

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 20, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Las pasarelas se están convirtiendo en el plano de control operativo de los sistemas GenAI. Unifican el tráfico de las API de terceros (OpenAI, Anthropic, Mistral, Bedrock) y de los modelos autohospedados, aplican las políticas y exponen un único panel de control en lo que respecta a la latencia, los errores, el consumo de tokens y el gasto. Ese mismo punto de estrangulamiento es el lugar ideal para capturar los rastros, calcular los análisis a nivel de modelo y usuario y activar barreras y alertas, sin añadir latencia a la ruta de solicitud.
Las organizaciones reales han aprendido esto por las malas. Piense en un copiloto de soporte que atienda a miles de agentes. Una tarde, una actualización rápida e inocua aumenta la duración de la producción en aproximadamente un 40%. La satisfacción de los agentes disminuye a medida que se retrasan las respuestas; el departamento de finanzas paga la factura. Con la capacidad de observación de las pasarelas, observaría que la latencia p95 y los tokens de salida suben en la ruta afectada, lo correlacionaría con la versión de despliegue o rápida y revertiría hacia atrás (lo ideal sería establecer una alerta automática para detectarlo la próxima vez).
Esta publicación resume qué es una puerta de enlace de IA, por qué la observabilidad es fundamental y las métricas, paneles y flujos de trabajo concretos que los equipos deben implementar. También mostraremos cómo AI Gateway de TrueFoundry incluye la gama de observabilidad lista para usar: análisis unificados (latencia, TTFT/ITL, errores), seguimiento granular de los costos, desgloses a nivel de cliente/usuario, visibilidad de enrutamiento en buen estado o fallido y recopilación escalable y de bajos gastos generales integrada en la arquitectura.
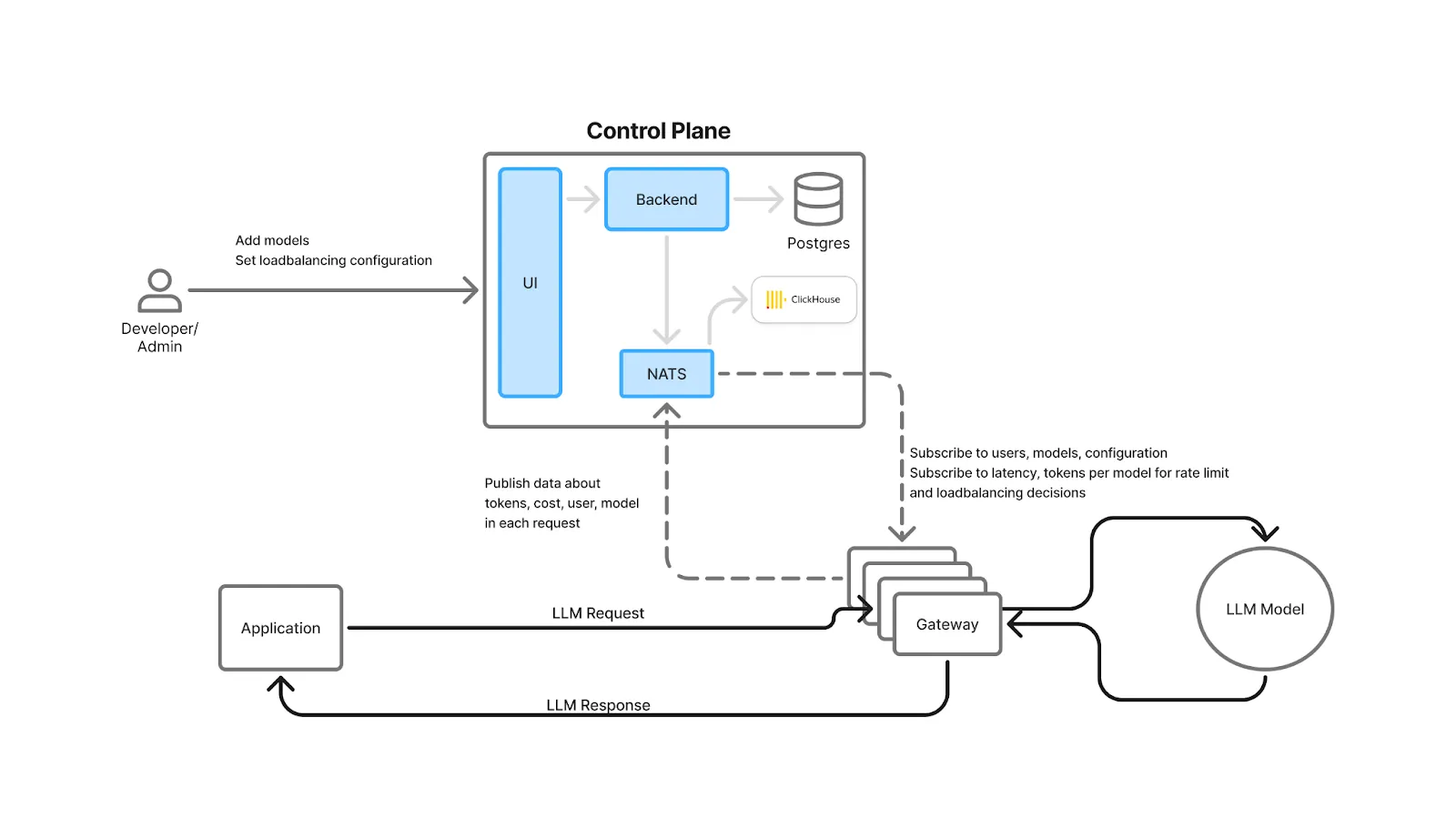
Un Puerta de enlace de IA es una capa delgada de alto rendimiento que envía por proxy las solicitudes de aplicaciones a uno o más proveedores de LLM o modelos autohospedados. Unifica las API, centraliza la autenticación y RBAC (control de acceso basado en roles) , aplica límites de tarifas y barandas, interpreta equilibrio de carga y conmutación por error, y captura datos de observabilidad y costos para cada solicitud. Piense en ello como la capa de «entrada, política y telemetría» para GenAI.
Desde el punto de vista operativo, las pasarelas modernas admiten el enrutamiento ponderado y basado en la latencia, las comprobaciones de estado y las alternativas automáticas cuando un modelo o una región no están en buen estado, por lo que las solicitudes continúan incluso si el proveedor tiene problemas. Como todas las solicitudes pasan por la puerta de enlace, los equipos pueden comparar a los proveedores por latencia y costo, lo que hace OpenRouter frente a puerta de enlace AI una evaluación práctica a la hora de decidir cómo gestionar el enrutamiento, la observabilidad y el control a escala.
True Foundry la arquitectura está diseñada para que estos controles y métricas añadan una sobrecarga mínima: comprueba la autenticación, límite de velocidad, y el equilibrio de carga se realiza en la memoria; los registros y las métricas se escriben de forma asincrónica en una cola; y la ruta de solicitud evita las llamadas externas (a menos que opte por el almacenamiento en caché). La puerta de enlace es escalable horizontalmente y está vinculada a la CPU, lo que reduce la latencia de extremo a extremo en milisegundos de un solo dígito.
La latencia de LLM es multimodal: hay tiempo hasta el primer token (TTFT), latencia entre tokens (ITL) para la transmisión y latencia total de solicitudes. Cada uno afecta de manera diferente a la experiencia de usuario percibida Las pasarelas que rastrean las tres opciones ayudan a diagnosticar si la ralentización se debe a las colas de los proveedores, a modelar el procesamiento, a la red o a la longitud de las solicitudes, y a elegir la mejor estrategia de enrutamiento.
Los tokens son los nuevos ciclos de la CPU. Un solo mensaje puede abarcar varias herramientas o pasos de recuperación, y los costos se acumulan entre los distintos proveedores. La observabilidad debe atribuir el gasto por modelo, proveedor, entorno, aplicación, inquilino y usuario, y mantenerse al día con los precios públicos de los proveedores para evitar las hojas de cálculo manuales.
Las aplicaciones de producción necesitan protegerse contra las interrupciones de los proveedores, las limitaciones y las regresiones de los modelos. La capacidad de observación, vinculada a las comprobaciones de estado, a los desgloses de código 4xx y 5xx, a las tasas de retroceso y retroceso y a la utilización de los límites de velocidad, permite hacer cumplir los SLO y realizar automáticamente la conmutación por error cuando el rendimiento se deteriora.
Las empresas necesitan registros completos de solicitud/respuesta con controles de acceso y políticas de moderación de contenido y PII. Una puerta de enlace centraliza esta aplicación y registro para que los equipos puedan demostrar quién llamó a qué modelo, con qué datos y qué arrojó, sin compartir ampliamente las claves de API de los proveedores.
La calidad, los precios y las cuotas de los modelos cambian con frecuencia. Las organizaciones que utilizan sistemas de pasarelas pueden comparar a los proveedores entre sí y cambiar el tráfico basándose en datos recientes sobre latencia, costes y errores, manteniendo el rendimiento y los márgenes a medida que el mercado evoluciona.
La orientación externa se hace eco de estas necesidades: los líderes del sector hacen hincapié en la capacidad de observación de la IA para responder rápidamente a las desviaciones, las interrupciones y los picos de costos; OpenAI y Azure recomiendan el registro estructurado y la reducción exponencial de los límites de velocidad, que una puerta de enlace puede estandarizar en todas las aplicaciones.
A continuación se muestran las capacidades que cabe esperar de una pasarela de IA de producción, y que TrueFoundry ofrece de forma nativa.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Así es como TrueFoundry incorpora la observabilidad en la ruta de solicitud principal y envía una pila de análisis completa lista para usar, sin ralentizar el tráfico de producción.
.webp)
El panel de análisis muestra: la latencia de las solicitudes (p50/p95/p99), el tiempo hasta el primer token (TTFT/TTFS), la latencia entre tokens (ITL), el coste por modelo/proveedor, los tokens de entrada/salida, los códigos de error y la actividad política (límite de velocidad, equilibrio de carga, alternativas, barreras, presupuestos). Las vistas se dividen por modelo, usuario, equipo, ID de regla y metadatos personalizados; también puedes descargar CSV sin procesar.
Permita que Public Cost complete automáticamente los precios por token a partir de las tarifas publicadas por los proveedores (OpenAI, Anthropic, Bedrock, etc.). En el caso de modelos negociados o ajustados con precisión, defina el coste privado con precios de los tokens de entrada/salida personalizados. Ambos desembocan en análisis de costes agregados y por solicitud.
Incluya el contexto empresarial (cliente, función, entorno) y desglose los tokens, la latencia y el gasto según cualquier dimensión, lo que resulta ideal para las devoluciones de cargos, la detección de vecinos ruidosos y la priorización de las optimizaciones.
.webp)
Defina las cuotas por token o solicitudes por minuto, hora o día, con un alcance para los usuarios, modelos o segmentos identificados mediante metadatos. Los paneles muestran el uso y los límites para que pueda ajustar el tamaño correcto de los límites y proteger la capacidad compartida.
Usa divisiones basadas en el peso para los experimentos o enrutamiento basado en la latencia para el estado estacionario. Las comprobaciones de estado marcan los backends en mal estado según los umbrales de error o latencia y los excluyen automáticamente. Las cadenas de respaldo vuelven a intentarlo en caso de error, con intervalos y métricas que muestran qué camino se tomó y su impacto en la latencia y los costos.
Centralice las claves de los proveedores, emita tokens de acceso por ámbito, aplique el RBAC y conserve registros de solicitud/respuesta inmutables para garantizar el cumplimiento, en todos los servidores LLM y MCP
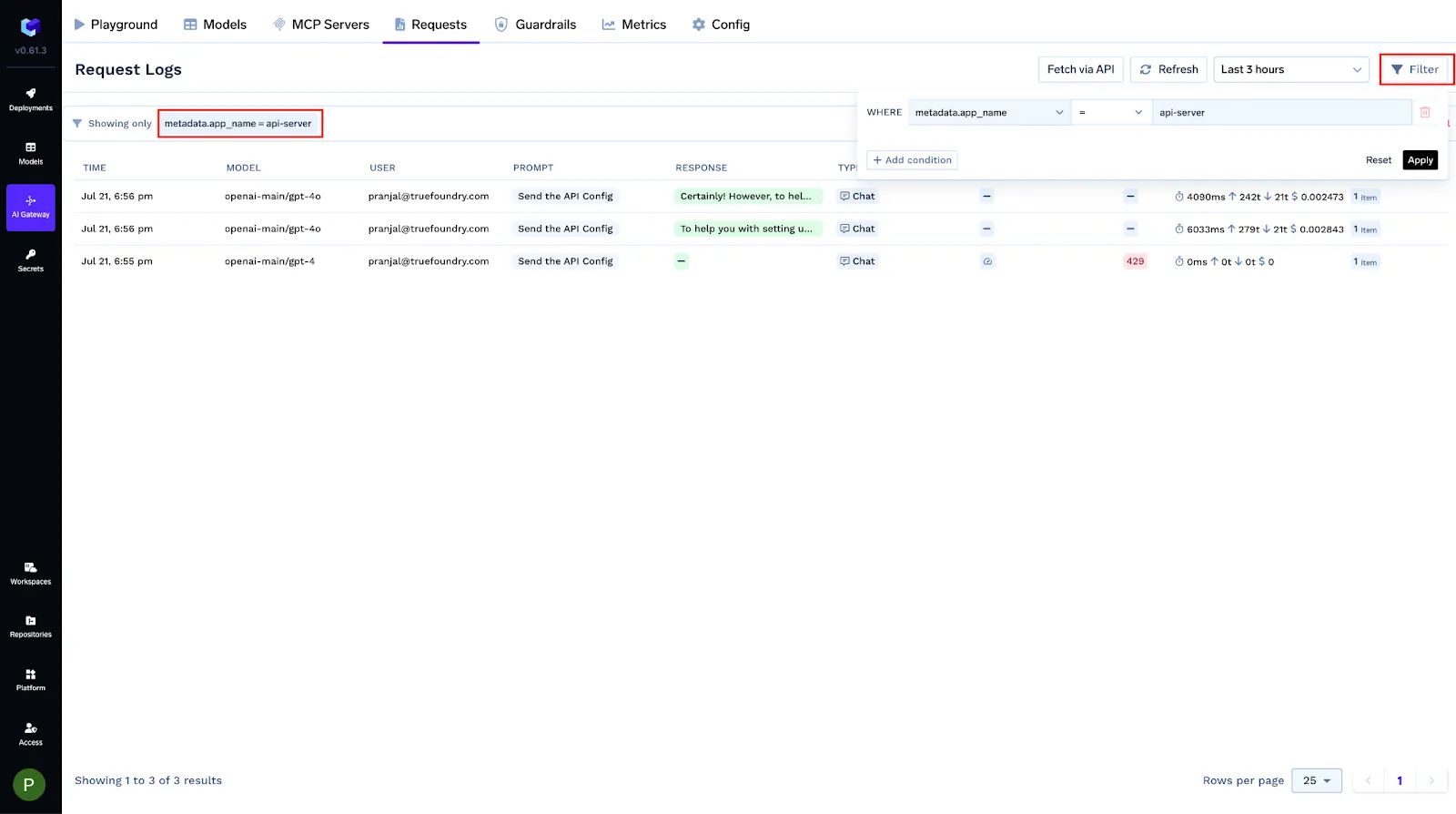
Puedes etiquetar cada solicitud con metadatos estructurados a través de METADATOS X-TFY- cabecera. Las claves registradas se convierten en filtros consultables, etiquetas de Grafana y condiciones en las configuraciones de las pasarelas (límites de velocidad, equilibrio de carga, alternativas, barreras). Los valores son cadenas (≤128 caracteres).
X-TFY-METADATA: {"tfy_log_request":"true","environment":"staging","feature":"countdown-bot","customer_id":"acme-42"}
Use this to isolate logs, group cost/latency by tenant or feature, and roll out policy changes safely to a subset of traffic.
Example — rate‑limit by metadata
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
- id: openai-gpt4-dev-env
when:
models: ["openai-main/gpt4"]
metadata:
env: dev
limit_to: 1000
unit: requests_per_day
Lo mismo ocurre cuando el patrón de metadatos se aplica a las reglas de equilibrio de carga y respaldo
La puerta de enlace es compatible con OpenTelemetry. Activa la exportación mediante OTLP y envía las trazas a cualquier servidor (Tempo, Jaeger, Datadog/New Relic a través de Collector, TrueFoundry Tracing). Los intervalos incluyen atributos genéricos (modelo, tokens, TTFT, ITL, parámetros, llamadas a herramientas, errores) y tramos detallados para la limitación de la velocidad, el equilibrio de carga, las alternativas y las llamadas a servidores o herramientas de MCP, lo que permite correlacionar el comportamiento de los proveedores con los intervalos a nivel de aplicación.
Habilitar el rastreo
ENABLE_OTEL_TRACING="true"
OTEL_SERVICE_NAME=<your_service>
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT="https://<otel-collector>/v1/traces"
OTEL_EXPORTER_OTLP_TRACES_HEADERS="Authorization=Bearer <token>"Espacios representativos
.webp)
Expose /metrics for Prometheus or push OTEL metrics by setting:
ENABLE_OTEL_METRICS="true"
OTEL_EXPORTER_OTLP_METRICS_ENDPOINT="https://<otlp-endpoint>/v1/metrics"
OTEL_EXPORTER_OTLP_METRICS_HEADERS="Authorization=Bearer <token>"
LLM_GATEWAY_METADATA_LOGGING_KEYS='["customer_id","request_type"]'
Metadata keys listed in LLM_GATEWAY_METADATA_LOGGING_KEYS become Prometheus labels llm_gateway_metadata_<key>, enabling per‑customer/per‑feature cost and latency charts. (Truefoundry Docs)<key>Las claves de metadatos que aparecen en LLM_GATEWAY_METADATA_LOGGING_KEYS se convierten en las etiquetas llm_gateway_metadata_ de Prometheus, que permiten gráficos de costes y latencia por cliente y función. (Documentos de Truefoundry)
Familias métricas clave (subconjunto)
Tokens & cost: llm_gateway_input_tokens, llm_gateway_output_tokens, llm_gateway_request_cost.
Latency: llm_gateway_request_processing_ms, llm_gateway_first_token_latency_ms, llm_gateway_inter_token_latency_ms.
Errors: llm_gateway_request_model_inference_failure, llm_gateway_config_parsing_failures.
Policy activity: llm_gateway_rate_limit_requests_total, llm_gateway_load_balanced_requests_total, llm_gateway_fallback_requests_total, llm_gateway_budget_requests_total, llm_gateway_guardrails_requests_total.
Agent/MCP: llm_gateway_agent_request_duration_ms, llm_gateway_agent_llm_latency_ms, llm_gateway_agent_tool_latency_ms, llm_gateway_agent_tool_calls_total, llm_gateway_agent_mcp_connect_latency_ms, llm_gateway_agent_request_iteration_limit_reached_total. UN panel de control Grafana JSON prediseñado es publicado por TrueFoundry, organizado en modelo, Usuario, Config, y Invocación MCP puntos de vista. Añada variables para sus metadatos personalizados, p. ej.:
label_values(llm_gateway_input_tokens, llm_gateway_metadata_customer_id).webp)
El Protocolo de contexto modelo (MCP) de Anthropic, anunciado el 25 de noviembre de 2024, estandariza la forma en que los asistentes se conectan a las herramientas, las instrucciones y los recursos. El ecosistema se ha acelerado hasta 2025 con muchos servidores prediseñados (GitHub, Slack, Google Maps, Puppeteer, etc.).
TrueFoundry integra MCP de forma nativa:
Esto convierte a la puerta de enlace en el plano de control operativo para las cargas de trabajo de las agencias, ya que unifica las políticas, la autenticación, el enrutamiento y la visibilidad de extremo a extremo tanto en las llamadas de LLM como en las ejecuciones de herramientas.
A continuación se muestra una lista de verificación práctica. Cada métrica incluye lo que indica, cómo usarla y cómo TrueFoundry la muestra.
Un cambio rápido aumenta la verbosidad de la producción para los clientes empresariales. Síntomas: aumento de los tokens de producción, mayor latencia del p95 y gasto diario. Acción con TrueFoundry: los análisis muestran un aumento en la producción de tokens en el entorno de «producción de soporte» y un aumento de los costes en el modelo principal. Si comparas con un proveedor alternativo que ofrece menos TTFT y los tokens de salida son más baratos, cambias el 30% del tráfico a través de rutas basadas en el peso y pones una alerta que diga «coste por conversación».
A las 10:00 IST, las tasas de error subieron a 429 segundos. Acción con TrueFoundry: Los paneles de control de límite de velocidad confirman los aceleradores desde arriba. Las cadenas de respaldo entran en acción y el enrutamiento se orienta hacia un backend más saludable. Mantienes la experiencia de usuario estable y, posteriormente, ajustas las cuotas de tokens y los parámetros de retroceso.
Los usuarios informan que «la respuesta comienza rápido, pero luego se arrastra». Acción con TrueFoundry: El TTFT está bien, pero el ITL es elevado en el modelo principal. El enrutamiento basado en la latencia prefiere automáticamente a un proveedor con un mejor rendimiento de streaming; también se establece una alerta en la versión 95 de ITL.
El trabajo por lotes de un cliente acapara fichas y ralentiza a todos los demás. Acción con TrueFoundry: Los límites de tarifas de los clientes basados en tokens imponen un reparto justo y protegen los SLO; los análisis verifican los recuentos de utilización y rechazados para que puedas vender cuotas más altas.
Las aplicaciones LLM son sistemas dinámicos. Los modelos evolucionan, los proveedores cambian las cuotas y los precios, las incitaciones se transforman y el comportamiento de los usuarios sorprende. El AI Gateway es el lugar donde puedes observar, controlar y optimizar todo esto, si recopilas las señales correctas y las conviertes en acciones.
La puerta de enlace de IA de TrueFoundry le brinda ese centro de comando operativo. Captura la latencia (TTFT/ITL), los tokens, el costo y los errores con una sobrecarga reducida; aplica los límites de velocidad, el RBAC y las barreras de protección basados en los tokens; y proporciona visibilidad sobre el enrutamiento, el estado y las alternativas para que pueda mantener las experiencias rápidas, confiables y rentables. Con un análisis detallado de clientes y usuarios y una atribución de costes automatizada y actualizada, los equipos pueden pasar de la lucha contra incendios reactiva a la optimización proactiva.
Si está centralizando su pila de GenAI (o desentrañando una serie de integraciones únicas), comience por enrutar el tráfico a través de la puerta de enlace, active los paneles de control anteriores y configure algunas alertas alineadas con SLO. Obtendrá la visibilidad necesaria para realizar envíos más rápido, contener los costos y mantener a sus agentes y usuarios encantados.
La observabilidad en AI Gateway ayuda a rastrear el razonamiento complejo de varios pasos y las invocaciones de herramientas que, de otro modo, serían opacas. La monitorización de las rutas de ejecución de los agentes ayuda a detectar en tiempo real bucles infinitos, alucinaciones y un uso ineficiente de las herramientas. Esta visibilidad garantiza que los agentes autónomos sigan siendo confiables, predecibles y se ajusten al presupuesto mientras interactúan con diversos sistemas y API externos.
La observabilidad de las pasarelas de IA optimiza el rendimiento de la LLM al proporcionar un seguimiento en tiempo real de la latencia, el rendimiento y las tasas de error en los diferentes proveedores de modelos. Al recopilar métricas granulares, como el tiempo hasta el primer token (TTFT) y la latencia entre tokens (ITL), los equipos pueden identificar los cuellos de botella específicos en la cadena de inferencias. Esta información permite a los desarrolladores comparar las velocidades de los modelos de forma objetiva e implementar un enrutamiento inteligente para garantizar un rendimiento de alta velocidad para los usuarios finales.
La observabilidad de las pasarelas de IA reduce los costos al proporcionar una visibilidad granular del consumo de tokens en todos los modelos, equipos y usuarios. El seguimiento del gasto por solicitud y espacio de trabajo permite a los equipos identificar de forma inmediata las solicitudes descontroladas o los flujos de trabajo ineficientes. Estos datos respaldan estrategias automatizadas de ahorro de costes, como el almacenamiento en caché semántico, la limitación de velocidad basada en los tokens y el enrutamiento de las consultas a modelos más asequibles sin intervención manual.
La observabilidad de las pasarelas de IA respalda la auditoría de cumplimiento al mantener un registro centralizado e inmutable de cada solicitud y respuesta. Los sistemas modernos registran registros de auditoría detallados, incluidos los identificadores de usuario, las marcas de tiempo y los eventos que ocultan la información personal para proteger los datos confidenciales. Estos registros garantizan que las empresas cumplan con las normas reglamentarias, como el RGPD y el SOC 2, ya que proporcionan una transparencia total en cuanto a las interacciones entre modelos y, a menudo, mantienen toda la telemetría en el entorno de nube seguro de la organización.
TrueFoundry simplifica la gestión de la infraestructura de IA al unificar varios proveedores de modelos en un único plano de control mediante la observabilidad en las pasarelas de IA. TrueFoundry correlaciona la telemetría a nivel de solicitud con la utilización de la GPU y la CPU para optimizar la asignación de recursos y reducir el desperdicio. Este enfoque integrado permite a los equipos de la plataforma gestionar las implementaciones, el escalado y las políticas de seguridad en diversos entornos de forma nativa dentro de sus cuentas de AWS, GCP o Azure.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


