

July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Las GPU fraccionadas nos permiten asignar varias cargas de trabajo a una sola GPU, lo que puede resultar útil en los siguientes escenarios:
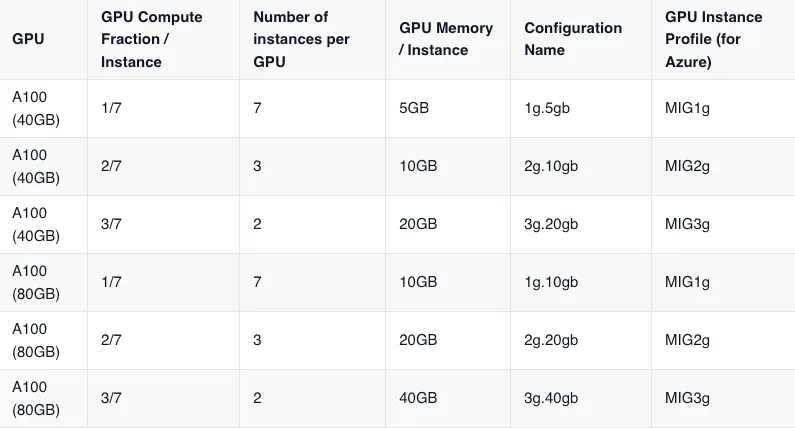
Para habilitar las GPU fraccionadas, tendremos que crear un grupo de nodos independiente de las GPU y no funcionará mediante el aprovisionamiento dinámico de nodos estándar en AWS /GCP. Para que Truefoundry pueda leer esos grupos de nodos, tenemos que asegurarnos de que la integración de la nube ya está hecha con Truefoundry.
Si aún no está activado, por favor sigue esta guía para habilitar la integración en la nube.
Una vez que se agrega la integración en la nube, debe «crear grupos de nodos» para las GPU compatibles con MIG o TimeSlicing. Esta configuración es diferente para los distintos proveedores de nube. Siga la guía que aparece a continuación para habilitar las GPU fraccionadas en su clúster.
Despliegues -> Helm -> tfy-gpu-operator.1. Crea un Nodepool con MIG habilitado usando el argumento --perfil de instancia de la GPU de la CLI de Azure. Este es un ejemplo de comando para hacer lo mismo:
como pregunta nodepool add\
<your cluster name>--nombre-clúster\
<your resource group>--grupo de recursos\
--sin espera\
--habilitar el escalador automático de clústeres\
--política de desalojo Eliminar\
--recuento de nodos 0\
--recuento máximo 20\
--recuento mínimo 1\
--node-osdisk-size 200\
--modo de escalado descendente Eliminar\
--tipo operativo Linux\
--node contiene «nvidia.com/gpu=presente:noschedule»\
--nombre a100mig7\
--estándar de tamaño de máquina virtual de nodo_NC24ADS_A100_v4\
--punto prioritario\
--os-sku Ubuntu\
--gpu-instance-profile MiG1G
2. Actualiza los grupos de nodos del clúster de Truefoundry.
3. Implemente su carga de trabajo seleccionando la GPU (con un recuento de 1) y seleccionando el grupo de nodos correcto.
Crea un grupo de nodos y pasa el mig_profile acelerador pasando gpu_partition_size=1 g.5 gb[O uno de los valores permitidos para el perfil MIG que puede encontrar en la parte superior de esta página]
Los grupos de nodos de contenedores de gcloud crean a100-40-mig-1g5gb\ INT ✘
<enter your project name>--proyecto=\
<enter your region>--región=\
<enter your cluster name here>--clúster=\
--tipo de máquina=a2-highgpu-1g\
--tipo de acelerador=nvidia-tesla-a100, número = 1, tamaño de partición de la gpu=1g.5gb\
--habilitar el escalado automático\
--número total de nodos mínimos 0\
--número máximo total de nodos 4\
--nodos mínimos de aprovisionamiento 0\
--números-nodos 0
No es trivial admitir actualmente las GPU MIG en AWS de forma gestionada, aunque si quieres probar la función -> Consulta estas documentos
complemento de dispositivo nvidia la configuración está correctamente configurada en operador tfy-gpu-gráfico.Helm -> tfy-gpu-operator, haga clic en editar y asegúrese de que las siguientes líneas estén presentes en el valoraoperador de GPU azure-aks-:
Plugin de dispositivo:
configuración:
datos:
todos: «»
cronometrado-10: |-
versión: v1
compartir:
Recorte de tiempo:
renameByDefault: verdadero
recursos:
- nombre: nvidia.com/gpu
réplicas: 10
nombre: time-slicing-config
crear: verdadero
predeterminado: todos
dispositivo-plugin.config apuntando a la configuración correcta de división de tiempo con la CLI de Azure. Este es un comando de ejemplo para hacer lo mismo.como pregunta nodepool add\
<your cluster name>--nombre-clúster\
<your resource group>--grupo de recursos\
--sin espera\
--habilitar el escalador automático de clústeres\
--política de desalojo Eliminar\
--recuento de nodos 0\
--recuento máximo 20\
--recuento mínimo 0\
--node-osdisk-size 200\
--modo de escalado descendente Eliminar\
--tipo operativo Linux\
--node contiene «nvidia.com/gpu=presente:noschedule»\
--nombre a100mig7\
--estándar de tamaño de máquina virtual de nodo_NC24ADS_A100_v4\
--punto prioritario\
--os-sku Ubuntu\
--labels nvidia.com/device-plugin.config=time-sliced-10
Los grupos de nodos de contenedores de gcloud crean un 100-40-frac-10\ ✔
--proyecto=tfy-devtest\
--región=EE. UU. Central1\
--cluster=tfy-gtl-b-us-central-1\
--tipo de máquina=a2-highgpu-1g\
--acelerador type=nvidia-tesla-a100, count=1, gpu-sharing-strategy=tiempo compartido, número máximo de clientes compartidos por gpu=10\
--habilitar el escalado automático\
--número total de nodos mínimos 0\
--número máximo total de nodos 4\
--nodos mínimos de aprovisionamiento 0\
--números-nodos 0
1. Asegúrese de que complemento de dispositivo nvidia la configuración está correctamente configurada en operador tfy-gpu-gráfico.
Ir a Helm -> tfy-gpu-operator, haga clic en editar y asegúrese de que las siguientes líneas estén presentes en el valora
operador de GPU aws-eks-:
Plugin de dispositivo:
configuración:
datos:
todos: «»
cronometrado-10: |-
versión: v1
compartir:
Recorte de tiempo:
renameByDefault: verdadero
recursos:
- nombre: nvidia.com/gpu
réplicas: 10
nombre: time-slicing-config
crear: verdadero
predeterminado: todos
2. Cree un grupo de nodos en AWS EKS con la siguiente etiqueta:
etiquetas:
«nvidia.com/device-plugin.config»: «10 veces segmentado»
Para usar GPU fraccionarias en tu servicio:
1. Asegúrese de haber agregado los grupos de nodos deseados.
2. Sincronice los grupos de nodos del clúster desde su cuenta en la nube yendo a Integraciones -> Clústeres -> Sincronización, como se muestra a continuación:

3. Puedes realizar la implementación con la interfaz de usuario de Truefoundry o con el SDK de Python.
Nota: El ajuste de escala automático de los grupos de nodos solo funcionará en GCP racimos. Tendrá que aumentar o reducir manualmente la escala de los grupos de nodos en Azure/AWS.
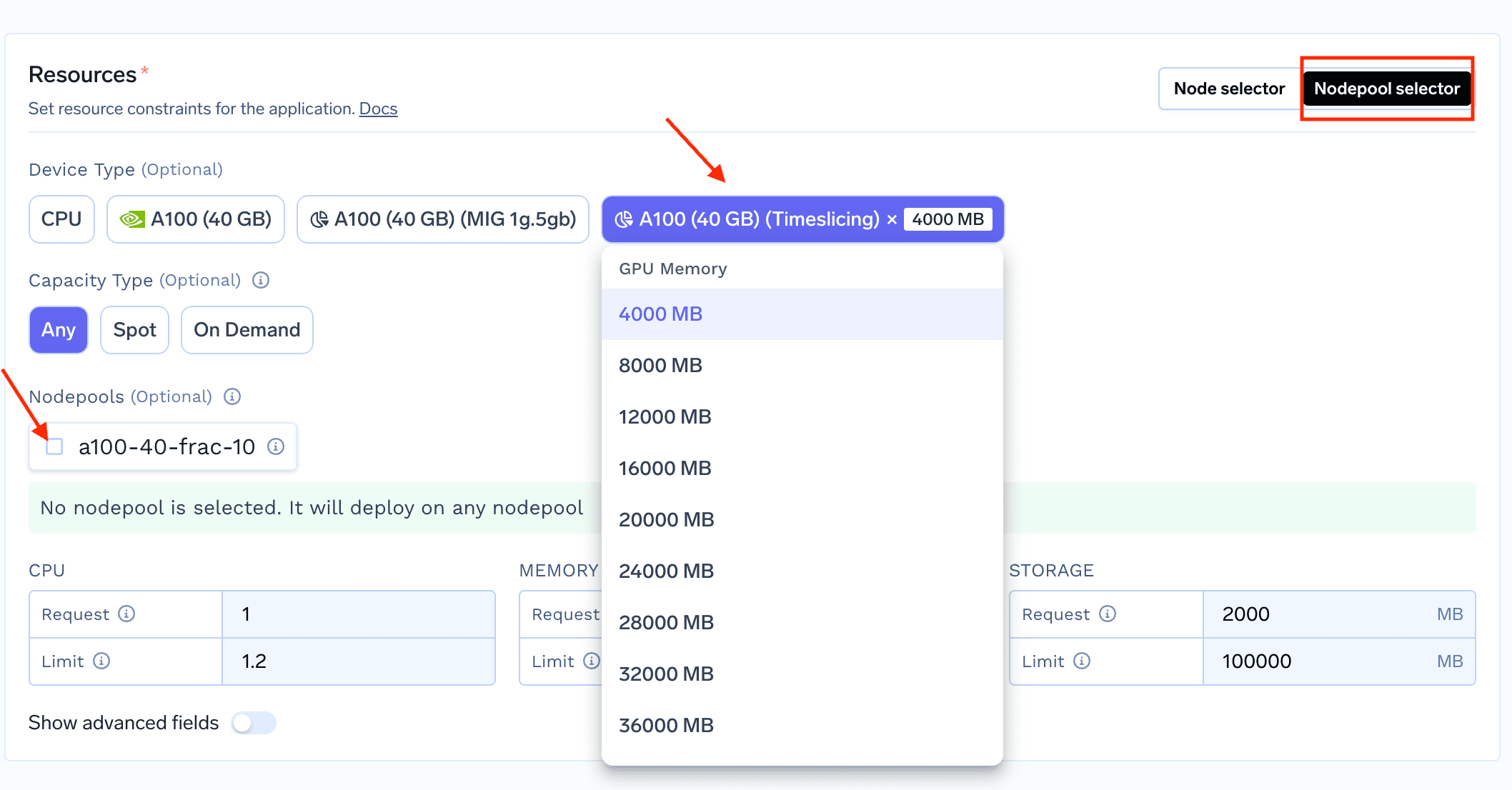
1. Para implementar una carga de trabajo que utilice una GPU fraccionada, comience a implementar su servicio/trabajo en truefoundry y, en la sección «Recursos», seleccione el selector de grupos de nodos
2. Una vez que hayas seleccionado el selector de nodos en la parte superior derecha de la sección Recursos, podrás ver las GPU fraccionadas en la interfaz de usuario que puedes seleccionar (como se muestra a continuación)

Puedes usar GPU fraccionarias con el SDK de Python con los siguientes cambios en el cambio de recursos:
1. Uso de GPU MIG
de servicefoundry import (
...
Servicio,
NVIDIA MigGPU,
Selector de grupos de nodos,
)
servicio = Servicio (
...
resources=Recursos (
...
node=nodePoolSelector (
<add your nodepool name>grupos de nodos = [» «],
),
dispositivos= [
NVIDIA MigGPU (perfil="1g.5gb»)
],
),
)
2. Uso de la GPU Timeslicing
de servicefoundry import (
Servicio,
GPU NVIDIA Time Slicing,
Selector de grupos de nodos,
)
servicio = Servicio (
...
resources=Recursos (
...
node=nodePoolSelector (
<add your nodepool name>grupos de nodos = [» «],
),
dispositivos= [
GPU NVIDIA TimeSlicing (gpu_memory=4000),
],
),
)
Estamos en True Foundry admiten GPU fraccionarias de una manera extremadamente simplificada.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


