


July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En este artículo comparamos el rendimiento de Llama2-7b desde la perspectiva de la latencia, el costo y las solicitudes por segundo. Esto nos ayudará a evaluar si puede ser una buena opción en función de los requisitos empresariales. Tenga en cuenta que en este artículo no abordamos el rendimiento cualitativo; existen diferentes métodos para comparar los LLM que se pueden encontrar aquí.
En este blog, hemos comparado los Llama-2-7B modelo de Nous Research. Esta es una versión preentrenada de Llama-2 con 7 mil millones de parámetros.
Meta desarrolló y lanzó públicamente la familia Llama 2 de modelos lingüísticos grandes (LLM), una colección de modelos de texto generativo previamente entrenados y ajustados que varían en escala de 7 mil millones a 70 mil millones de parámetros.
Los factores clave que hemos analizado son los siguientes:
Tipo de GPU:
Longitud del mensaje:
Para la evaluación comparativa, hemos utilizado Locust, una herramienta de prueba de carga de código abierto. Locust funciona creando usuarios/trabajadores para que envíen solicitudes en paralelo. Al principio de cada prueba, podemos establecer el Número de usuarios y Tasa de aparición. Aquí el Número de usuarios significan el número máximo de usuarios que pueden generarse o ejecutarse simultáneamente, mientras que el Tasa de aparición significa cuántos usuarios se generarán por segundo.
En cada prueba de evaluación comparativa para una configuración de implementación, partimos de 1 usuario y siguió aumentando la Número de usuarios gradualmente hasta que vimos un aumento constante en el RPS. Durante la prueba, también trazamos el tiempos de respuesta (en ms) y número total de solicitudes por segundo.
En cada una de las 2 configuraciones de implementación, hemos utilizado el abrazo inferencia de generación de texto servidor modelo que tiene versión=0.9.4. Los siguientes son los parámetros que se pasan al inferencia de generación de texto imagen para diferentes configuraciones de modelos:
Latencia, RPS y costo
Calculamos la mejor latencia en función del envío de una sola solicitud a la vez. Para aumentar el rendimiento, enviamos las solicitudes de forma paralela al LLM. El rendimiento máximo se da cuando el modelo puede procesar las solicitudes de entrada sin un deterioro significativo de la latencia.
Tokens por segundo
Los LLM procesan los tokens de entrada y la generación de manera diferente; por lo tanto, hemos calculado la velocidad de procesamiento de los tokens de entrada y los tokens de salida de manera diferente.

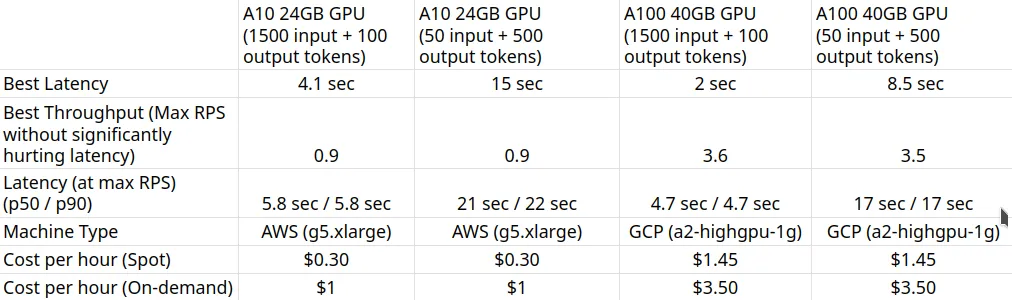
GPU A10 de 24 GB (1500 entradas + 100 tokens de salida)
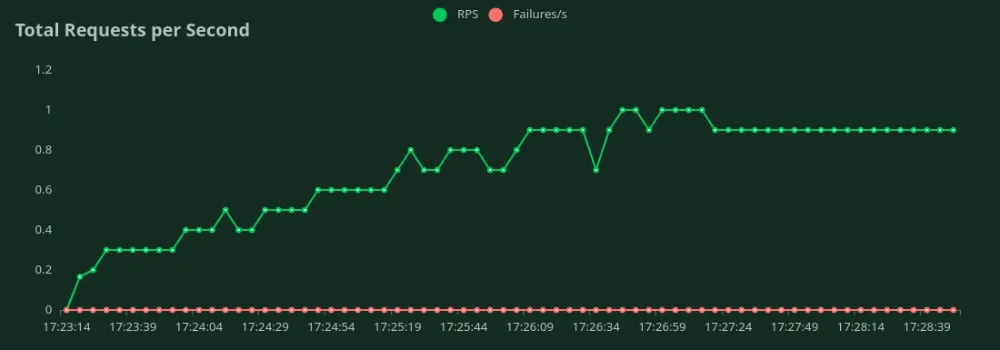
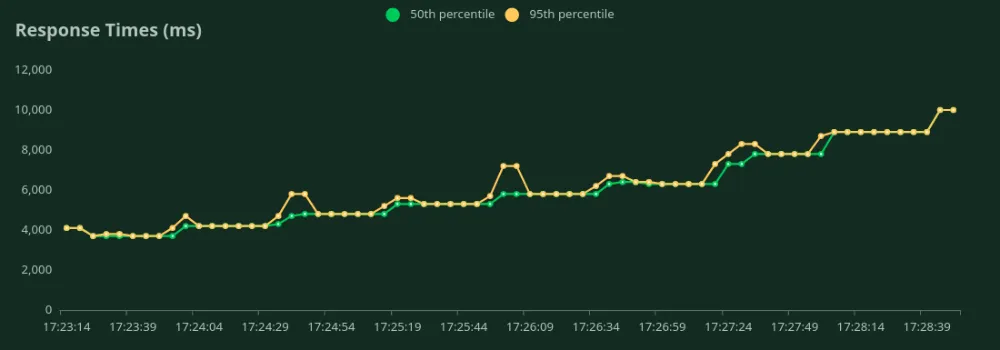
Podemos observar en los gráficos anteriores que Mejor tiempo de respuesta (con 1 usuario) es 4.1 segundos. Podemos aumentar la cantidad de usuarios para atraer más tráfico al modelo; podemos ver que el rendimiento aumenta hasta 0,9 RPS sin una caída significativa de la latencia. Más allá 0,9 RPS, la latencia aumenta drásticamente, lo que significa que las solicitudes están en cola.
GPU A10 de 24 GB (50 entradas y 500 tokens de salida)
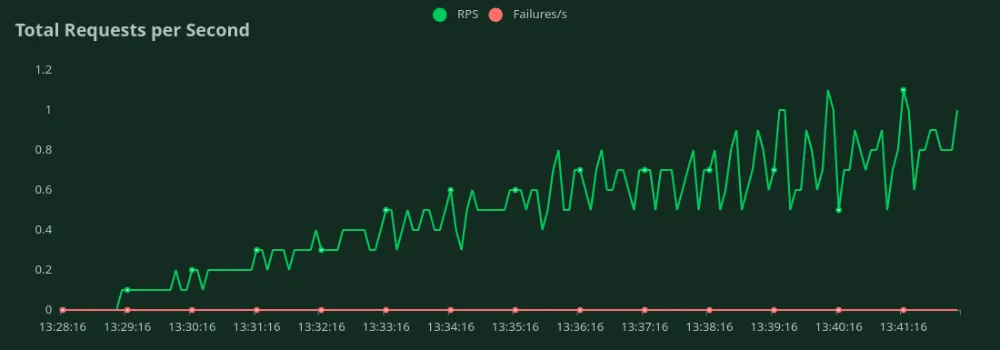
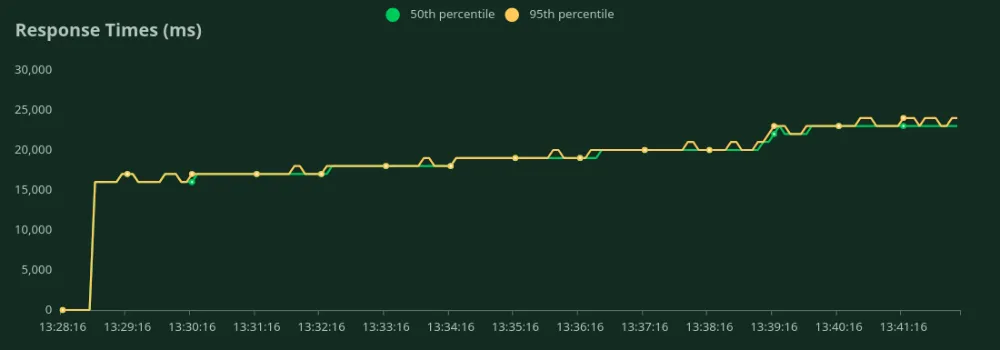
Podemos observar en los gráficos anteriores que Mejor tiempo de respuesta (con 1 usuario) es 15 segundos. Podemos aumentar la cantidad de usuarios para atraer más tráfico al modelo; podemos ver que el rendimiento aumenta hasta 0,9 RPS sin una caída significativa de la latencia. Más allá 0,9 RPS, la latencia aumenta drásticamente, lo que significa que las solicitudes están en cola.
GPU A100 de 40 GB (1500 entradas + 100 tokens de salida)
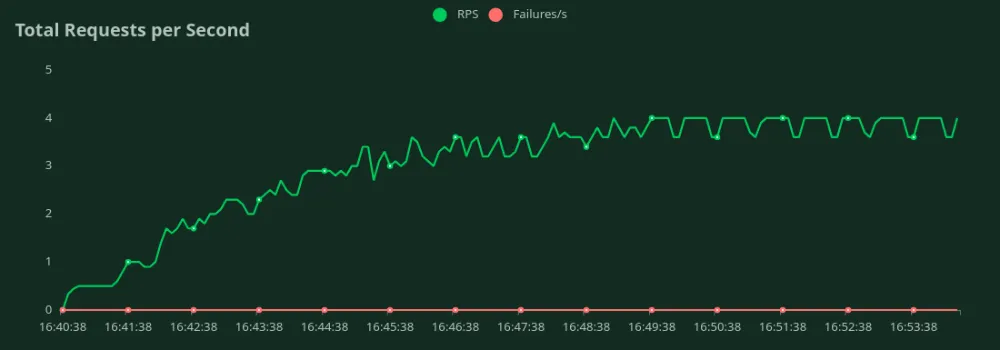
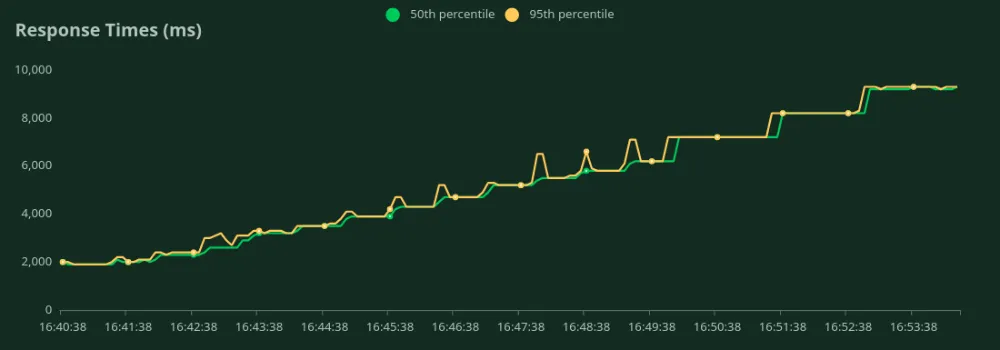
Podemos observar en los gráficos anteriores que Mejor tiempo de respuesta (con 1 usuario) es 2 segundos. Podemos aumentar la cantidad de usuarios para atraer más tráfico al modelo; podemos ver que el rendimiento aumenta hasta 3,6 RPS sin una caída significativa de la latencia. Más allá 3,6 RPS, la latencia aumenta drásticamente, lo que significa que las solicitudes están en cola.
GPU A100 de 40 GB (50 entradas y 500 tokens de salida)
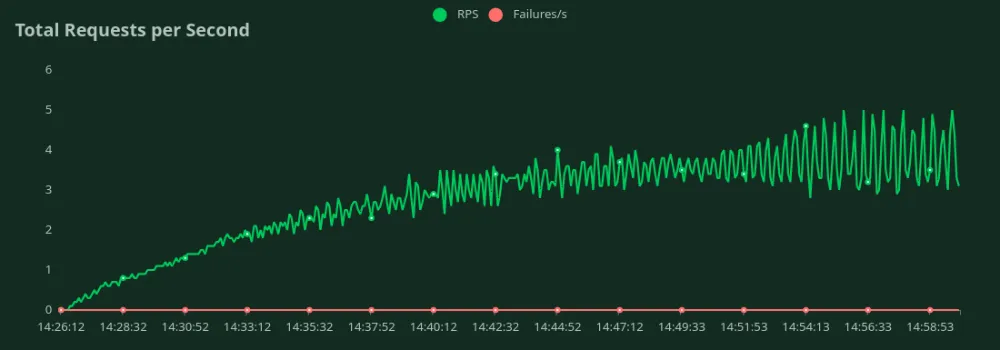
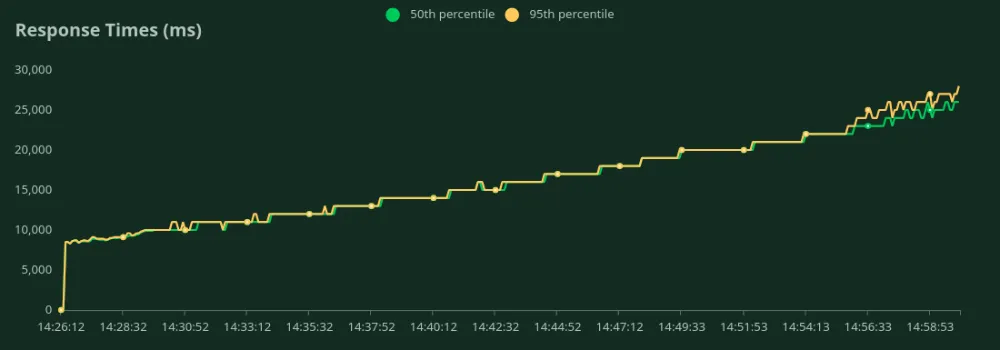
Podemos observar en los gráficos anteriores que Mejor tiempo de respuesta (con 1 usuario) es 8.5 segundos. Podemos aumentar la cantidad de usuarios para atraer más tráfico al modelo; podemos ver que el rendimiento aumenta hasta 3.5 RPS sin una caída significativa de la latencia. Más allá 3.5 RPS, la latencia aumenta drásticamente, lo que significa que las solicitudes están en cola.
Con suerte, esto le será útil para decidir si Llama7b se adapta a su caso de uso y a los costos en los que puede incurrir al hospedar Llama7B.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


