

May 8, 2024
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
A medida que los grandes modelos lingüísticos pasan de la experimentación a la producción, los equipos se están replanteando la forma en que se debe gestionar, proteger y observar el tráfico de IA. Lo que antes parecía una simple integración de API, ahora implica solicitudes, tokens, enrutamiento de modelos, reintentos, seguimiento de costos y problemas de confiabilidad para los que la infraestructura de aplicaciones tradicional nunca se diseñó.
Muchos equipos de ingeniería comienzan este viaje ampliando las puertas de enlace de API conocidas, como Kong, aprovechando los patrones de enrutamiento, autenticación y limitación de velocidad existentes. A medida que crece el uso de la LLM, las pasarelas nativas de la IA, como Portkey entra en escena, ofreciendo abstracciones adaptadas a las indicaciones, los modelos y la observabilidad a nivel de fichas.
Ambos enfoques tienen como objetivo resolver problemas reales, pero provienen de puntos de partida fundamentalmente diferentes. Kong se basa en la gestión de microservicios y API HTTP, mientras que Portkey está diseñado específicamente para los flujos de trabajo de aplicaciones de LLM. Las diferencias entre estas filosofías se vuelven cada vez más importantes a medida que los sistemas de IA se expanden entre equipos, entornos y casos de uso de producción.
En este artículo, comparamos Kong y Portkey en cuanto a arquitectura, observabilidad, gobierno y preparación empresarial. Analizaremos dónde encaja mejor cada herramienta, dónde comienzan a aparecer limitaciones y qué plataformas deben considerar los equipos a medida que la IA se convierte en una parte fundamental de su infraestructura.
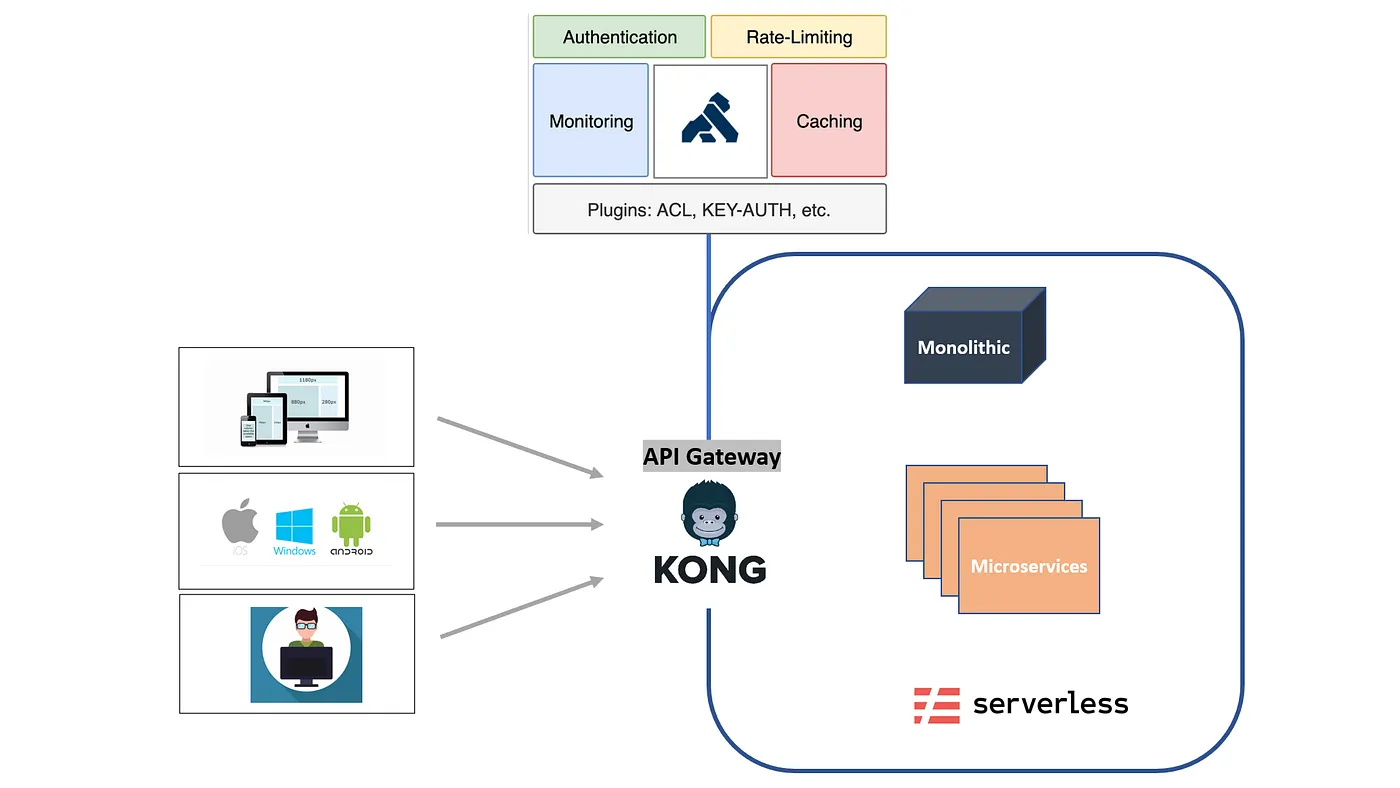
Kong es una puerta de enlace de API ampliamente adoptada creada para administrar, proteger y enrutar el tráfico HTTP entre microservicios. Se utiliza habitualmente como capa de entrada en las arquitecturas basadas en Kubernetes y es conocida por su capacidad de gestionar cuestiones como la autenticación, la limitación de velocidad, el enrutamiento del tráfico y la observabilidad a nivel de solicitud.
Desde un punto de vista arquitectónico, Kong está optimizado para Sistemas que priorizan las API. Sus abstracciones principales giran en torno a los puntos finales, los servicios, las rutas y los complementos, lo que la convierte en una opción perfecta para los entornos tradicionales de backend y microservicios, en los que las solicitudes no tienen estado, son predecibles y uniformes.
A medida que los equipos introducen los LLM, Kong suele ser el primera herramienta reutilizada para gestionar el tráfico de IA: tratar las llamadas de LLM como un punto final de API más. Esto funciona inicialmente para:
Sin embargo, el tráfico de LLM introduce propiedades que no se asignan claramente a las API tradicionales.
A medida que el uso de la IA va más allá de la simple experimentación, estas brechas se hacen cada vez más visibles, especialmente en entornos con varios equipos o sensibles a los costos.
Portkey es una puerta de enlace nativa de IA diseñada específicamente para aplicaciones basadas en modelos de lenguaje de gran tamaño. En lugar de tratar las llamadas de LLM como solicitudes de API genéricas, Portkey introduce abstracciones que se alinean con el funcionamiento real de las aplicaciones de IA: solicitudes, modelos, tokens y proveedores.
En esencia, Portkey actúa como una capa intermedia entre las aplicaciones de IA y varios proveedores de LLM. Permite a los desarrolladores cambiar de modelo, enrutar el tráfico y observar el uso sin vincular estrechamente el código de la aplicación a la API de un proveedor específico.
En comparación con las pasarelas de API como Kong, Portkey es Diseñado para ser compatible con LLM. Entiende que:
Esto convierte a Portkey en una opción sólida para los equipos que crean e iteran aplicaciones impulsadas por LLM, especialmente en entornos de producción en etapas iniciales o intermedias.
A medida que el uso de la LLM se expande en los equipos y entornos, surgen algunas limitaciones:
Estas restricciones se vuelven importantes cuando la IA pasa de ser una función de la aplicación a una capacidad empresarial compartida.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Mientras Kong y Portkey ambos pueden situarse frente a las cargas de trabajo de la IA, ya que se basan en suposiciones arquitectónicas muy diferentes. Comprender esta diferencia es fundamental para que los equipos de plataformas decidan cómo ampliar la IA más allá de una sola aplicación.
Kong es una buena elección si:
En esta configuración, Kong funciona como extensión temporal de la infraestructura API existente.
Portkey se adapta bien cuando:
Portkey brilla en el capa de aplicación, especialmente para los equipos de productos de IA que cambian rápidamente.
Ambos Kong y Portkey abordan los desafíos reales de la IA, pero lo hacen en capas diferentes y, en última instancia, limitadas. Estas limitaciones se hacen evidentes a medida que la IA pasa de ser una función única de la aplicación a una capacidad empresarial compartida abarcando varios equipos, entornos y límites reglamentarios.
Kong está diseñado para controlar las solicitudes de API, no el comportamiento de la IA. Las solicitudes, los tokens, la selección de modelos y la ejecución de los agentes son opacos para la puerta de enlace.
Portkey introduce controles compatibles con la LLM, pero la gobernanza se mantiene en gran medida ámbito de aplicación.
Sin embargo, los equipos de IA empresarial necesitan respuestas a preguntas como:
Ni Kong ni Portkey ofrecen gobernanza de la IA en toda la organización como una capacidad de primera clase.
Los costos de la IA se basan en una combinación de:
Kong no tiene visibilidad sobre estos factores de costes específicos de la IA.
Portkey expone las métricas a nivel de token, pero la atribución de costos se vuelve cada vez más difícil a medida que el uso abarca varios equipos, aplicaciones y entornos.
Sin la atribución a nivel de infraestructura, los equipos de plataforma y finanzas tienen dificultades para responder a una pregunta básica: ¿quién gasta qué y por qué?
Los sistemas de IA de producción exigen una separación estricta entre:
Kong no se creó teniendo en cuenta el aislamiento del entorno de IA.
Portkey optimiza los flujos de trabajo de las aplicaciones en lugar de imponer límites estrictos del entorno.
Para las empresas de sectores regulados, esta falta de aislamiento se convierte rápidamente en un obstáculo para la implementación.
Las implementaciones de IA empresarial deben cumplir requisitos como:
Estas restricciones deben cumplirse en la capa de infraestructura, no está integrado en el código de la aplicación ni es gestionado manualmente por los equipos.
Kong trata el tráfico de IA como solicitudes HTTP genéricas.
Portkey asume que el uso a nivel de aplicación es prioritario para la nube.
Ninguno de los enfoques está diseñado para despliegues de IA que priorizan el cumplimiento.
La IA en producción ya no se limita a las llamadas sincrónicas de respuesta rápida. Los sistemas del mundo real incluyen:
Las puertas de enlace que se centran únicamente en el tráfico de la API o en el enrutamiento rápido no controlan la ciclo de vida completo de las cargas de trabajo de IA.
A medida que la adopción de la IA madura, las empresas convergen en la misma conclusión: Las pasarelas por sí solas no son suficientes. La ejecución de la IA en producción requiere una capa de infraestructura que unifique acceso, implementación, observabilidad, gobernanza y cumplimiento. Esta es la razón por la que las organizaciones eventualmente van más allá de las pasarelas de API y las pasarelas de aplicaciones de LLM hacia Plataformas de infraestructura nativas de IA creadas para la escala empresarial
Las limitaciones de Kong y Portkey provienen de la misma causa raíz: ambos fueron diseñados para resolver problemas a nivel de puerta de enlace, no problemas de infraestructura de IA empresarial.
A medida que la IA se convierte en una capacidad compartida y crítica para la producción, las empresas necesitan algo más que enrutar el tráfico o abstraer rápidamente. Necesitan una plataforma que trate Gobernanza, despliegue, observabilidad y seguridad de la IA como problemas de infraestructura de primera clase. Aquí es donde True Foundry se distingue.
TrueFoundry se basa en la idea de que las cargas de trabajo de IA deben gestionarse como cualquier otro sistema de producción crítico, pero con Primitivas nativas de la IA. En lugar de operar solo en la ruta de solicitud, TrueFoundry funciona como plano de control de IA unificado.
A un alto nivel, TrueFoundry reúne:
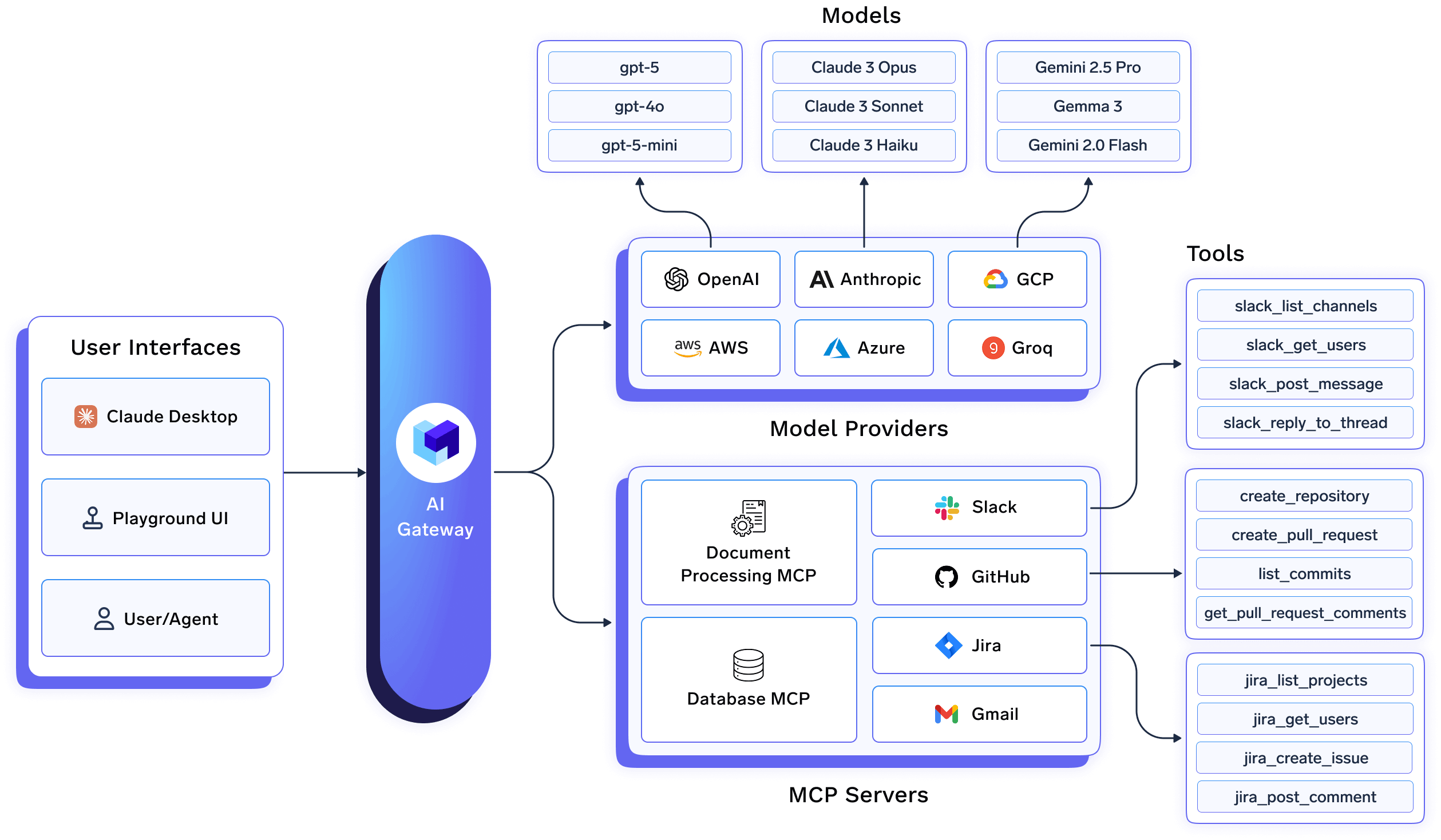
En muchas pilas de IA, el uso de la LLM se trata como un problema de integración de API: las solicitudes se enrutan, autentican y registran, pero todo lo que supera el límite de solicitudes se deja en manos de las aplicaciones individuales. TrueFoundry adopta un enfoque diferente al tratar las cargas de trabajo, los servicios, los trabajos y los agentes de la IA como objetos de infraestructura con límites de ciclo de vida, propiedad y operaciones.
En lugar de solo decidir ya sea se debe permitir una solicitud, controla TrueFoundry dónde se ejecutan los sistemas de IA, cómo se ejecutan y bajo qué restricciones, desde la implementación hasta el tiempo de ejecución. Este cambio del enrutamiento de solicitudes al control del ciclo de vida es lo que permite una gobernanza uniforme a medida que aumenta el uso de la IA.
Concretamente, esto se manifiesta en varias dimensiones críticas.
En arquitecturas centradas en pasarelas, políticas de acceso suelen estar integradas en el código de la aplicación, la configuración del SDK o las reglas de puerta de enlace por servicio. Esto se vuelve frágil rápidamente a medida que se multiplican los equipos, los servicios y los entornos.
TrueFoundry aplica las políticas de acceso y uso en nivel de espacio de trabajo y entorno. Los modelos, los agentes y las herramientas se aplican a entornos como el desarrollo, la puesta en escena y la producción, y los permisos y los controles se aplican de manera uniforme en todas las cargas de trabajo implementadas en ese entorno.
Porque las políticas están vinculadas a los entornos y no a las aplicaciones individuales:
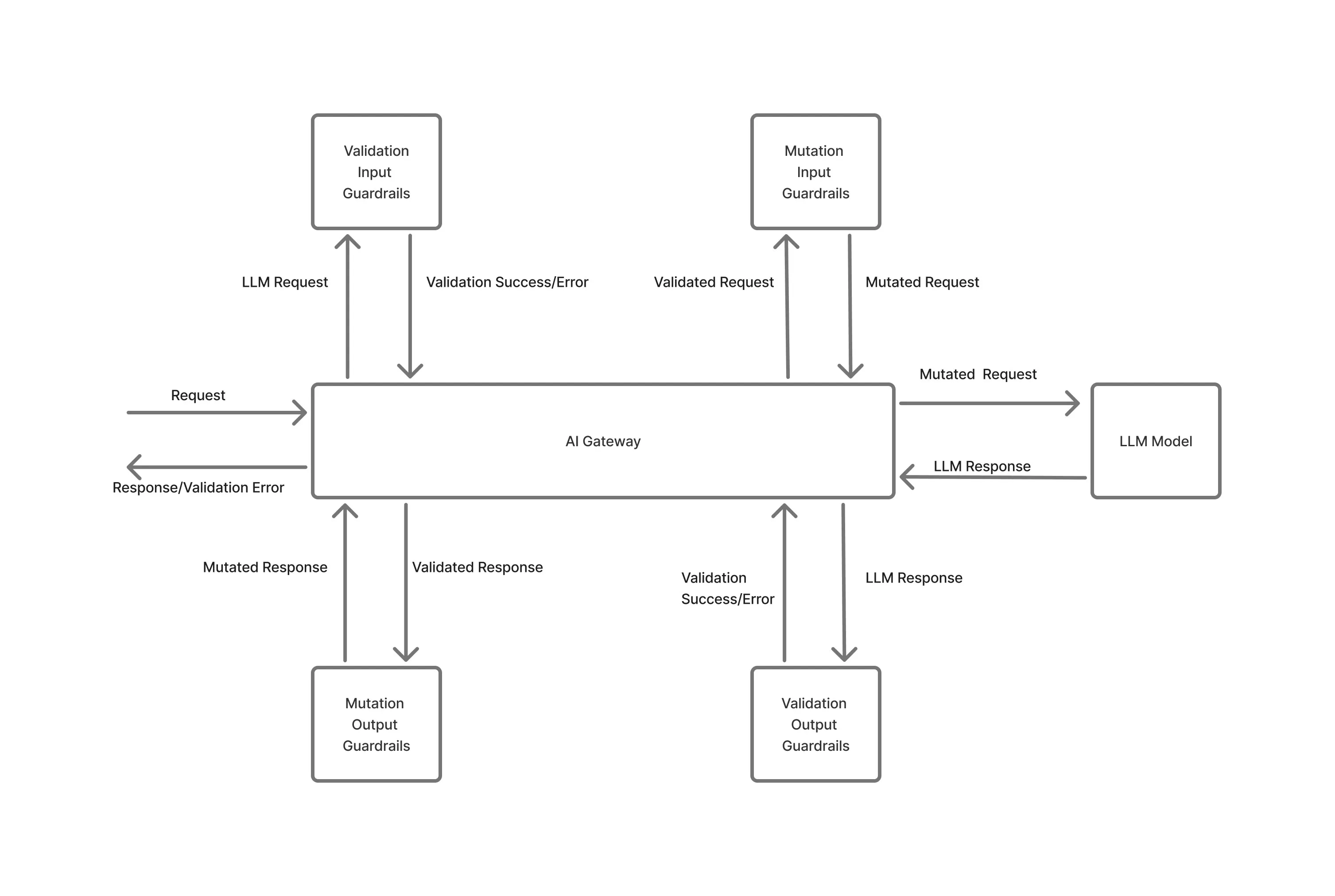
Los sistemas de IA fallan en la producción no porque una sola solicitud no sea válida, sino porque el uso se acumula de forma inesperada debido a picos de concurrencia, tormentas de reintentos o cargas de trabajo en segundo plano que se ejecutan a gran escala.
TrueFoundry impone el uso barandas en el momento de la ejecución, con visibilidad del comportamiento de las cargas de trabajo en tiempo de ejecución. Los límites de simultaneidad, las restricciones de rendimiento y los límites de uso se aplican de forma centralizada en todos los servicios y trabajos que comparten modelos o infraestructuras subyacentes.
Porque estos límites se aplican en la capa de plataforma:
Esto es fundamentalmente diferente de los controles del lado del cliente o del nivel del SDK, que asumen que las aplicaciones se comportan de forma correcta e independiente.
TrueFoundry impone el aislamiento en el capa de implementación y entorno, no solo previa solicitud de admisión. Los servicios de IA, los trabajos por lotes y los flujos de trabajo de los agentes se implementan como cargas de trabajo aisladas en entornos definidos, y el acceso, las políticas y los recursos se distribuyen por entorno.
Estas cargas de trabajo se ejecutan como despliegues y trabajos separados con procesos de ejecución y dominios de error independientes, en lugar de compartir un único contexto de ejecución plano detrás de una puerta de enlace. Como resultado:
Las puertas de enlace LLM a nivel de aplicación, que funcionan principalmente en la ruta de solicitud, no controlan la ejecución del tiempo de ejecución ni el estado de la infraestructura. Como resultado, no pueden ofrecer este nivel de despliegue y aislamiento del entorno, un problema que se hace cada vez más visible a medida que las cargas de trabajo de la IA se expanden entre los equipos y los entornos de producción.

Las métricas a nivel de token son útiles, pero insuficientes una vez que las cargas de trabajo de IA abarcan servicios de larga duración, trabajos en segundo plano y flujos de trabajo de agentes. En los sistemas de producción, el coste y el rendimiento se derivan de la interacción entre:
TrueFoundry correlaciona estas señales en la capa de plataforma, lo que permite a los equipos razonar sobre el comportamiento de la IA de la misma manera que lo hacen sobre otros sistemas de producción:por entorno, servicio y propietario, no mediante llamadas a la API individuales.
Muchas implementaciones de IA empresarial funcionan con restricciones que las pasarelas a nivel de aplicación asumen implícitamente, entre las que se incluyen:
El plano de control de TrueFoundry está diseñado para funcionar en todos estos modelos de implementación, lo que garantiza que la gobernanza, el aislamiento y la observabilidad permanezcan consistentes independientemente de dónde se ejecute la inferencia. Como resultado, las propiedades de cumplimiento, como los límites de los datos y la auditabilidad, se aplican como parte de la propia infraestructura, en lugar de añadirse más adelante mediante la lógica de las aplicaciones o los controles de procesos.
Tanto Kong como Portkey resuelven problemas importantes en diferentes etapas de la adopción de la IA. Kong amplía los patrones conocidos de pasarela de API al tráfico de IA, mientras que Portkey introduce abstracciones nativas de la LLM que facilitan la creación y el funcionamiento de aplicaciones impulsadas por la IA.
Sin embargo, a medida que la IA se convierte en una capacidad compartida y crítica para la producción, las empresas se enfrentan rápidamente a desafíos que van más allá del enrutamiento de solicitudes o la gestión rápida. La gobernanza, la atribución de costos, el aislamiento del entorno y el cumplimiento requieren controles a nivel de infraestructura, no solo en la puerta de enlace.
Esta es la razón por la que muchas organizaciones van más allá de las pasarelas de aplicaciones de API y LLM y optan por plataformas de infraestructura nativas de la IA, como True Foundry, que están diseñados para ejecutar, gobernar y escalar los sistemas de IA de manera confiable en todos los equipos y entornos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


