegundos de sobrecarga, lo que es insignificante en comparación con los segundos necesarios para la generación del modelo. De hecho, a menudo mejora la latencia percibida al evitar que las colas del backend se saturen, lo que garantiza que las solicitudes se procesen sin problemas sin provocar tiempos de espera ni fallos en el servicio.
Sí, TrueFoundry proporciona una implementación de nivel de producción de la limitación de velocidad en LLM Gateway mediante una configuración declarativa basada en reglas. Permite a los equipos imponer límites basados en los tokens a varios proveedores de modelos y arrendatarios mediante archivos YAML sencillos. Este sistema proporciona comentarios en tiempo real y paneles detallados, lo que permite a los equipos de la plataforma escalar las cargas de trabajo de IA y, al mismo tiempo, mantener una estricta gobernanza de los costos y los recursos.
La limitación de velocidad de IA funciona mediante el seguimiento de la frecuencia con la que un usuario envía solicitudes a una API de IA. El sistema cuenta las solicitudes o los tokens dentro de un período de tiempo. Si el usuario supera el límite permitido, la API bloquea temporalmente las nuevas solicitudes o devuelve un error hasta que se restablezca el límite. Esto protege a los servidores de la sobrecarga.
Absolutamente. Al limitar el uso de los tokens y las tasas de solicitud, las pasarelas evitan el uso excesivo inesperado de la GPU o el gasto en la nube. Las organizaciones pueden alinear el uso con los presupuestos, planificar el acceso por niveles y reducir el costoso sobreaprovisionamiento, a la vez que mantienen un servicio uniforme para las cargas de trabajo críticas.
Sí. Las pasarelas de IA modernas, como TrueFoundry, permiten a los equipos actualizar las reglas de límite de velocidad en tiempo real o mediante scripts automatizados, lo que garantiza que la infraestructura pueda gestionar los aumentos inesperados sin tiempo de inactividad ni deterioro del rendimiento. Los ajustes dinámicos mantienen la capacidad de respuesta del servicio y, al mismo tiempo, mantienen un uso justo para todos los inquilinos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


